
Kafka Intro with LINE Engineering
- Line Development Day 2018에서 Yuto Kawamura님이 발표한 내용에 기반한 블로그 글을 바탕으로 필자가 알아야 할 내용을 보충설명 하였습니다.
Multi-Tenency 충족을 위한 조건
- Cluster에 가해지는 지나친 Workload에서 보호를 받아야한다.
- 악의적인 경우 고려 x
- Deployment 실수 -> Cluster에 부하가 걸릴 수 있다.
- 요청이 어느 Client에서 온 것인지 정확히 파악해야한다.
- 예상치 못한 Resource 요청이 어느 Client에서 왔는지 신속하게 찾아 해결해야한다.
- Client간 Workload 부하 격리를 유지해야한다.
- Kafka Cluster에 접속하고 있는 A Client -> 작업 부하가 걸림
- 그렇다고 해서 B Client가 응답시간이 저하될 이유는 없어야한다.
1번 조건 -> 앞선 포스팅에서, Request Quota 기능을 사용하여 Client측에서 사용할 수 있는 Broker의 자원을 제한한다.
3번 조건 -> 운영 환경에서 발생한 문제가 있다. 이것을 이번 포스팅에서 알아볼 것이다.
LINE 운영 환경에서 발생한 문제
- Produce API: Kafka Client가 Cluster에 데이터를 입력할 때 사용하는 API이다.
- 응답 시간의 99%ile -> 제일 응답시간이 많은 상위 1% -> 50~100배 악화됨
원인은 크게 2가지로 나뉜다.
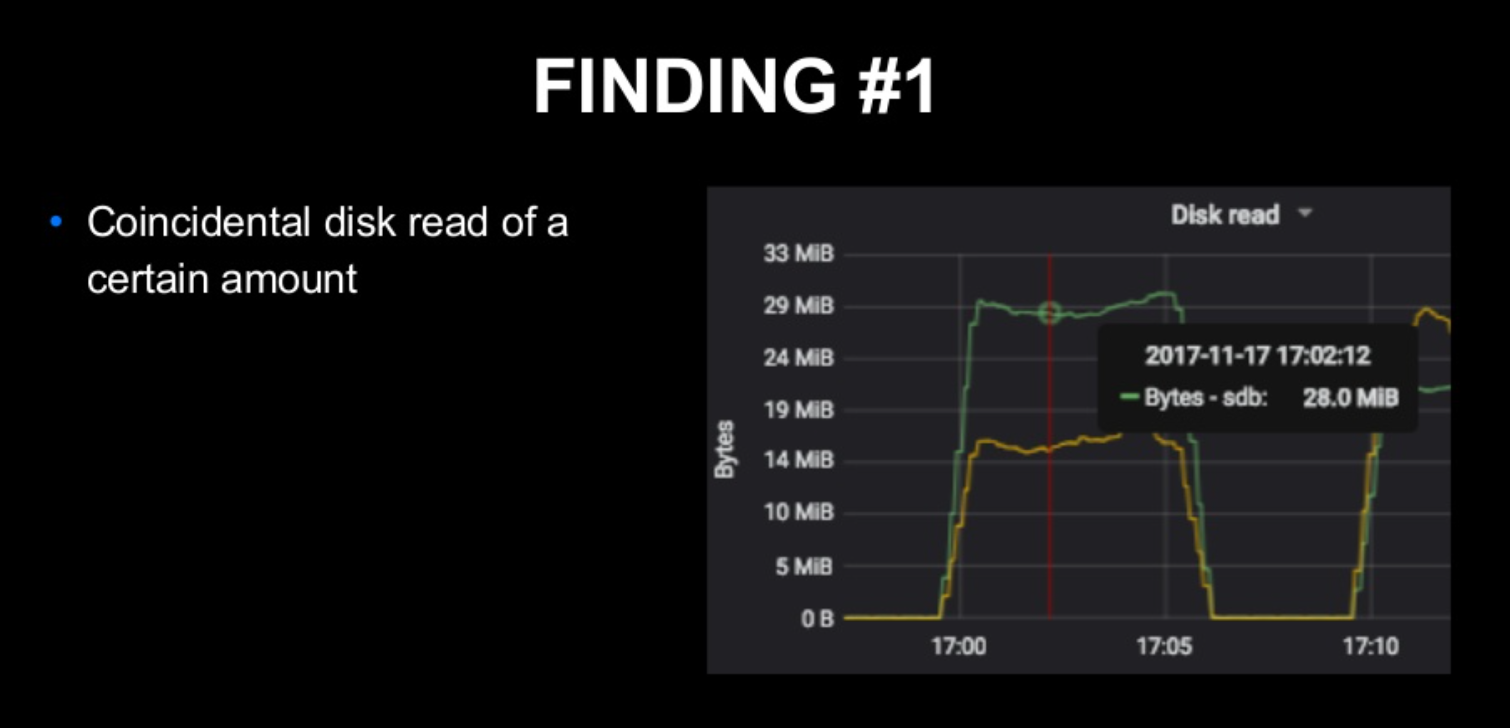
- 매우 많은 양의 Disk Read -> 표에서 디스크 Read가 높아진 것을 확인할 수 있다.
