엘라스틱서치로 문서 유사도 검색 구현하기
Prologue
나는 회사에서 웹 개발자로 일하고 있고 웹개발을 주력으로 하고 싶지만, 인원수가 15명 밖에 안되는 작은 회사에서 근무하기 때문에 가끔은 하기 싫은 일도 해야 한다. 우리 회사는 인공지능과 빅데이터를 전문으로 하는 회사이기 때문에, 당연히 인공지능과 빅데이터 일이 많다. 이번에 문서 유사도 측정기를 구현해보라는 주문을 받아서 간단한 문서 유사도 측정기를 만드는 시행착오를 기록해보려 한다.
내가 해야할 작업들 생각해보기
엘라스틱서치 세팅 관련
- 개발서버에 엘라스틱서치 최신 버전 설치
- 엘라스틱서치에서 논문 데이터 export하여 옮겨오기
엘라스틱서치 벡터 임베딩 관련
- 입력된 논문을 순회하며 형태소 분석하여 TF-IDF 데이터를 만듭니다.
- 만들어진 TF-IDF 데이터를 이용하여 논문 내용을 형태소분석하고 중요한 단어들을 빼옵니다.
- 논문 데이터의 중요한 단어들이 임베딩 모델을 거쳐 벡터 값을 생성합니다.
- 이 벡터값을 dense_vector type의 필드에 저장합니다.
엘라스틱서치 검색 시 프로세스 관련
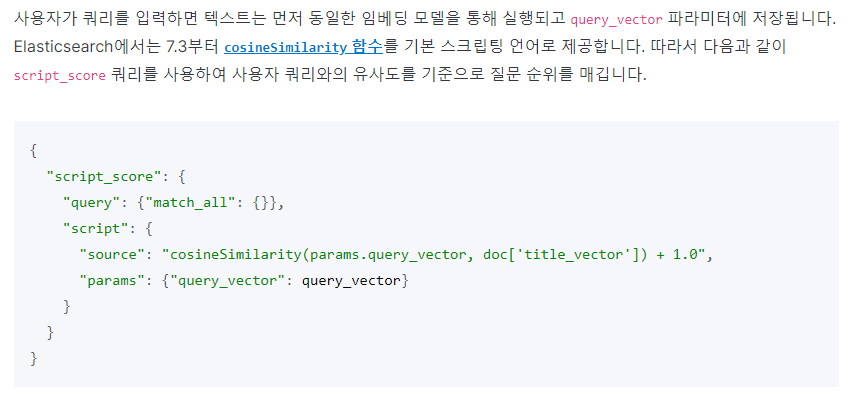
- 질의문이 들어오면 동일한 임베딩 모델을 거쳐서 벡터값을 생성합니다.
- 응답을 유사도에 따라 정렬하기 위해서 벡터 유사도를 계산합니다. (엘라스틱서치에서 제공하는 cosine similarity function을 사용)
- 검색 스코어링에 벡터 유사도의 결과값을 스코어로 지정해서 문장 임베딩에 의해서 "의미가 유사한" 문서들이 높은 스코어를 가지게 합니다.
(엘라스틱서치의 script_score query를 사용)
개발하기
1. 엘라스틱서치 세팅 관련 작업 수행하기
이 부분은 사실 제가 하지 않았습니다.. 회사에 있더라구요..
그저 엘라스틱서치의 POST _reindex 기능을 이용하여 개발용 인덱스를 하나 복사했습니다.
새 인덱스의 이름은 'korean_thesis'로 하였습니다.
그런데...
데이터가 너무 많아서 1000개만 다시 리인덱싱했습니다.
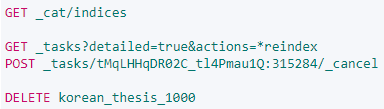
위와 같은 쿼리를 입력하여 진행중인 엘라스틱서치의 리인덱싱 테스크를 죽일 수 있고, 다시 인덱싱하면 됩니다.

