지난 블로그 글인 ARCUS에서 데이터 영구 보존을 위한 Persistence 기능의 개요와 사용법에서 ARCUS 데이터 영속성을 소개드리고 telnet과 memtier_benchmark 도구로 ARCUS 인스턴스에 명령 요청하여 사용하는 것까지 보여드렸습니다. ARCUS 데이터 영속성 기능이 추가되더라도 기존 캐시와의 성능 차이가 크지 않도록 데이터 영속성 기능의 수행 오버헤드를 최소화하여 ARCUS의 기존 고성능을 보장하도록 구현하였다고 언급하였습니다. 이번 글에서는 ARCUS 데이터 영속성 기능의 성능을 기존 캐시 용도의 성능과 비교하면서, 명령 로깅 모드에 따른 성능 차이를 측정한 결과를 보여드리겠습니다.
- 성능 시험 환경
다음과 같이 시험 환경을 구축하여 ARCUS 영속성 성능을 측정하였습니다. - 성능 시험 장비 사양
ARCUS 캐시 노드가 구동되는 장비의 사양입니다. ARCUS 캐시 노드는 1개만 구동하였습니다.
OS : CentOS 7.3.1611
CPU : 8vCPU
MEMORY : 8GB 2
NETWORK : 1Gbps
DISK : HDD 50GB 2
ETC :
▪ THP(Transparent Huge Pages) = madvise
▪ vm.swapiness = 30
부하를 생성하는 클라이언트가 구동되는 장비의 사양입니다.
OS : CentOS 7.3.1611
CPU : 8vCPU
MEMORY : 8GB * 2
NETWORK : 1Gbps
DISK : SSD 50GB
ARCUS 서버 구동 옵션
ARCUS 캐시 노드는 arcus-memcached 1.13.1 버전을 사용하였고, 구동 명령어는 아래와 같습니다.
memcached -d -v -r -R 100 -t 6 -p 11500 -b 8192 -c 4096 -m 12000 \
-z localhost:2150 \
-X /home/test/arcus/lib/syslog_logger.so \
-E /home/test/arcus/lib/default_engine.so \
-e config_file=/home/test/arcus/conf/default_engine.conf클라이언트 부하를 고려하여 아래 구동 옵션을 적절히 설정해야 합니다.
t : 작업 스레드 개수
R : IO 이벤트에서 처리할 수 있는 최대 IO 연산 수
b : tcp backlog 큐 크기
c : 연결할 수 있는 클라이언트의 최대 개수
m : 최대 저장 용량(MB)
❒ ARCUS 데이터 영속성 설정
ARCUS default 엔진 동작에 관한 설정을 가지는 default_engine.conf 파일에 아래와 같이 Persistence 관련 설정을 하였습니다. Persistence 설정에 대한 설명은 Persistence 기능의 개요와 사용법에서 확인하실 수 있으니 각 시험 항목에 따라서 설정할 값만 안내드립니다.
# Persistence configuration
#
# use persistence (true or false, default: false)
use_persistence=true
#
# The path of the snapshot file (default: ARCUS-DB)
data_path=/disk2/test/arcus/ARCUS-DB
#
# The path of the command log file (default: ARCUS-DB)
logs_path=/home/test/arcus/ARCUS-DB
#
# asynchronous logging
async_logging=false
#
# checkpoint interval (unit: percentage, default: 100)
# The ratio of the command log file size to the snapshot file size.
# 100 means checkpoint if snapshot file size is 10GB, command log
# file size is 20GB or more
chkpt_interval_pct_snapshot=100
#
# checkpoint interval minimum file size (unit: MB, default: 256)
chkpt_interval_min_logsize=256use_persistence
- 저장 용도 시험 시 true로, 캐시 용도 시험 시 false로 설정합니다.
data_path, logs_path
- 데이터 파일과 로그 파일의 경로는 디스크를 분리하여 설정하는 것을 권장합니다.