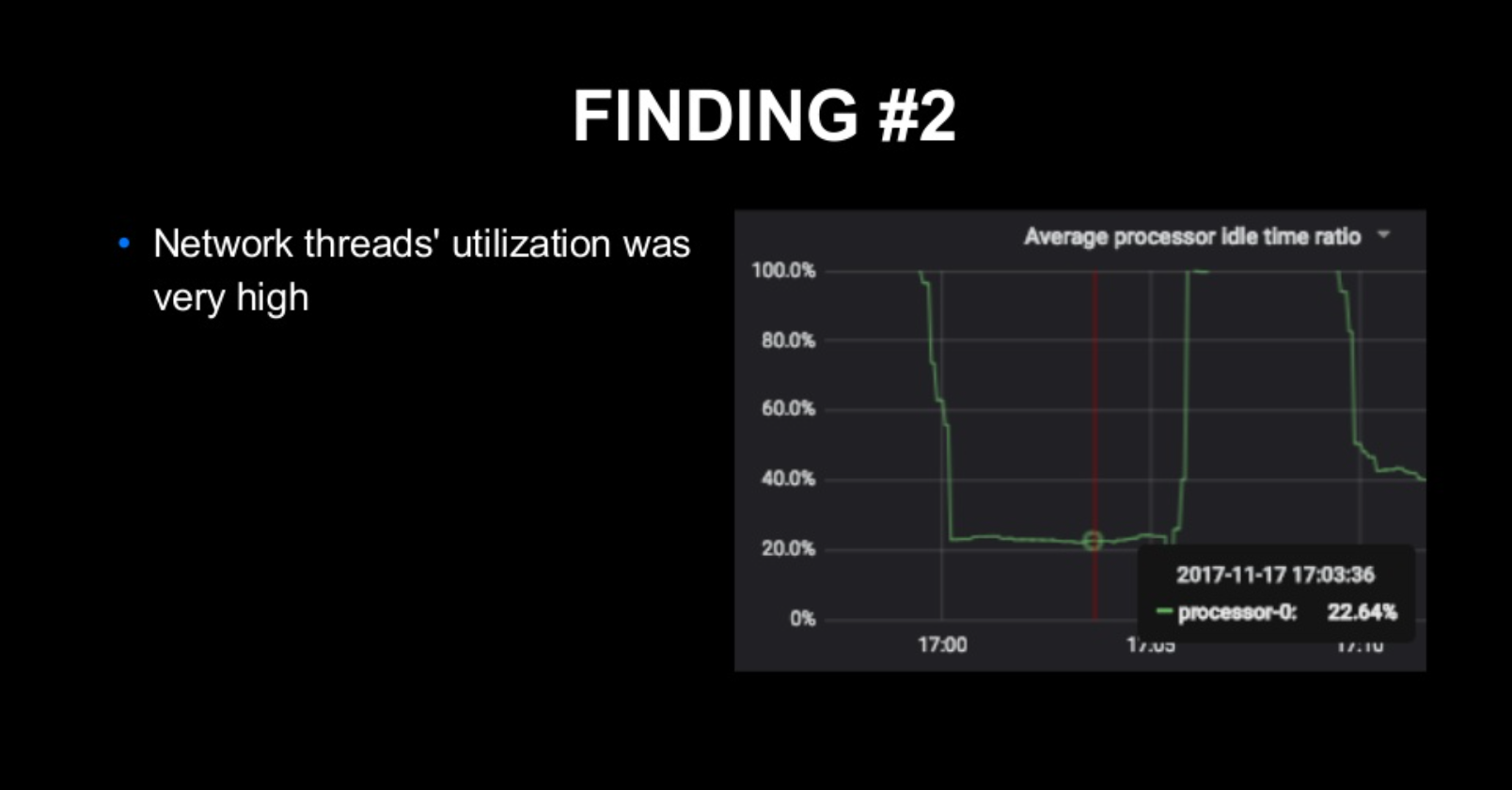
- Network Thread의 Utilization이 매우 높아졌다. -> 평균적인 Processor의 Idle time 비율이 낮아짐, Network threads utilization이 높아짐을 확인 가능하다.