위와 같이 인덱싱하면 1000개의 문서만 넘어갑니다.
2. 파이썬 Elasticsearch 모듈에 익숙해지기
파이썬에서 Elasticsearch에 접근해보는 것이 처음이라 이것저것 삽질을 좀 했습니다.
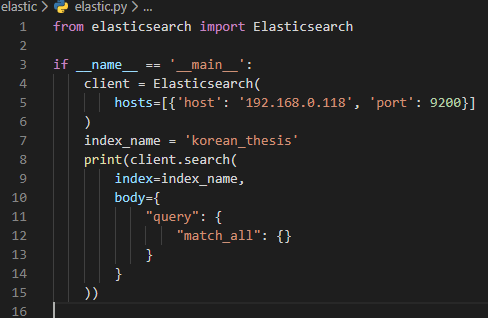
위의 폼이 기본 폼입니다.
client를 생성하면서 호스트의 정보를 입력해주고, 데이터 검색 시에는 search 메소드의 아규먼트에 인덱스 이름, 쿼리 내용을 위와 같은 형식으로 입력하면 됩니다.
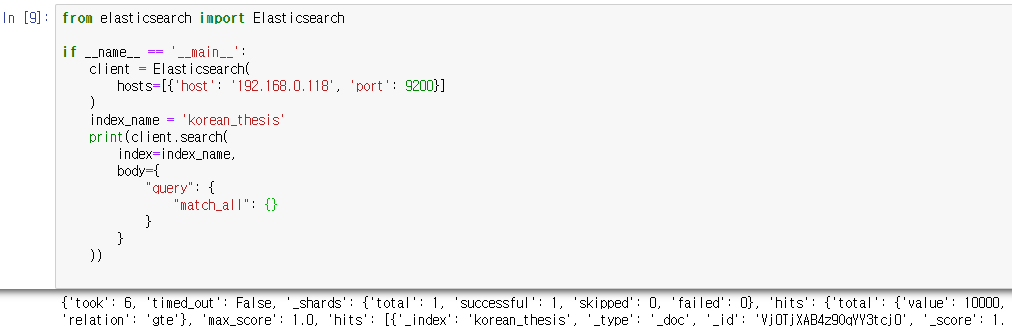
수행하면 위와 같이, 쿼리에 대한 결과가 프린트됩니다.
3. TF-IDF로 중요 단어 뽑아내기
먼저 DF 사전을 만듭시다.

DF사전을 만들면 위와 같이 중요한 단어 (모든 문서에 존재하지는 않는 단어) 를 알 수 있습니다.
3.1. 엘라스틱서치 데이터 순차적으로 가져오기
DF사전을 만드려면, 엘라스틱서치에 있는 모든 데이터를 파이썬으로 가져와야 합니다. 매우 큰 데이터의 경우에는 메모리에 올리기 힘드니 pickle과 같은 형식의 파일로 하드에 보관하는 것이 좋습니다. 하지만 이번 경우에는 1000개의 문서만 작업할 것이므로 메모리 내에서 충분히 작업이 가능할 것입니다.
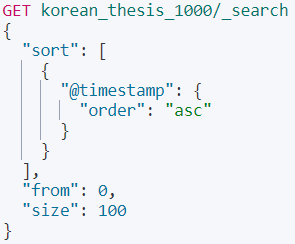
쿼리는 위와 같이 나왔습니다. @timestamp(입력된 시간)를 기준으로 100개씩 불러옵니다. 위는 키바나에서 테스트하기 위해 작성한 쿼리입니다. 이 내용을 파이썬으로 옮겨줍시다.
3.2. 파이썬 소스코드에서 엘라스틱서치 데이터 접근하기
엘라스틱서치 쿼리를 작성했으니, 이제 파이썬 소스코드에서 엘라스틱서치 데이터를 접근하면 됩니다.
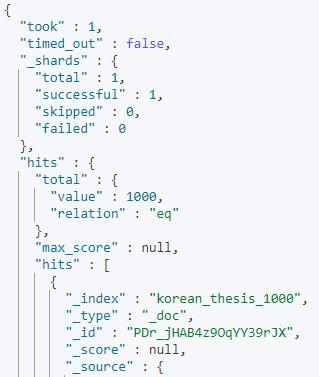
엘라스틱서치 결과에 '잘' 접근하려면 엘라스틱서치 결과 구조에 대한 이해가 약간 필요합니다.
엘라스틱서치 쿼리 결과는 기본적으로 아래와 같은 구성의 json을 리턴합니다.
{
main // 몇 개의 샤드에서 데이터가 불러와졌는지, 샤드별 성공 실패 여부
{
hits1 // 데이터(document)를 몇개 불러왔는지
{
hits2 // 데이터(document)의 내용이 들어있는 배열
}
}
}아래는 엘라스틱서치 공식 사이트에서 발췌한 설명입니다.