- 체크포인트의 스냅샷 작업이 디스크 IO 자원을 모두 점유하여, 일반 요청을 처리하는 작업 스레드의 로깅 작업이 지연되기 때문입니다.
async_logging
- 비동기 로깅 모드 시험 시 true로, 동기 로깅 모드 시험 시 false로 설정합니다.
chkpt_interval_pct_snapshot, chkpt_interval_min_logsize
- 기본 값으로 설정하였습니다.
❒ 성능 측정 도구
부하를 생성하고 성능을 측정하기 위하여 memtier_benchmark 1.3.0 버전을 이용하였습니다. Memcached 프로토콜을 지원하여 ARCUS KV 명령의 삽입 (set) 과 조회 (get) 연산을 수행할 수 있습니다. 또한 키를 균등 분포 또는 가우시안 분포로 생성할 수 있으며, 초당 평균 처리량과 평균/꼬리 응답시간을 확인할 수 있습니다.
❒ ARCUS 모니터링 도구
ARCUS 엔터프라이즈 모니터링 도구인 Hubble를 이용하여 웹 브라우저에서 장비의 시스템 리소스 및 ARCUS 인스턴스의 통계 정보를 관찰하였습니다.
성능 시험 시나리오
❒ 시험 비교 항목
시험에서 확인하고 비교할 성능 수치입니다.
- 처리량 (Throughput) — 평균 처리량
- 응답시간 (Latency) — 평균 응답시간, 꼬리(tail) 응답시간(90%, 95%, 99%)
❒ 시험 데이터 생성
시험 데이터는 memtier_benchamrk 도구를 사용하여 자동 생성되게 하였습니다.
전체 데이터 건수 : 5천만건 (6.5GB)
- 키 크기 : 9~17Bytes (“memtier-1” ~ “memtier-50000000”)
- 데이터 크기 : 50Bytes
- 아이템 크기 : 평균 130Bytes (키, 데이터, 메타데이터 총합)
❒ 시험 시나리오 목록 및 절차
아래 성능 시험들에 대해 memtier_benchmark 도구를 사용하여 기존 캐시 모드, 비동기 로깅 모드, 동기 로깅 모드의 성능을 측정하였습니다. 조회와 변경 시에 키를 균등 분포로 생성하여 성능을 측정하였고, 가우시안 분포는 측정하지 않았습니다. ARCUS에서 전체 데이터는 메모리에 상주하므로 균등 분포와 가우시안 분포는 동일한 성능을 보일 것이기 때문입니다.
삽입 성능 시험:
- 5천만건 데이터를 삽입
- 실행 명령어
memtier_benchmark --threads=8 --clients=50 --data-size=50 \
--key-pattern=P:P --key-minimum=1 --key-maximum=50000000 \
--ratio=1:0 --requests=125000 --print-percentiles=90,95,99 조회 성능 시험:
▪ 5천만건 데이터를 삽입한 이후, 키를 균등 분포로 생성하여 조회
▪ 실행 명령어
memtier_benchmark --threads=8 --clients=50 --data-size=50 \
--key-pattern=R:R --key-minimum=1 --key-maximum=50000000 \
--distinct-client-seed --randomize --ratio=0:1 --requests=125000 \
--print-percentiles=90,95,99조회와 변경 연산의 혼합 성능 시험:
▪ 5천만건 데이터를 삽입한 이후, 키를 균등 분포로 생성하여 1:9, 3:7, 5:5 비율로 삽입과 조회
▪ 실행 명령어
memtier_benchmark --threads=8 --clients=50 --data-size=50 \
--key-pattern=R:R --key-minimum=1 --key-maximum=50000000 \
--distinct-client-seed --randomize --ratio=1:9 --requests=125000 \
--print-percentiles=90,95,99성능 시험 결과
평균처리량과 평균/꼬리 응답시간 수치를 정리하였습니다. OFF 는 기존 캐시 성능, ASYNC는 비동기 명령 로깅 모드, SYNC 는 동기 명령 로깅 모드를 의미합니다.
❒ 삽입 연산
5천만건 데이터 삽입 성능은 다음과 같습니다.