문제의 원인 조사
Kafka의 Request Handling
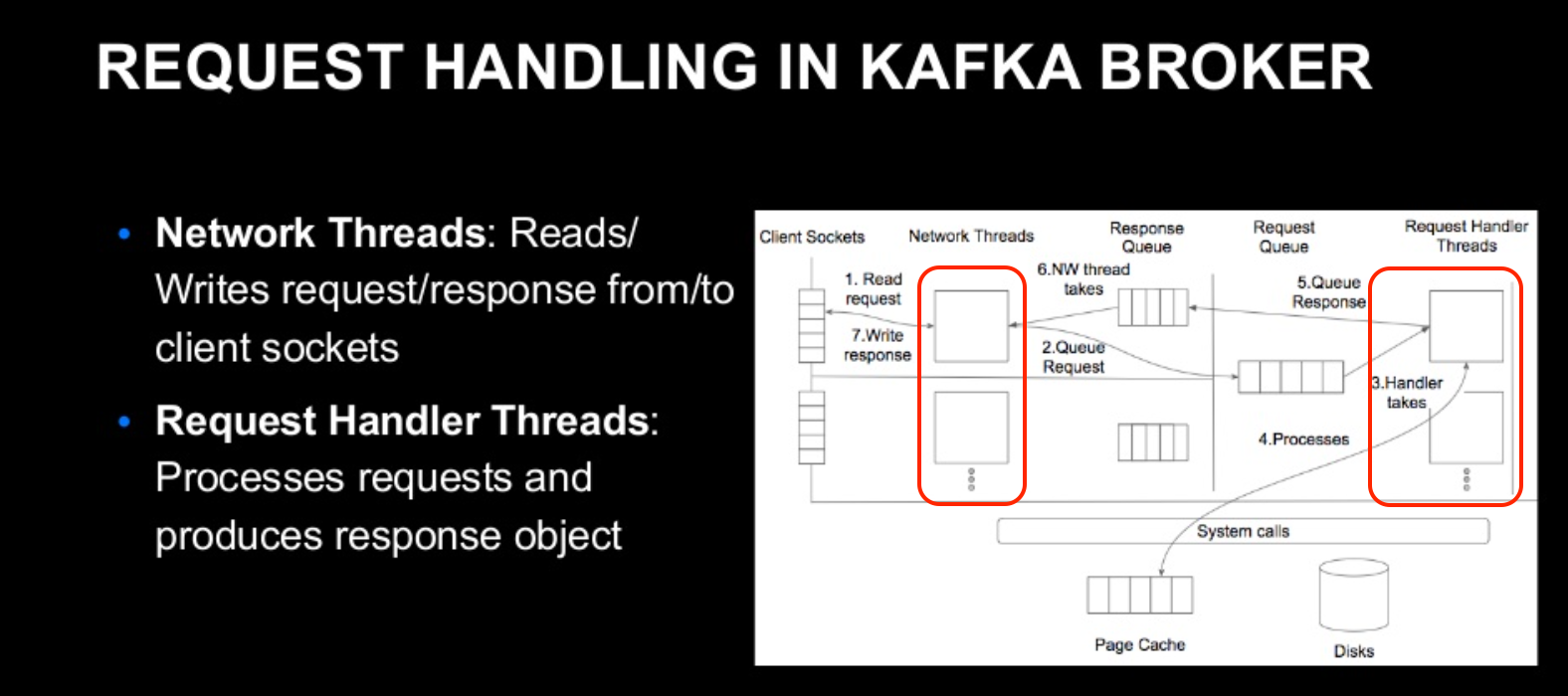
- Kafka의 요청 처리는 위의 체크한 2개의 Thread Layer를 사용한다.
