Prologue
나는 회사에서 웹 개발자로 일하고 있고 웹개발을 주력으로 하고 싶지만, 인원수가 15명 밖에 안되는 작은 회사에서 근무하기 때문에 가끔은 하기 싫은 일도 해야 한다. 우리 회사는 인공지능과 빅데이터를 전문으로 하는 회사이기 때문에, 당연히 인공지능과 빅데이터 일이 많다. 이번에 문서 유사도 측정기를 구현해보라는 주문을 받아서 간단한 문서 유사도 측정기를 만드는 시행착오를 기록해보려 한다.
1. 기본적인 설계 예상도 만들어보기
먼저, 다른 사람들은 문서 유사도를 어떻게 계산하는지 많은 레퍼런스를 찾아봤습니다. 도움이 됐던 레퍼런스는
이정도가 있습니다. 아마 유사도를 측정하는 대표적인 방법으로는 코사인 유사도, 유클리드 거리, 자카드 유사도 정도가 있는 것 같습니다.
유사도를 측정하기 위해서는 단어나 문장을 벡터로 변환하는 과정을 먼저 거쳐야 합니다. 일단, 단어나 문장이 벡터로 변환되기 위해서는 미리 훈련된 임베딩 모델을 사용하거나 직접 모델을 훈련시켜서 단어나 문장을 벡터로 변환시켜야 합니다. 여기서 벡터란 어떠한 배열에 숫자값을 넣은 것이라고 보면 됩니다.
이를테면 [1, 2, 1, 2] 이런 것도 벡터입니다. 그니까, 이를테면 '사과'라는 문자열을 넣으면 모델은 [0, 1, 1, 1] 라는 벡터를 뱉을 수 있습니다. 벡터 내부에 있는 저 숫자들은 훈련된 데이터에 따라서 나름대로의 의미를 갖습니다. 내가 아는 한 비슷한 벡터를 갖는 단어는 비슷한 의미를 갖는 것으로 압니다.
저는 임베딩 모델을 훈련시키기에는 컴퓨팅 자원도 없고 하는 방법도 자세히 몰라서 남들이 훈련시켜놓은 임베딩 모델을 사용하려고 생각하고 있습니다. 그렇게 남들이 훈련시켜놓은 임베딩 모델을 pretrained-word-embeddings라고 합니다.
아무튼 일단 단어를 벡터로 변환하면 그 각각의 단어들은 의미론적인 관점에서 수학적 계산이 가능합니다. 이를테면 특정한 공식을 이용하여 비슷한 단어를 찾거나 서로의 유사도를 알아보거나 하는 등의 일도 가능해집니다.
수학적 계산이 가능해지면 위에 언급했던 코사인 유사도, 유클리드 거리, 자카드 유사도 등의 방법을 이용하여 유사도를 계산할 수 있습니다.
일단 각 유사도 계산 방법이 어떠한 이론을 바탕으로 하는 것인지 알고 넘어가봅시다.
유클리드 거리
유클리드 거리는 가장 간단한 유사도 측정 방법입니다. 벡터란 다차원 공간에 속한 한 점으로 볼 수 있습니다. 이를테면 평면 공간에 [2, 3] 이란 벡터값이 있다면, x축과 y축이 존재하는 그래프상에서 x=2, y=3 이란 위치에 존재하는 점을 의미할 수 있습니다. 만일 [-1, 1] 이라는 벡터 값이 있다고 또 가정하면 x=-1, y=1이란 위치에 존재하는 점일 수 있습니다.
유클리드 거리는 그러한 벡터의 거리를 측정하는데 사용되는 계산식입니다.
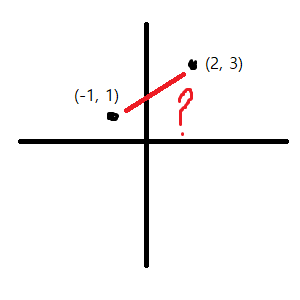
위 두 점의 거리를 계산한다고하면, 유클리드 거리의 공식은 다음과 같습니다. 루트를 씌우고 안에 있는 결과 값을 제곱을 하는 이유는 거리인데, 음수가 나오지 않게 하기 위해서입니다.
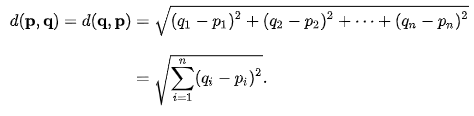
위는 2차원 평면을 기준으로 계산하기 때문에, p1, q1, p2, q2가 존재합니다. n차원이 되면 n개의 p와 n개의 q가 존재할 것입니다. 그래서 위에 그림판으로 그린 경우를 계산해보면, 3.60555 정도가 결과로 나오게 됩니다. 이를 이용해 벡터로 변환된 문서 또는 단어의 거리를 측정할 수 있습니다.
자카드 유사도
자카드 유사도는 매우 간단한 계산식입니다. 두 개의 문장에서 단어의 합집합의 개수를 구하고 교집합의 개수를 구해서 교집합의 개수 / 합집합의 개수를 하면 됩니다.
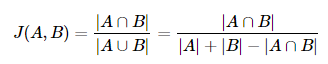
[출처: 딥러닝을 이용한 자연어처리 입문]
코사인 유사도
우리는 평면상에서 벡터의 코사인 값을 알아내서 벡터의 방향을 알 수 있습니다. 이 방향으로 우리는 유사한 단어나 문장이 어떤 것인지 판단할 수 있는데 먼저, 비교하고 싶은 단어나 문장 2개를 선택하여 각각을 먼저 벡터로 변환합니다. 그리고 그 벡터의 코사인 값을 알아냅니다. 그리고 코사인을 기준으로 두 벡터의 방향을 비교하여, 그 방향이 같으면 1, 다르면 -1, 90도의 각을 이루면(직교하면) 0의 값을 갖습니다.
대략적인 그림과 식은 아래와 같이 나옵니다.
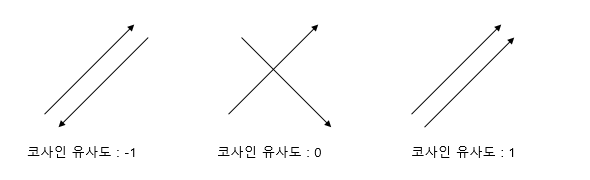
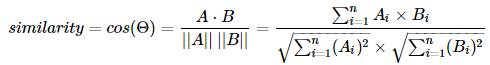
[출처: 딥러닝을 이용한 자연어처리 입문]
일단은 여기까지...