3.3. 엘라스틱서치 데이터 이용해서 IDF List 만들어보기

제 소스코드는 위와 같이 나왔습니다. contents라는 필드에 정보가 있기 때문에 저렇게 접근하였습니다.
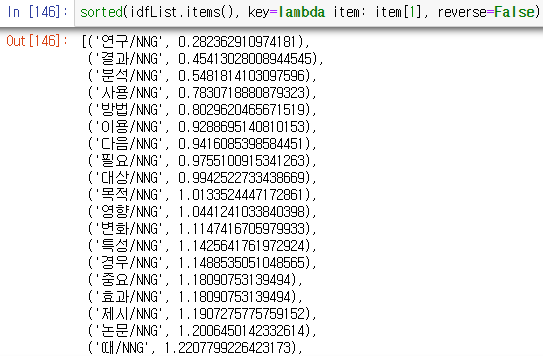
위는 idf list의 결과입니다. 연구, 결과, 분석, 사용, 방법 등 논문의 토픽을 알기엔 적합치 않은 단어들이 나열되어 있습니다.
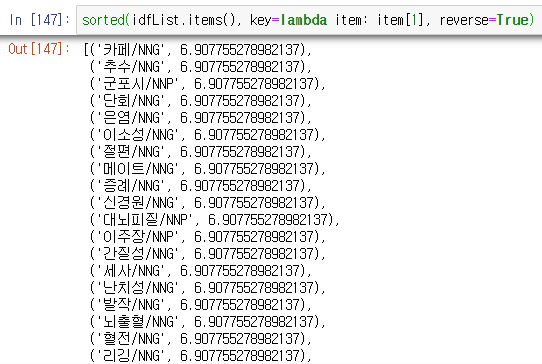
위는 idf가 높은 단어들을 순서대로 출력한 것입니다. 아마, 논문에서 단 한번만 나왔던 단어일 확률이 큽니다.
3.4. 논문 데이터로 중요 단어 뽑아보기

첫번째 문서에 대해서 중요한 단어가 어떻게 나왔는지 테스트 해보았습니다.
뽑힌 단어를 살펴보면, 단회, 학급, 상담, 집단, 맞벌이, 단위, 지지, 스트레스, 청소년, 응집, 프로그램 등이 보입니다.아마 청소년 상담 프로그램에 대한 논문일 것으로 보입니다.
대략 적절하게 나오는 것을 확인하였으니, 이제 벡터로 바꾸어줄 차례입니다.
3.5. 벡터 뽑고 테스트해보기
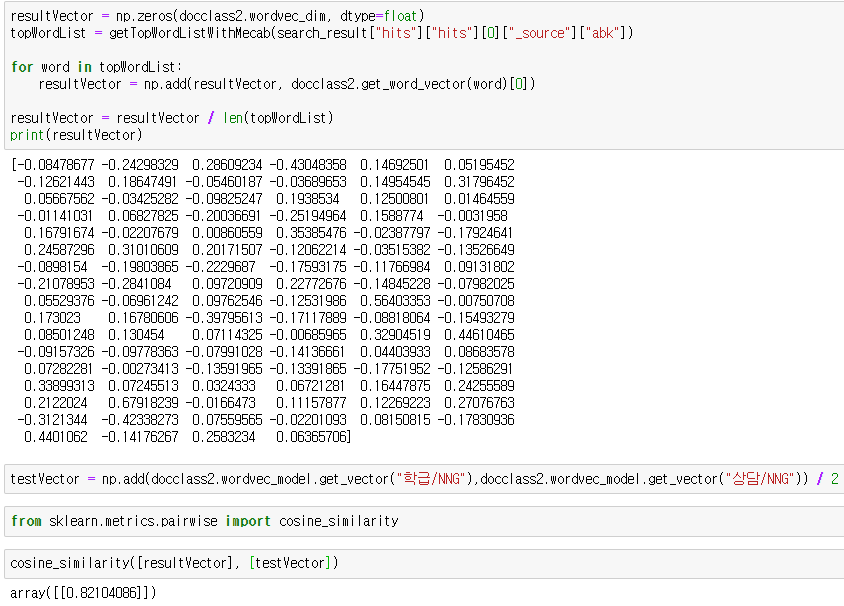
개발하면서 느끼는 건 언제나 테스트가 중요하다는 것입니다. 위의 코드는 제가 실제로 0번째 문서의 벡터를 추출하고 그 유사도를 구해본 것입니다. 학급과 상담에 대해서 82%의 유사도를 보이는 것을 볼 수 있습니다.
3.6. 엘라스틱서치 문서에 벡터값 등록하기
엘라스틱서치 문서에 벡터 값을 등록하려면, 먼저 필드 맵핑을 만들어야 합니다.
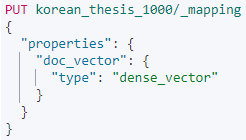
위는 기존에 존재하는 인덱스에 새로운 필드 맵핑을 추가하는 쿼리입니다.
맵핑을 추가했으면 거기에 벡터 값을 넣어야 하는데, 테스트용 쿼리 하나만 수행해본 뒤에 추가하도록 해봅시다.