- Network Threads : Client와의 I/O를 담당하는 Thread이다. 역할은 Request, Response측면에서 2개로 나뉜다.
- Client Socket에 도착한 Request를 가져와 (1)
- Request Object를 생성 (2), Request Object는 Request Queue에 저장이된다.
- Response Object를 가져온다. (6), Response Object는 Response Queue에 저장이 된다.
- Response Object를 Client Socket에 입력한다. (7)
- Handler Threads : Network Thread가 가져온 Request의 내용을 처리해서 필요한 Response 객체를 Network Thread에 반환한다.
- Network Thread에서 Request를 가져온다. (3)
- Request에 대한 처리를 한다. (4)
- 처리에 대한 결과를 Response Object의 형태로 Network Thread로 반환한다. (5)
- Network Threads : Client와의 I/O를 담당하는 Thread이다. 역할은 Request, Response측면에서 2개로 나뉜다.
Network Thread 증가 현상이 왜 일어나나?
- Request 수가 많아져서 처리가 힘들다? -> Request 수에 변동이 없었다고 한다.
- Network Thread가 Process를 수행하는 과정인 이벤트 루프 내의 특정 Process에서 차단이 된 경우
- Kafka Source Code 분석, 아래 그림을 보자.
- 이를 이해하기 위해서는 아래 그림을 순서대로 분석해야한다.