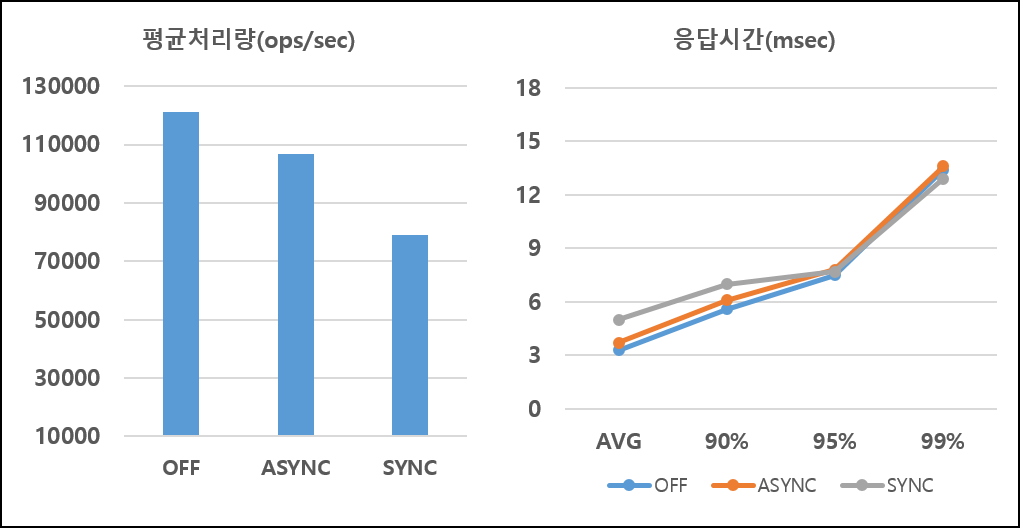
클라이언트의 모든 요청이 삽입 연산으로 구성되어 있어 데이터 영속성 성능을 가장 드러나게 확인할 수 있습니다. 기존 캐시 성능과 비교하더라도 영속성 기능 사용에 따른 성능 저하는 그렇게 크지 않은 것을 확인할 수 있습니다. 특히, 동기 로깅 모드는 어떤 시점에 ARCUS 인스턴스를 비정상 종료하더라도 데이터를 완벽히 복구할 수 있도록 작업 스레드가 명령 로그를 디스크에 반영된 것을 확인한 후에 그 변경 연산의 수행을 완료합니다. 이러한 높은 성능을 보이는 것은 작업 스레드가 명령 로그의 디스크 반영 동안에도 다른 클라이언트의 요청들을 처리할 수 있도록 구현하였기 때문입니다.
❒ 조회 연산
5천만건 데이터를 균등 분포로 조회한 성능은 다음과 같습니다.
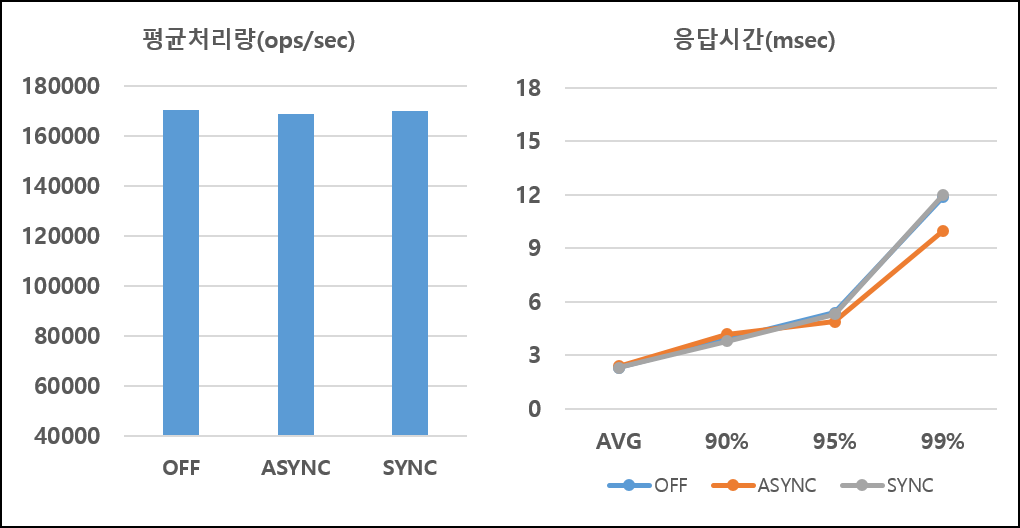
조회 연산 시험의 경우 ARCUS 변경 요청이 없으므로 명령 로깅이 수행되지 않습니다. 따라서 영속성 모드를 사용하더라도 기존 캐시 성능과 동일합니다.
