- NELL995 dataset 사용
- Node, Graph class 기본 정의
- PageRank(Global, Personalized) computing function
- 각 node의 PPR을 일일히 update해주는 방식
- Matrix-vector multiplication으로 구하는 방식
xv(k+1)=α∑w∈Sv∣Tw∣xw(k)+nq1−α (if v is in the predefined set)
⋯ Sv: set of incoming neighbors of v, Tw: set of outgoing neighbors of w, nq: # of predefined nodes,
Lab #2: Modularity Optimization
- scikit-network library의 karate_club dataset 사용
- Sparse adjacency matrix 생성, Louvain method 적용 (scikit-network-louvain) → Graph clustering
- Normalized cut 계산
- 각 link에 대해 일일히 더해주는 방식
- Matrix multiplication으로 구하는 방식
- sknetwork library의 svg_graph 통한 visualization
NC(G)≡∑c=1kdeg(Vc)Cut(Vc,V\Vc)=∑c=1kycTDycycT(D−A)yc
Lab #3: GraphSAGE
- Cora dataset 사용
- GCN / GraphSAGE model 구현 (layer#, input dim., hidden dim., output dim., type of agg.)
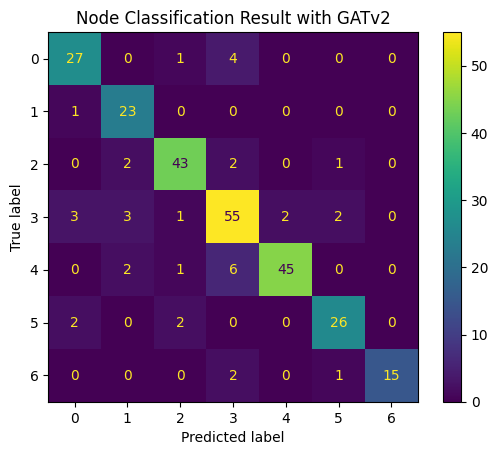
- Training, Validation, Evaluation, Visualization(Confusion matrix)
GCN Layer
hv(l+1)=σ(Wl∑u∈N(v)∣N(v)∣hu(l)+Blhv(l))
GraphSAGE Layer
hv(l+1)=σ(Wl[AGG(hu(l),∀u∈N(v)),hv(l)])
Lab #4: GAT
- Cora dataset 사용
- GAT / GATv2 model 구현
GAT Layer (num_head m만큼 병렬적으로 두어 multi-head 구현)
αij=∑k∈Niexp(LeakyReLU(alT⋅[Wlhi(l)∣∣Wlhj(l)]))exp(LeakyReLU(alT⋅[Wlhi(l)∣∣Wlhj(l)]))
⋯ weight factor of node j's message to node i
(a: shared weight vector, W: shared linear transformation,
Wlhi(l): l-layer에서 node i의 message)
hi(l+1)=AGG1≤m≤M(σ(∑j∈NiαijmWlmhj(l))) ⋯ multi-head attention
*Shared weight vector a를 nonlinear layer 밖으로 빼면 dynamic attention(GATv2)
Lab #5: Knowledge Graph Embeddings
- FB15K237 dataset 사용
- nn.Embedding 함수로 TransE, DistMult 구현
- Rank-based metric으로 evaluation 수행
- Negative samples 생성함수 구현
TransE
fr(h,t)=−∣∣h+r−t∣∣
DistMult
fr(h,t)=hTdiag(r)t ⋯ pairwise interactions