Kafka의 API별 응답 처리 방식에는 차이가 있다.

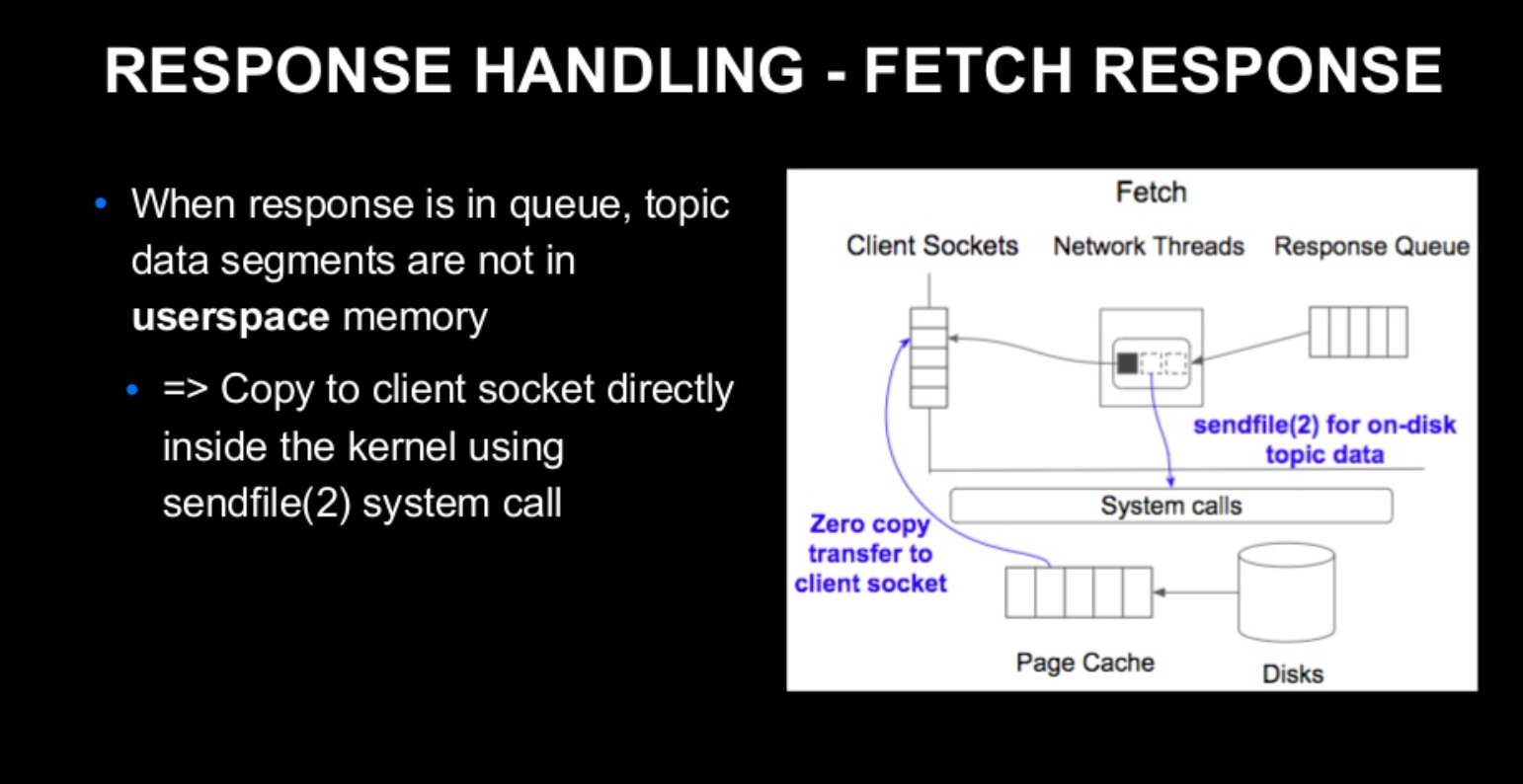
- Fetch를 제외한 다른 API : Network Thread가 Resonse Queue에서 Response Object를 취득한 시점에, Client Socket에 입력해야 할 데이터가 모두 메모리에 저장되어 있다. -> Network Thread는 데이터를 Socket에 복사만 하면 된다.
-
Fetch API : Consumer가 Topic의 데이터를 Cluster에서 가져올 때 사용하는 API이다.
-
Broker는 Response를 반환할 때, Local Disk에 저장되어 있는 Topic의 데이터를 Client Socket에 복사해야한다.
-
이때, sendfile이라는 System Call을 사용한다. -> Linux Kernel에서 제공하는 System Call, Local Disk의 데이터를 Client Socket에 바로 복사할 수 있게 해주는 API이다.
-
sendfile을 처리하는 방법은 2개로 나뉜다.
a. Page Cache에 Topic이 있다. -> 바로 Client Socket에 붙여준다 : 10μs ~ 999μs
b. Page Cache에 Topic이 없다. -> Local Disk에서 데이터를 로딩한다. -> Client Socket에 붙여준다 : 1ms ~ 99ms
시간 차이가 분명하게 보이는 것을 확인할 수 있다. a 처리 방식이 Event Loop 처리 중에 발생하면, 시간이 엄청 걸릴 수 밖에 없다.
-
그렇다면, Disk에서 데이터를 로딩하면 어떻게 되는 것인가?
