
Kafka Intro with LINE Engineering
- Line Development Day 2018에서 Yuto Kawamura님이 발표한 내용에 기반한 블로그 글을 바탕으로 필자가 알아야 할 내용을 보충설명 하였습니다.
Kafka란?
Kafka를 아래와 같이 4가지 개념으로 설명한다. 각각 무엇을 의미하는지 알아보자. 특히, 라인과 같은 서비스를 제공하는 기업(메신저가 주요 기능, 실시간 streaming data 처리)에서 대규모 Kafka Platform을 운영한다.
-
Middle ware for Streaming Data : 스트리밍 데이터를 다루기 위한 미들웨어이다.
-
High Scalability, High Availability : 높은 확장성, 높은 가용성
- Scalability : 확장성, 라인과 같은 서비스에서는 사용자에 요구에 따라 Resources를 증가시키거나 감소시키는 것이 필수이다. Cloud System의 가장 큰 특징이라고 할 수 있다.
- Availability : Server, Network 등 System이 오랜 기간동안 정상적으로 동작이 가능한 성질을 말한다.
-
Data Persistency : 데이터 영속성
- 데이터가 생성된 곳이 지워지더라도, 지속적으로 유지될 수 있는 성질을 의미한다.
- 즉, Data가 생성된 Process가 종료된 이후에도 데이터가 살아남는 것을 의미한다.
-
Supports Pub-Sub Model : Publish / Subscribe의 줄임말로, 메세지 기반의 MiddleWare System을 의미한다.
- Publisher(Sender) -> Subscriber(Receiver) : 메세지를 이와 같이 전달한다고 하자.
- Publisher 입장에서는 어떤 Subscriber가 있는지 모르는 상태에서 메세지를 전송한다.
- Subscriber 입장에서는 Publisher에 대한 정보 없이 자신의 Interest에 맞는 메세지를 받는다.
Kafka는 위와 같은 모델을 지원한다.
Kafka 기본 컴포넌트
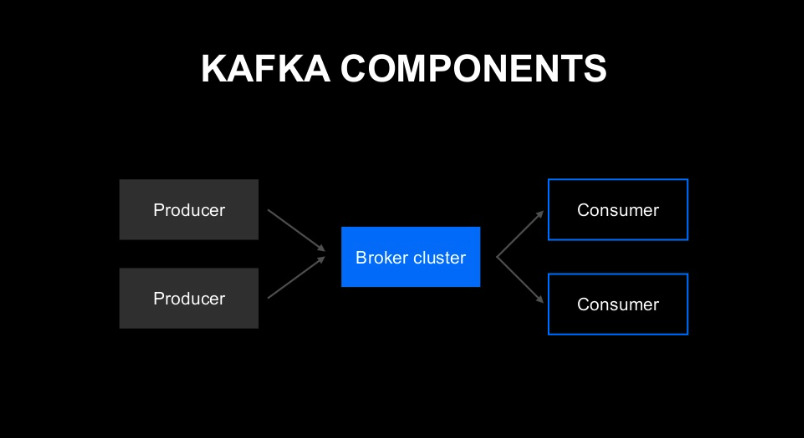
- Producer : Kafka에 데이터를 입력하는 클라이언트
- Broker Cluster : 임의 개수의 노드로 구성되는 Cluster, Topic을 임의 개수만큼 호스팅 가능하다.
- Topic : 데이터 관리 유닛, 데이터를 최종적으로 저장하는 곳이며, 데이터를 구분하기 위한 저장소이다.
- Topic에 있는 데이터 -> Consumer가 여러번 가져올 수 있다.
- Consumer : 데이터를 가져올 Topic을 지정한 후, 해당 Topic에서 데이터를 가져온다.
기본 컴포넌트를 통해, Pub/Sub라고 불리는 데이터 분포 모델을 확인할 수 있다.
LINE에서 Kafka는 어떻게 사용하는가?
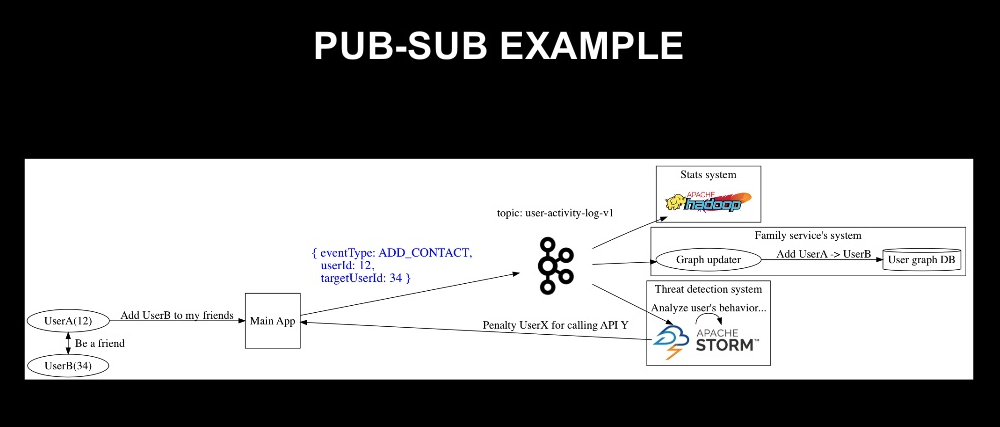
- 분산 큐잉 시스템
- Web Application Server에서 Resource가 많이 필요한 업무가 발생 -> 내부에서 처리하지 않고, 다른 프로세스에서 작동중인 백그라운드의 Task Process에 요청하기 위한 큐로 사용한다.