위의 쿼리를 이용해서 프로그래밍하면 될 것 같습니다. 모든 도큐먼트에 벡터를 등록해주는 프로그램을 짜봅시다.
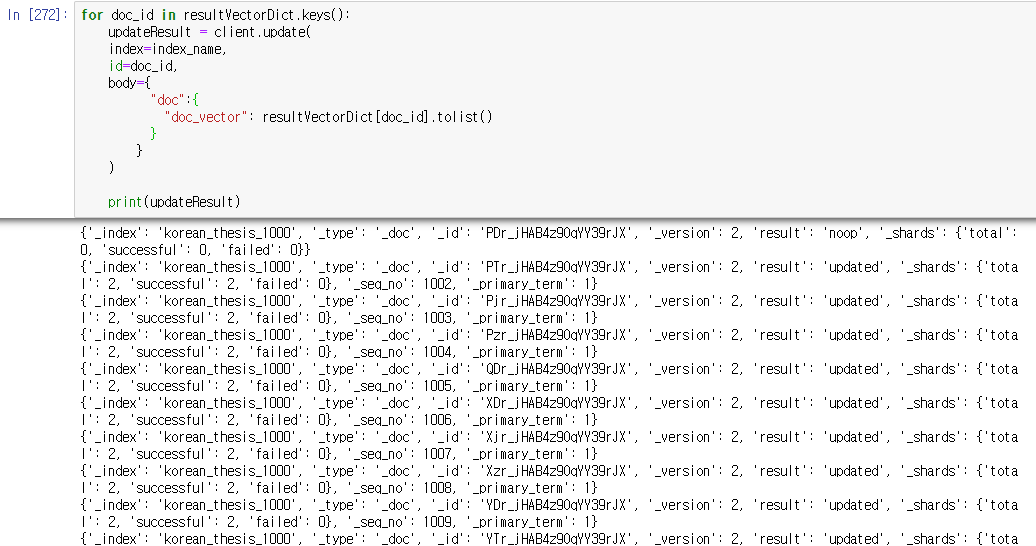
저는 resultVectorDict라는 곳에 도큐먼트 id와 벡터 값을 미리 저장해놓고, 그걸 엘라스틱서치로 옮겼습니다.
코사인 유사도를 이용하여 데이터 검색해보기
엘라스틱서치 7.3버전 이상으로 재설치하기
검색 수행 중 큰 이슈가 생겼습니다!!
바로 엘라스틱서치에서 코사인유사도를 구하는 함수를 사용하려면, 엘라스틱서치 버전이 7.3 이상 이어야 한다는 것!
저는 아래와 같이 7.0.0을 써서 다음과 같은 에러가 발생했습니다.