-
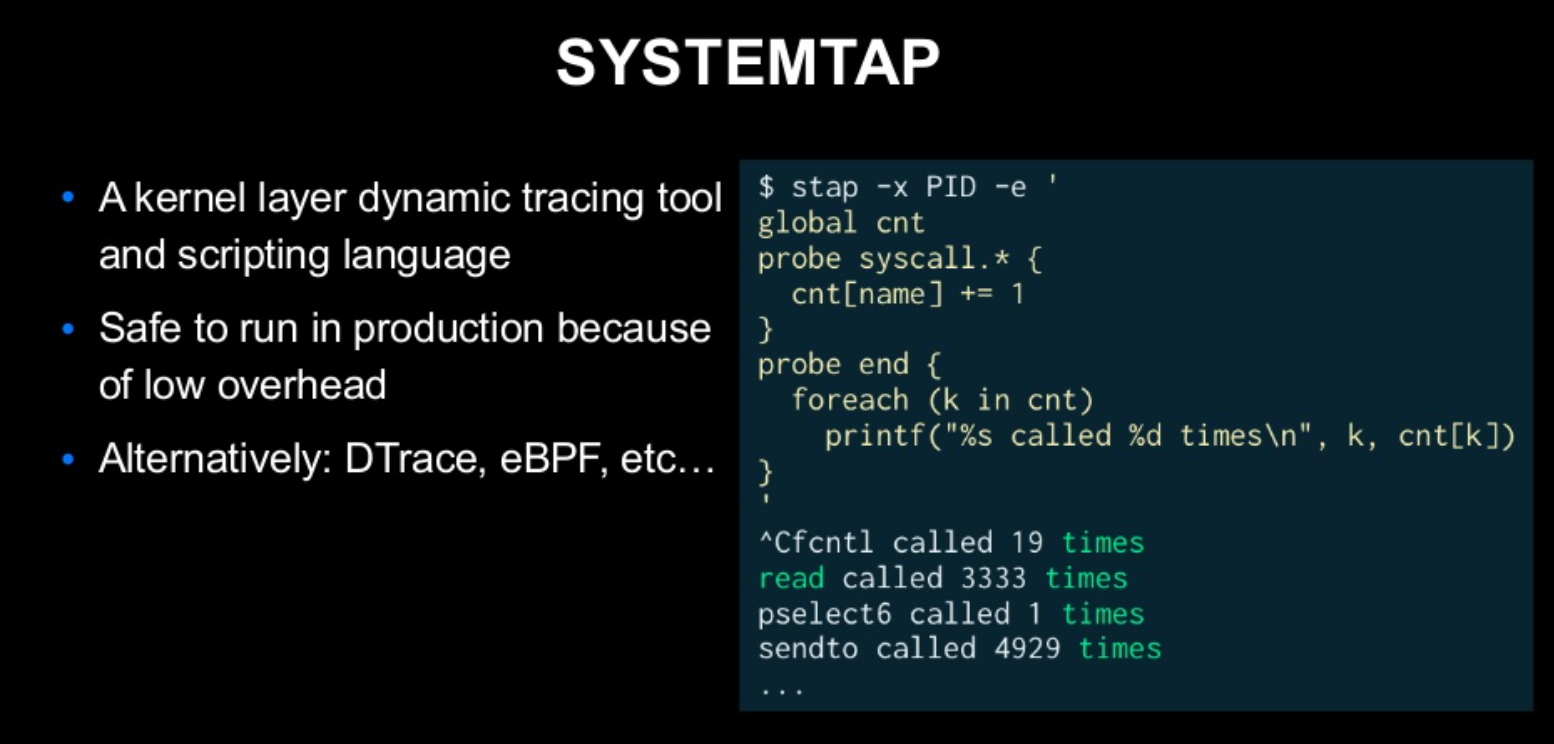
sendfile System Call 처리 시간을 알아보기 위해, SystemTap이라는 툴을 사용한다.
- cnt[name] +=1 : name에 해당하는 System Call이 호출되면, 횟수를 증가시킨다.
- 각 system call이 나온 횟수를 측정이 가능하다.
해당 SystemTap은 운영 환경에서도 overhead를 신경 쓸 필요없이 안심하고 실행이 가능하다. 비슷한 툴로는
- DTrace
- eBPF
가 있다.