❒ 혼합 연산
변경과 조회 비율이 1:9인 혼합 연산의 성능은 다음과 같습니다.
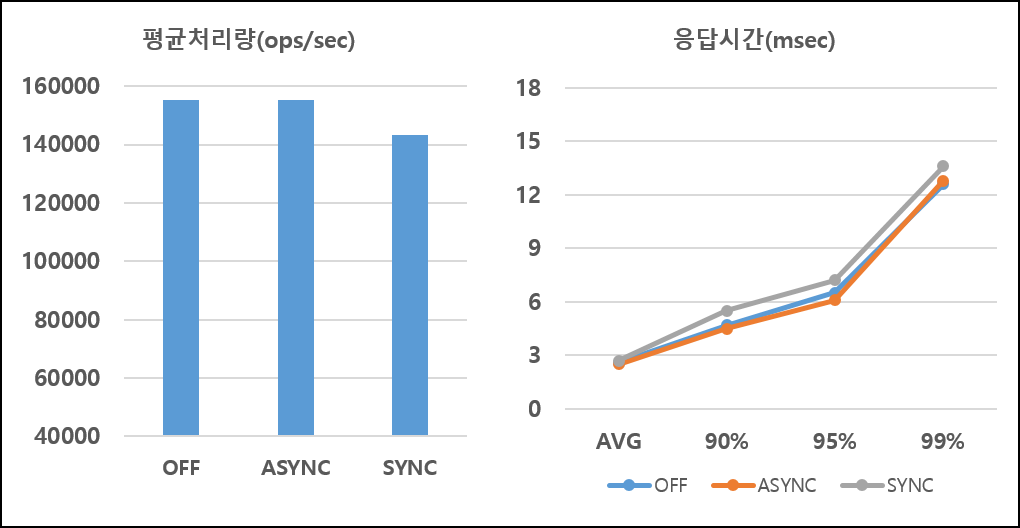
변경과 조회 비율이 3:7인 혼합 연산의 성능은 다음과 같습니다.
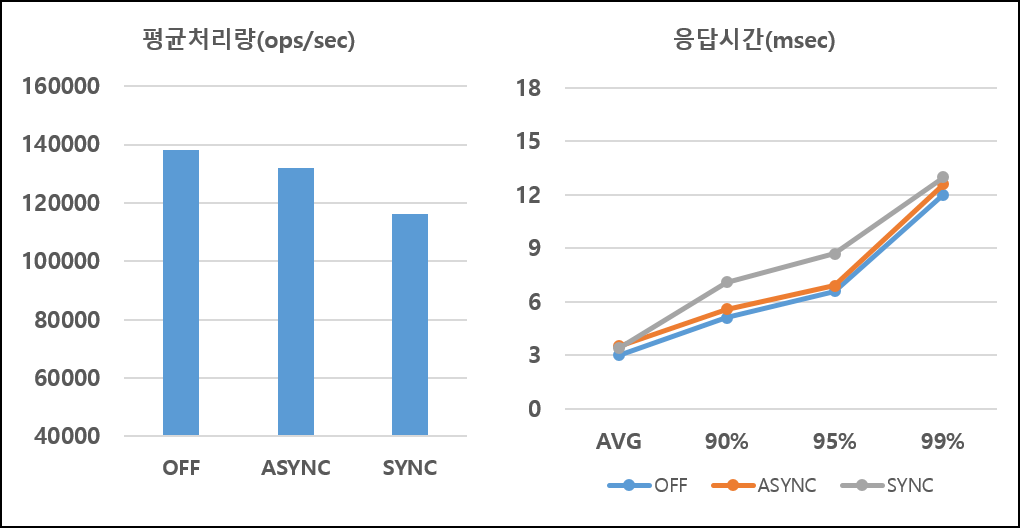
변경과 조회 비율이 5:5인 혼합 연산의 성능은 다음과 같습니다.