넘버 7.0.0 ......
그래서 엘라스틱서치를 재설치했습니다.
재설치 후에도 외부에서 접속이 안되는 등의 이슈가 발생했는데, 엘라스틱서치 설치 후에 간단한 설정이 필요합니다.
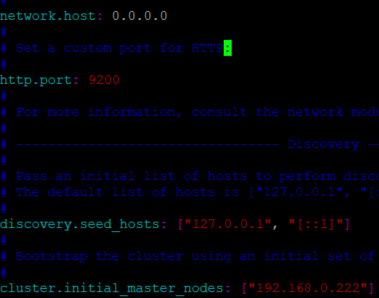
위와 같이
1. host를 0.0.0.0으로 설정해줍니다.
2. discovery에서 적어도 1개의 호스트는 검색될 수 있게 해줍니다. ["127.0.0.1", "[::1]"]
3. 초기 마스터 노드를 자신의 아이피로 설정해줍니다.
엘라스틱서치 내부 데이터 export 및 import 하기
export와 import를 쉽게 하기 위해서 저는 elasticdump 라는 npm 패키지를 이용했습니다.
elasticdump를 이용하면 매우 편하게 데이터를 옮길 수 있습니다.
저는 192.168.0.118 -> 192.168.0.222에 있는 서버로 데이터를 옮기는데
아래와 같은 명령어를 사용하였습니다.
elasticdump --input=http://192.168.0.118:9200/korean_thesis_1000 --output=http://192.168.0.222:9200/korean_thesis_1000 --type=analyzer
elasticdump --input=http://192.168.0.118:9200/korean_thesis_1000 --output=http://192.168.0.222:9200/korean_thesis_1000 --type=mapping
elasticdump --input=http://192.168.0.118:9200/korean_thesis_1000 --output=http://192.168.0.222:9200/korean_thesis_1000 --type=data하나의 벡터로 테스트해보기
먼저 아래와 같은 Query DSL로 테스트해보았습니다.
아래 벡터는 청소년 상담 관련 논문에서 나온 벡터를 복사 붙여넣기 한 것입니다.
{
"query": {
"script_score": {
"query": {
"match_all": {}
},
"script": {
"source": "cosineSimilarity(params.queryVector, doc['doc_vector'])",
"params": {
"queryVector": [-0.08478677, -0.24298329, 0.28609234, -0.43048358, 0.14692501,
0.05195452, -0.12621443, 0.18647491, -0.05460187, -0.03689653,
0.14954545, 0.31796452, 0.05667562, -0.03425282, -0.09825247,
0.1938534 , 0.12500801, 0.01464559, -0.01141031, 0.06827825,
-0.20036691, -0.25194964, 0.1588774 , -0.0031958 , 0.16791674,
-0.02207679, 0.00860559, 0.35385476, -0.02387797, -0.17924641,
0.24587296, 0.31010609, 0.20171507, -0.12062214, -0.03515382,
-0.13526649, -0.0898154 , -0.19803865, -0.2229687 , -0.17593175,
-0.11766984, 0.09131802, -0.21078953, -0.2841084 , 0.09720909,
0.22772676, -0.14845228, -0.07982025, 0.05529376, -0.06961242,
0.09762546, -0.12531986, 0.56403353, -0.00750708, 0.173023 ,
0.16780606, -0.39795613, -0.17117889, -0.08818064, -0.15493279,
0.08501248, 0.130454 , 0.07114325, -0.00685965, 0.32904519,
0.44610465, -0.09157326, -0.09778363, -0.07991028, -0.14136661,
0.04403933, 0.08683578, 0.07282281, -0.00273413, -0.13591965,
-0.13391865, -0.17751952, -0.12586291, 0.33899313, 0.07245513,
0.0324333 , 0.06721281, 0.16447875, 0.24255589, 0.2122024 ,
0.67918239, -0.0166473 , 0.11157877, 0.12269223, 0.27076763,
-0.3121344 , -0.42338273, 0.07559565, -0.02201093, 0.08150815,
-0.17830936, 0.4401062 , -0.14176267, 0.2583234 , 0.06365706]
}
}
}
}
}검색 결과를 보면,