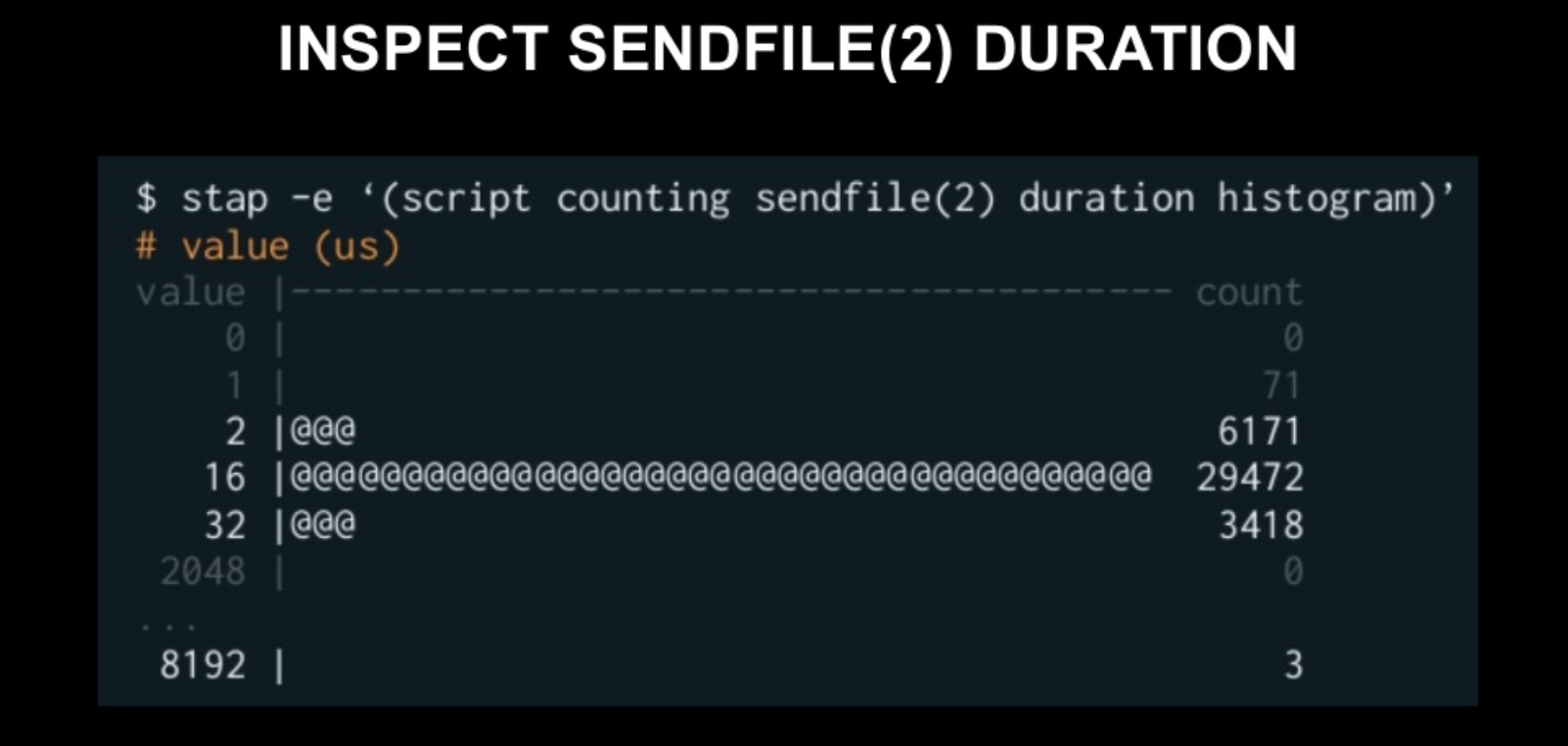
- 2~32μs : 대부분 이정도 처리 시간이 걸린다. -> Page Cache에서 Client Socket에 복사한 것이다.
- 8192μs : 극히 일부분 -> Page Cache에 데이터가 없어서, Disk에서 복사한 것이다.