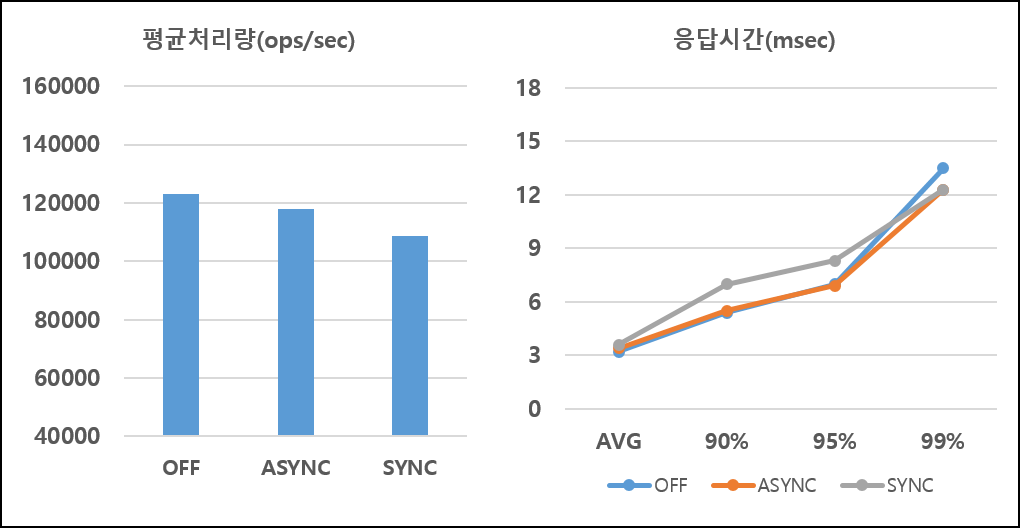
혼합 연산의 성능은 기존 캐시 용도의 성능과 거의 비슷함을 확인할 수 있습니다. 특히 ARCUS는 시스템 구조의 특성 상 조회 성능이 매우 좋아서 조회 연산 비중이 높은 시험의 경우 영속성 모드 사용에 관계없이 고성능을 보입니다. 삽입과 조회 비율이 1:9 인 경우 동기 로깅 모드의 요청 처리량은 기존 캐시의 요청 처리량보다 20K 정도 밖에 차이나지 않았습니다.
❒ 체크포인트 영향
추가로 체크포인트 시의 요청처리량 변화를 확인하실 수 있도록 ARCUS 엔터프라이즈 모니터링 도구인 Hubble 에서 관찰한 ARCUS 가 구동된 장비의 User/System CPU 사용량과 ARCUS 캐시 노드의 요청처리량 지표를 보여드립니다. 참고로, 아래 정보 외에도 분석에 필요한 여러 정보를 보여드릴 수 있지만 지면 관계상 생략하였습니다.