위와 같이 title의 연관도가 상당히 양호한 것을 볼 수 있습니다.
파이썬 소스로 처리하기
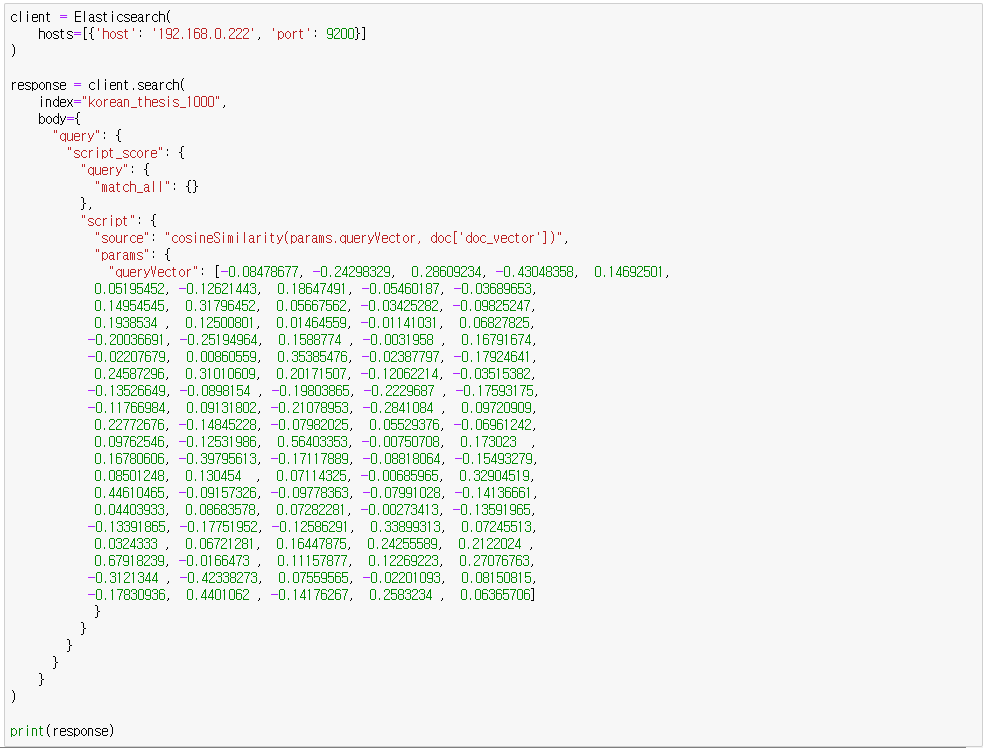
먼저, 테스트했던 쿼리를 소스에 그대로 넣으면 위와 같습니다.
위에서 문자를 받아서 벡터로 변환해주는 함수만 작성하면 됩니다.

위는 현재 idf사전에 없는 단어를 넣을 경우에 OOV 에러가 나서 키에러 처리를 해준 부분입니다.
나중에 또 실수할 것 같아서 기록합니다.

