주요 개념
-
K-MEANS 알고리즘은 처음에 랜덤하게 클러스터 중심을 정하고 클러스터를 만듦, 클러스터의 중심을 이동하고 다시 클러스터를 만드는 식으로 반복해 최적의 클러스터를 구성함
-
클러스터 중심: K-MEANS 알고리즘이 만든 클러스터에 속한 샘플의 특성 평균값, centroid라고도 부름, 가장 가까운 클러스터 중심을 샘플의 또 다른 특성으로 사용하거나 새로운 샘플에 대한 예측으로 활용
-
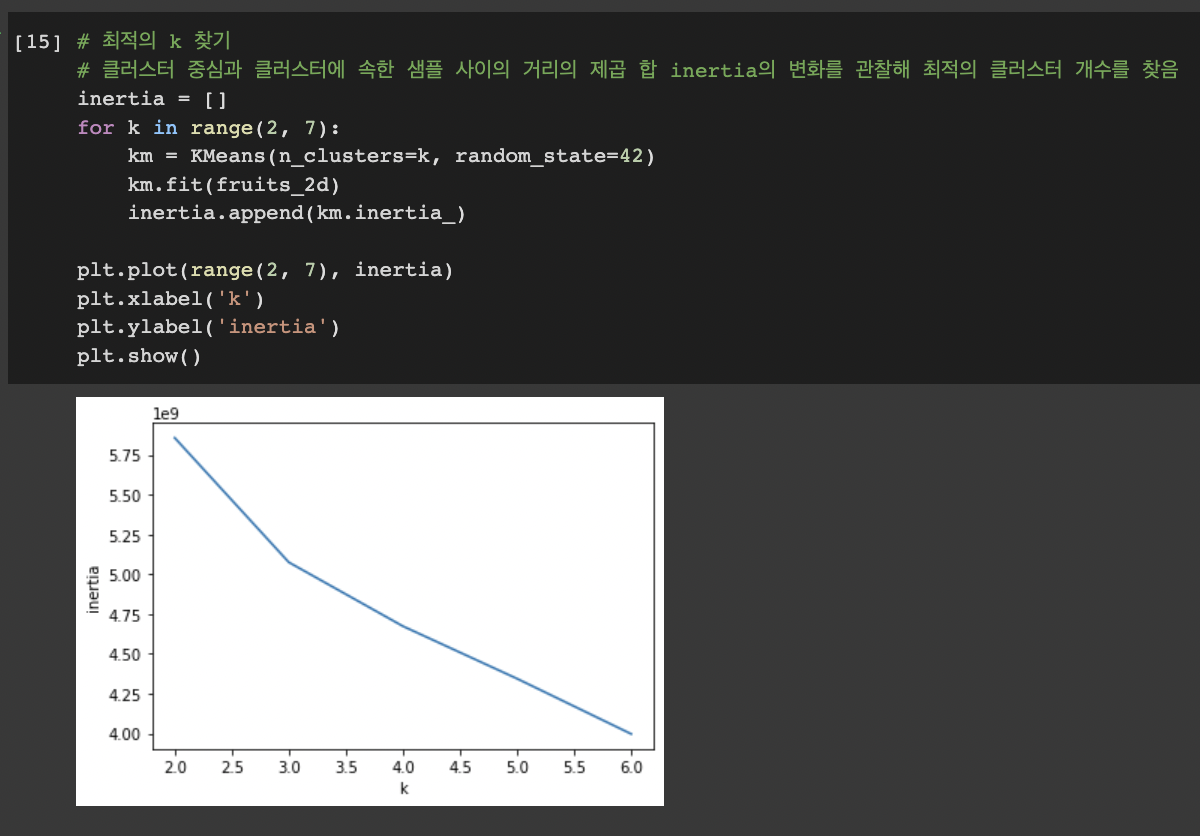
엘보우 방법: 최적의 클러스터 개수를 정하는 방법, 클러스터 개수에 따라 이너셔(클러스터 중심과 샘플 사이 거리의 제곱 합)감소가 꺾이는 지점이 적절한 클러스터 개수
K-Means
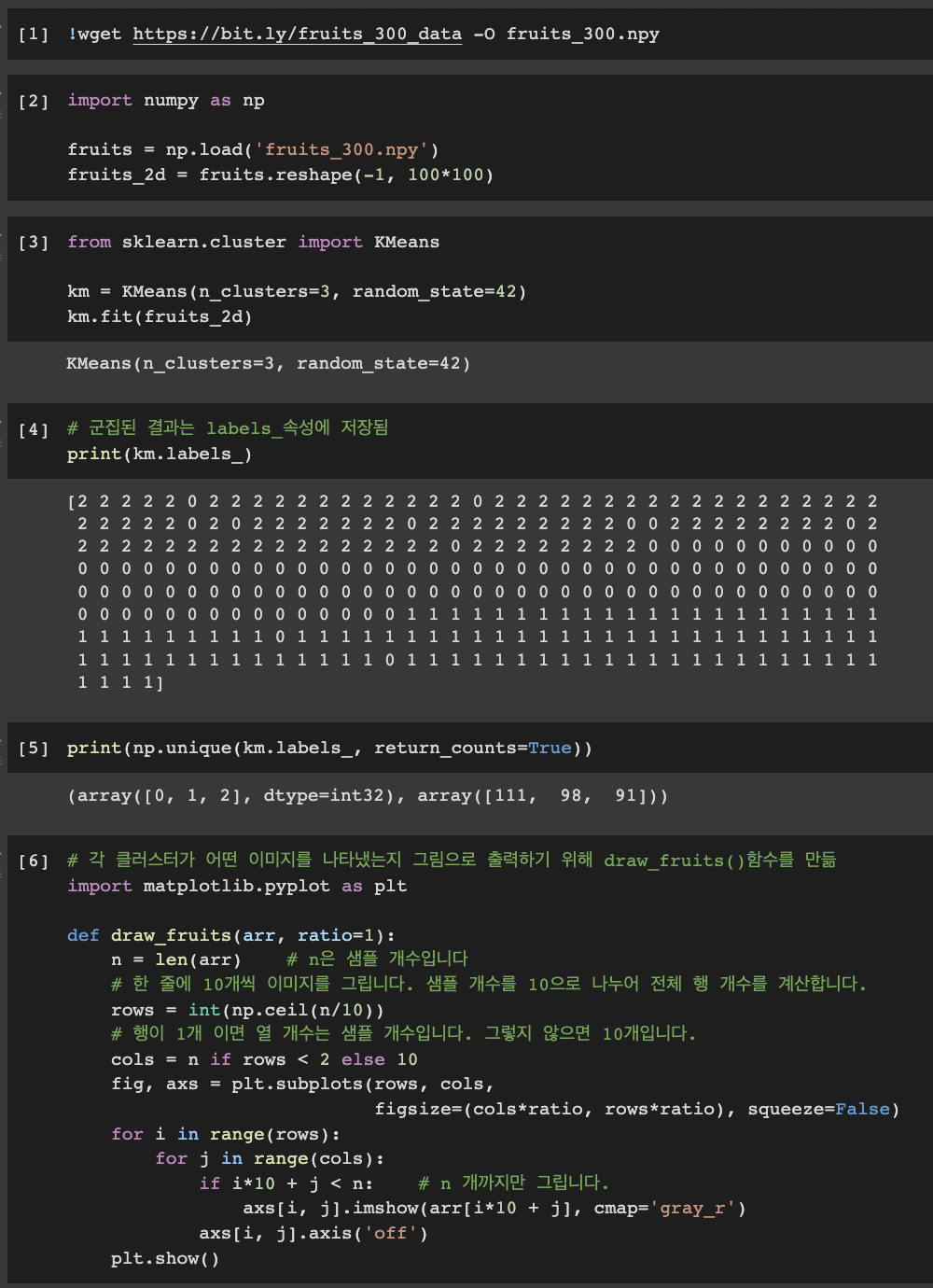
- 과일사진 그리기
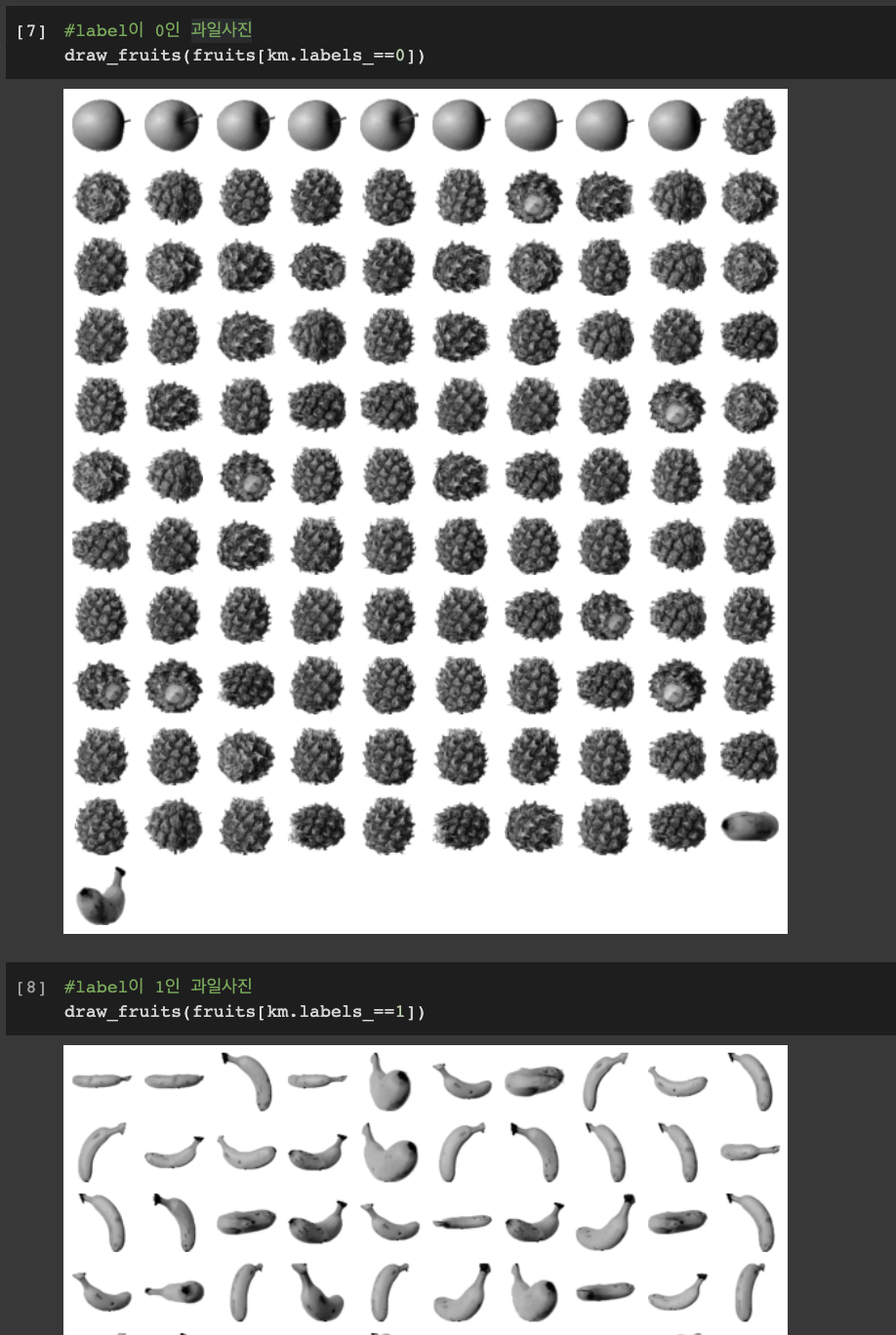
- KMeans 클래스의 클러스터 중심은 clustercenters 속성에 저장되어 있음
- 최적의 k 찾기
- 클러스터 중심과 클러스터에 속한 샘플 사이의 거리의 제곱 합 inertia의 변화를 관찰해 최적의 클러스터 개수를 찾음
colab 링크: https://colab.research.google.com/drive/109-P3ixCofMXRTfIZvkSoZOmXP-RV6cR?usp=sharing
참고: 혼자 공부하는 머신러닝+딥러닝