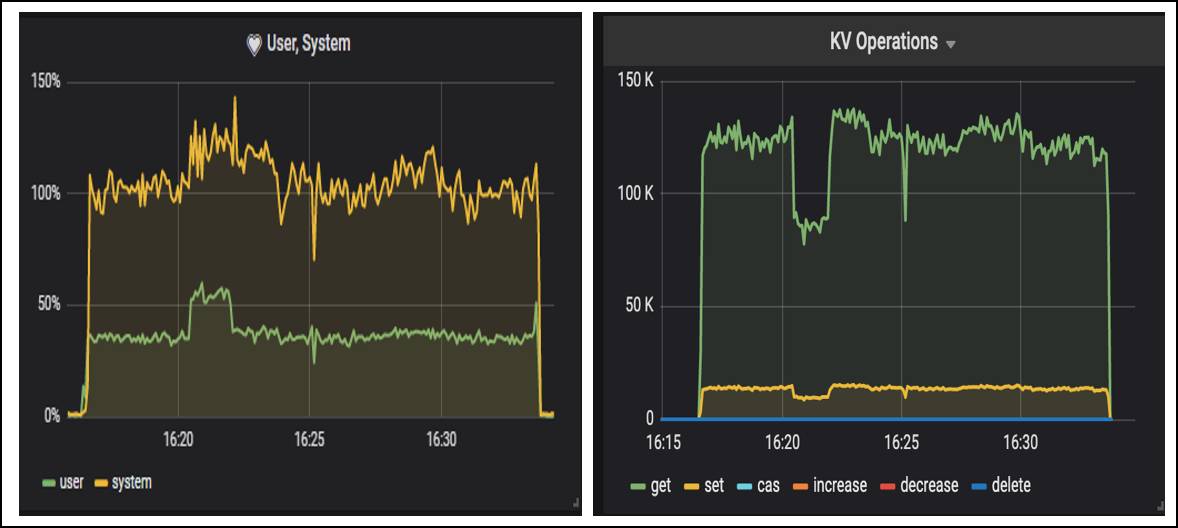
5천만건 삽입한 상태에서 변경과 조회 비율 1:9인 혼합 연산 성능 시험을 비동기 로깅 모드로 동작하였을 때의 모습입니다. 평균 처리량은 변경 연산 처리량(노랑색)과 조회 연산 처리량(초록색)을 합한 150K 정도 입니다. 처리량이 일시적으로 감소한 16:21 ~ 16:23 은 체크포인트 수행 지점으로, 스냅샷 파일에 5GB 정도 기록되었습니다. 향후 계획으로 체크포인트를 천천히 진행하도록 변경하여 처리량 감소율을 더욱 줄일 예정입니다.
마치며
ARCUS 데이터 영속성 기능에 대해, 기존 캐시 용도와의 성능 비교를 포함하여 명령 로깅 모드에 따른 성능을 측정해보았습니다. 서두에서 언급하였듯이 ARCUS 영속성은 일반 요청 처리에 미치는 영향을 최소화하도록 설계되어서 기존 캐시와 차이가 크지 않은 성능을 보였습니다. 특히, 대부분의 실서비스 워크로드 패턴은 조회 연산 비중이 많은 삽입과 조회를 혼합한 형태이며, 혼합 시험 결과를 보면 상당히 높은 성능을 보였습니다. 본 시험 환경에 사용한 디스크는 Naver Cloud Platform 의 VM 장비가 기본적으로 제공하는 HDD 를 사용하였습니다. 높은 IOPS 를 제공하는 NVMe SSD와 같은 디스크를 사용하면 더 높은 ARCUS 데이터 영속성 기능의 성능을 볼 수 있습니다. 데이터 보존이 필요하면서 원활한 서비스가 가능한 정도의 고성능을 보장할 수 있는 ARCUS 데이터 영속성은 대부분의 응용에서 좋은 선택이 될 것입니다. ARCUS 데이터 영속성은 지속적으로 최적화를 통해 처리량과 응답시간을 향상시키고 운영 관점의 사용 편의성을 높히도록 개선해나가고 있습니다.
마지막으로 ARCUS 데이터 영속성 사용 상의 주의사항으로, ARCUS 데이터 영속성 기능의 체크포인트 작업은 메모리에 있는 전체 데이터를 디스크로 쓰기 때문에 많은 디스크 IO 자원을 사용하게 되며, 이로 인해 변경 연산의 명령 로깅 작업이 지연될 수 있습니다. 따라서, ARCUS 데이터 영속성 기능의 높은 성능을 보기 위해서는 데이터 파일과 로그 파일의 디스크 분리가 필수입니다.