- 부족한 리소스를 충당하기 위해 분산 큐잉 시스템으로 활용
- 데이터 허브
- 사전적 의미 : 데이터 중심의 스토리지 아키텍쳐, 여러 출처로부터 나오는 데이터의 모임이다.
- 어떤 서비스에 데이터 업데이트 발생-> 해당 데이터를 사용하는 다른 서비스에 전파하기 위한 허브로 사용한다.
- LINE에서는 친구관계 데이터 저장
- 사용자 A -> 사용자 B 추가
- 업데이트된 관계를 Kafka Topic에 추가 -> 다른 Consumer(service)들이 이를 가져가서 Update한다.
LINE에서 사용하는 Multi-Tenancy Kafka Cluster
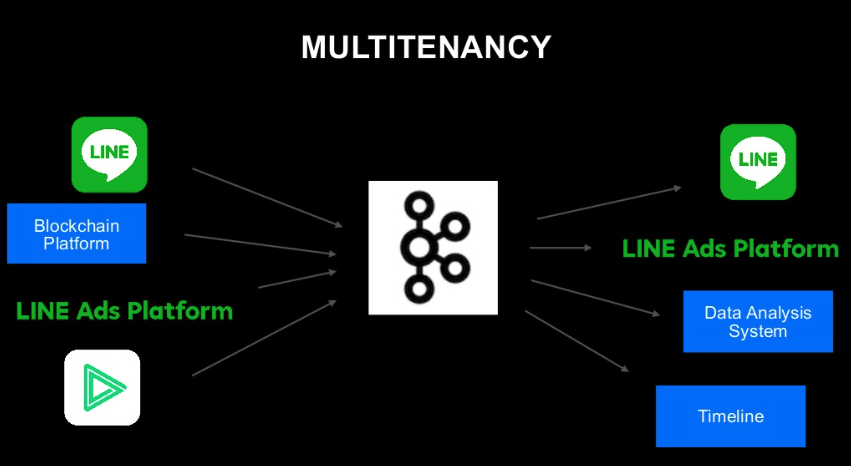
- 단일 Kafka Cluster
- 매우 큰 규모의 Kafka Cluster를 여러 서비스와 시스테에서 공통적으로 사용하고 있는 점을 알 수 있다.
- 왜 대규모의 Cluster를 사용하는 것일까?
- Data Hub Concept : 하나의 클러스에 데이터를 집중
- 여러 서비스가 데이터를 쉽게 찾을 수 있다.
- 여러 서비스가 데이터에 접근하는 수단을 하나로 통일한다.
- 아키텍쳐가 단순하다.
- Management Efficiency : 운영하는데 효율적이다.
- 서비스, 시스템별로 kafka Cluster를 하나씩 준비 -> 운영 비용이 증가한다.
- 이를 피하기 위해 서비스와 시스템이 하나의 Cluster를 사용한다.
- Engineering 자원을 쏟아부어 Cluster의 신뢰성과 성능을 극대화시킨다.
- Data Hub Concept : 하나의 클러스에 데이터를 집중
- Multi-Tenency 충족을 위한 조건
- Cluster에 가해지는 지나친 Workload에서 보호를 받아야한다.
- 악의적인 경우 고려 x
- Deployment 실수 -> Cluster에 부하가 걸릴 수 있다.
- 요청이 어느 Client에서 온 것인지 정확히 파악해야한다.
- 예상치 못한 Resource 요청이 어느 Client에서 왔는지 신속하게 찾아 해결해야한다.
- Client간 Workload 부하 격리를 유지해야한다. -> 다음 포스팅
- Kafka Cluster에 접속하고 있는 A Client -> 작업 부하가 걸림
- 그렇다고 해서 B Client가 응답시간이 저하될 이유는 없어야한다.
- Cluster에 가해지는 지나친 Workload에서 보호를 받아야한다.
Kafka Cluster를 지나친 작업부하에서 보호하기
- Kafka Cluster를 지나친 작업부하에서 보호
- Workload 부하에 영향을 미치는 정도 : Incoming/Outgoing Data < Number of Requests
- 왜? -> Kafka는 대용량 데이터를 잘 다룰 수 있도록 설계된 소프트웨어이다.
- Kafka 자체 : Cache Layer가 없다. OS가 제공하는 Page Cache에 Cache 기능 전면적으로 의존한다.
- Page Cache : Disk I/O 효율을 위해 메인 메모리에 잡아놓은 Cache Buffer
- 왜? -> Kakfa Client는 Batching 시스템으로 여러 개의 데이터를 하나의 큰 요청으로 묶어서 Cluster에 전달 가능하다.
- 따라서 데이터 양이 늘어나도 Request 수를 제어할 수 있다.
- 이를 위하 Request Quota 기능을 사용한다.

- Request Quota : 특정 Client가 사용할 수 있는 Broker의 자원을 제한한다.
- Broker가 가진 Thread의 시간을 제한하는 기능이다.
- 이를 모든 Client에 기본으로 설정 -> 하나의 Client가 사용할 수 있는 Broker 자원의 양을 제한할 수 있다.
- Client 레벨에서 Broker에서 사용 가능한 리소스를 제어한다
- 이를 통해 Cluster가 멈추는 것을 막는다.
출처
Line Development Day 2018에서 Yuto Kawamura님이 발표한 내용에 기반한 블로그 글을 바탕으로 필자가 알아야 할 내용을 보충설명 하였습니다.

자망스탕스