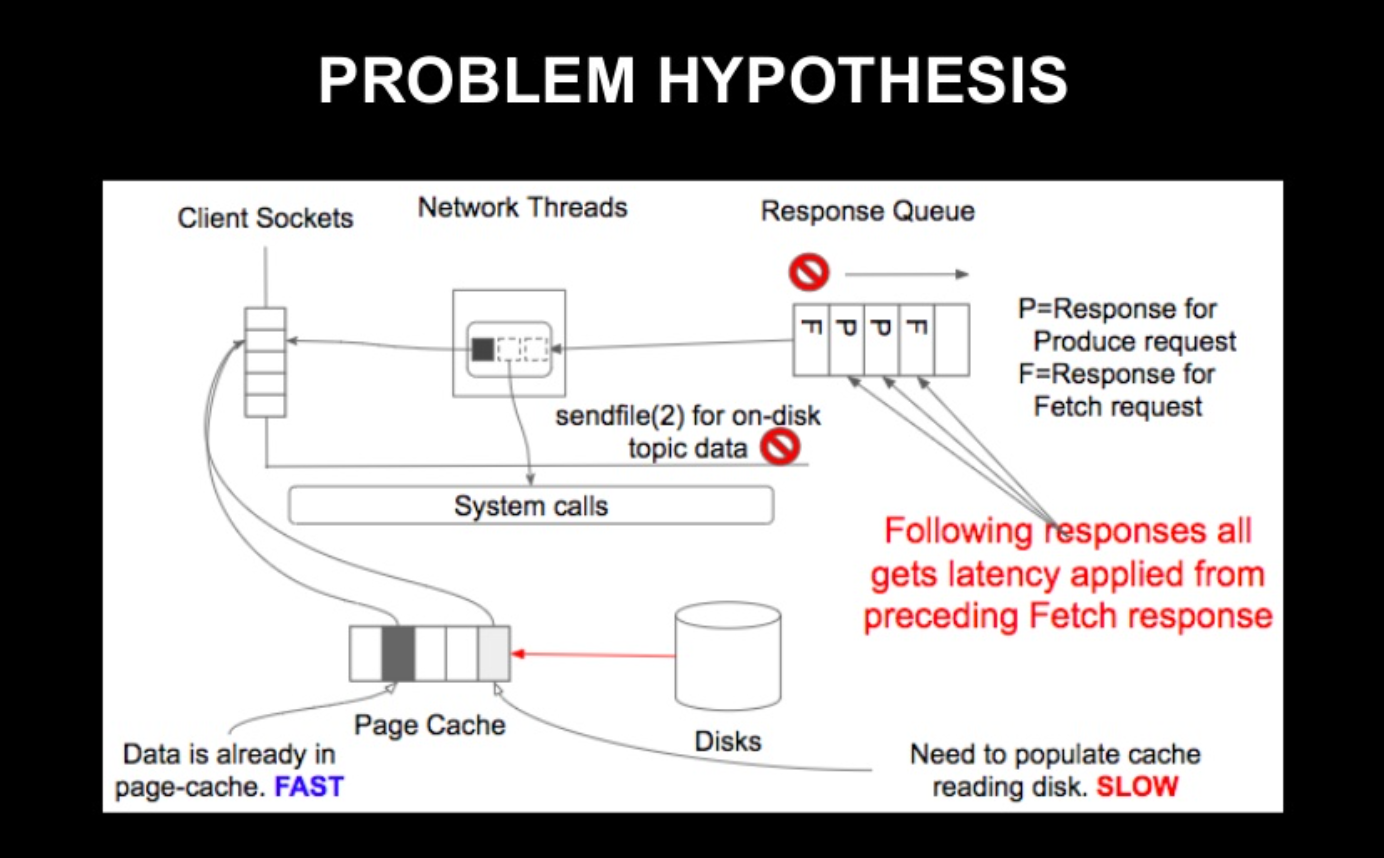
해당 결과를 보고 가설을 세워보았으며, 내용은 다음과 같다.
-
Broker가 Fetch 요청을 처리한다.
-
이 과정에서 sendfile 호출 -> Page Cahe에 데이터가 없고, Disk Read가 필요하면, Network Thread의 Event Loop가 차단이 된다.
-
이렇게 되면
- 현재 처리중인 Request
- 후속 Response
- 다른 관련 API
가 싹다 차단된다는 가설
이를 통해, 원래 관련이 없던 Produce API의 응답 시간이 저하된 것도 설명이 가능하다.
출처
Line Development Day 2018에서 Yuto Kawamura님이 발표한 내용에 기반한 블로그 글을 바탕으로 필자가 알아야 할 내용을 보충설명 하였습니다.