위가 최종 함수의 소스입니다.
queryToVec이 들어온 쿼리 내용을 벡터로 변경해주고, 변경된 벡터는 numpy형식이기 때문에 tolist를 해주는 것 외에는 위의 테스트용 소스 내용과 비슷합니다.
구현 테스팅 결과는 다음과 같습니다.
키워드 청소년 검색결과입니다.
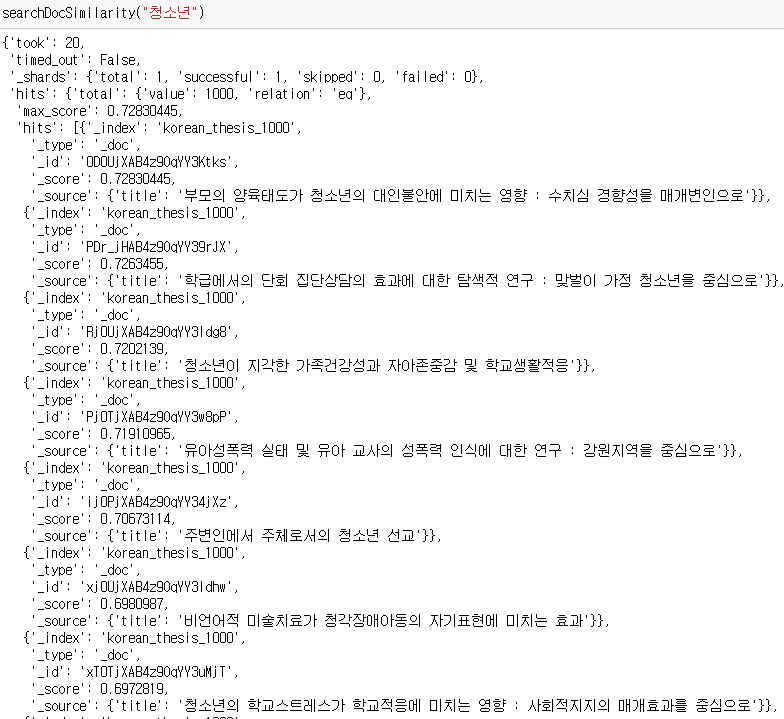
결과를 보시면 나름 괜찮은 것 같습니다.
이번엔 키워드 말고 논문의 요약 내용을 통째로 넣어보겠습니다.
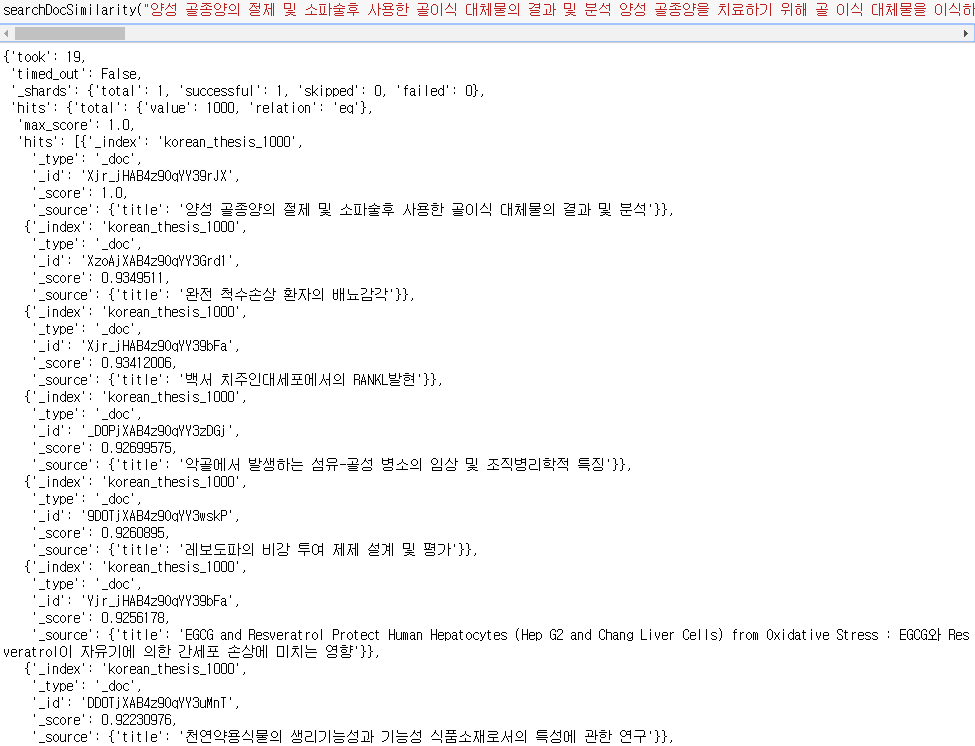
위는 양성 골종양 에 대한 문서를 통째로 넣었을 때의 결과입니다.
저는 양성 골종양이 뭔지 잘 몰라서 결과가 제대로 나온지는 모르겠으나 일단 의료쪽 문서들이 나오긴 했습니다.
끝까지 봐준 분이 있다면 감사합니다.
참고자료

7개의 댓글

오오.. 안녕하세요!
elasticsearch 관리만 해봤었다가, 이런거 엄두도 못냈는데,
한번 도전해볼만하게 단계단계 잘 정리해주셨네요..! 감사합니다.

안녕하세요. 글 재밌게 잘 보았습니다. 질문이 있는데요.
중간에 resultVector 부분에서 document embedding은 어떤 방식으로 진행하신 것인가요?
임베딩 모델을 거쳐 벡터값을 생성한다고 하셨는데, 어떤 임베딩 모델인지 궁금합니다.