1. Outline
- Research(새로운 algorithm 제시/새로운 문제 해결/기존 문제를 새로운 방식으로 해결, 30점 만점)와 Survey Project(수업에서 다루지 않은 3가지 이상의 method 발표, 25점 만점) 중 택1.
- 5/20(토) 13:00까지 Project Draft(Title, Problem statement, High-level idea, Experimental Results 포함) pdf(ppt) 제출
- 5/22(월) 09:00-09:07 교수님 개별미팅
- 5/30(화) 13:00까지 [README, source codes, datasets, environment file] + [Poster pdf(ppt)] 최종 제출
2. Topic Candidates
#1. (Dataset O) - SELECTED!!
Node: 특정 status를 공유한 모든 twitter users
Feature: N/A
Edge: Follower subscriptions (directed)
'COVID-19와 5G 간 관련성에 대한 conspiracy가 포함된 subgraph' dataset을 통해 근거 없는 conspiracy가 전달되는 형태를 학습하여 임의의 status에 대한 subgraph를 전달했을 때 해당 status가 conspiracy를 포함하고 있을 확률을 추측(regression)
#2. (Dataset X, Street network data는 많음)
Node: 각 지역
Feature: 지역의 위도 및 경도, 지역의 인구밀도 등
Edge: 지역을 연결하는 도로(undirected)
잘 설계되었다고 평가받는 도시의 도로망 분포를 학습하여 대전 도로망을 제시하였을 때, 새로 연결하면 좋을 도로의 위치를 제안(link prediction)
#3. (Dataset X)
Node: 카이스트 학생들
Feature: TBD
Edge: TBD
카이스트 내부의 dataset을 활용한 task를 수행하면 좋을 것 같은데.. 학생들의 이수과목 정보와 연구실에서 출간한 논문의 분포를 기반으로 맞춤형 연구실 추천 시스템..? 아니면 맞춤형 동아리 추천 시스템....? 혹은 동아리 clustering: 어떤 동아리들 간의 거리가 가까운가?
#4. (Dataset O)
Node: 마블 코믹스 등장인물
Feature: 등장하는 만화책의 종류 (권 수)
Edge: 같은 만화책에 등장했다면 연결
등장빈도를 인물의 중요도를 평가하는 수치로 두어 임의의 인물에 대한 중요도 예측 (스타워즈 dataset가 더 구체적으로 구성되어 있음)
3. Topic Refinement #1
Topic
SNS 상에서 conspiracy가 담긴 정보의 전파 패턴 분석 및 예측 모델 연구
or, SNS 상의 특정 주제에 대한 전파 패턴 분석 및 예측 모델 연구
Problems
- SNS 상의 게시글들은 일반적으로 짧은 텍스트로 구성되어 있거나 다른 글의 내용을 암시하는 경우가 많아 내용 자체만으로 명확한 맥락과 작성 의도를 파악하기엔 한계점이 존재.
- 근거가 불충분한 conspiracy와 일반적인 사실 정보가 각각 SNS 상에서 전파되는 추이에 차이점이 있고, 이를 GNN 모델이 학습할 수 있다면, 임의의 정보에 대한 전파 추이를 확인하여 conspiracy가 담겨있을 확률을 정량적으로 제시할 수 있을 것으로 기대됨.
- 해당 task를 수행하기 위해 필요한 feature를 사용자의 팔로워 수, 원글과 리트윗 글 사이의 시간 간격 등으로 다양하게 두어 각 정보의 유용성도 파악할 계획.
Dataset Info
- [출처] Kaggle) 'Covid-19 Misinformation Tweets Labeled Dataset'
https://www.kaggle.com/datasets/arashnic/misinfo-graph (코로나가 중국 우한 지역에만 제한되어 있던 01JAN20~15JUL20 기간의 conspiracy. 영국 등의 5G 기지국에 대한 방화 사건을 야기함)
"This dataset can be used to train graph-based misinformation detection methods." (그래프 기반 검출 방법을 위한 dataset) - 5G 무선 네트워크와 COVID-19 간의 상관성을 주장하는 conspiracy가 퍼지는 Twitter's follower network(subgraph).
- 5G-Corona Conspiracy: 5G와 COVID-19 간의 인과관계가 담긴 글에 대한 subgraph.
- Other Conspiracy: 5G 이외의 COVID-19 관련 conspiracy가 담긴 글에 대한 subgraph.
- Non-Conspiracy: 앞선 두 경우를 제외한 임의의 subgraph. 사실 정보가 담겨있을 수도, 거짓 정보가 담겨있을 수도 있음.
Related Materials
- Node Embedding
- Node Feature: Constant features, One-hot vector, Retweeted time, friend/follower # 등으로 설정 가능
- GCN: Layer 수(=1?), aggregator 종류 설정(node feature를 constant하게 두면 GraphSAGE, friend/follower # 등으로 distinguish하면 GATv2가 적합해보임.)
- Graph-Level Prediction
- Graph 상의 모든 node embedding을 pooling(mean/max/sum). (Graph의 depth가 깊지 않기에 hierarchical pooling은 불필요해 보임)
- Conspiracy/Non-conspiracy의 supervised classification task. (혹은 specific topic/other topics)
Related Works
'WICO Graph: A Labeled Dataset of Twitter Subgraphs based on Conspiracy Theory and 5G-Corona Misinformation Tweets'
-
Misinformation은 실제 사회에 큰 악영향을 미치기에 이를 자동으로 감시하는 시스템이 갖춰져야 함. 이를 위한 labeled dataset을 구축함.
: 본 논문의 목표는 misinformation의 내용을 식별하는 것이 아닌, 그 전파 구조를 학습하는 그래프 기반 접근 방식에 대한 연구. Dataset의 내용보다 그래프의 구조에 초점을 둚. -
원글 A에 대한 리트윗 B를 또다시 리트윗(C)하는 경우, B와 C는 A 중심의 subgraph를 구성함과 동시에 B 중심의 subgraph도 새롭게 생성됨. 이 때, Twitter API의 제한에 따라 node의 최대 개수는 100개로 제한됨. + 팔로워 수는 익명성 보호를 위해 2의 제곱수로 근사.
-
Conspiracy subgraph의 경우, retweet한 user가 원글의 정보를 믿고 있다는 인상을 주는 경우(타당한 가설로 제시하는 경우)에만 node로 추가하였음.
-
Relativity가 크진 않지만, non-conspiracy subgraph가 낮은 average degree, 높은 clustering coefficient를 가지며 정보가 천천히 전파되는 특징을 지님.
: Conspiracy theories가 smaller & densely connected groups간에 더 집중적으로 전파되는 성향. -
각 카테고리의 각 subgraph에 대해, largest connected component의 크기와 그에 속하지 않는 노드의 수를 plotting.
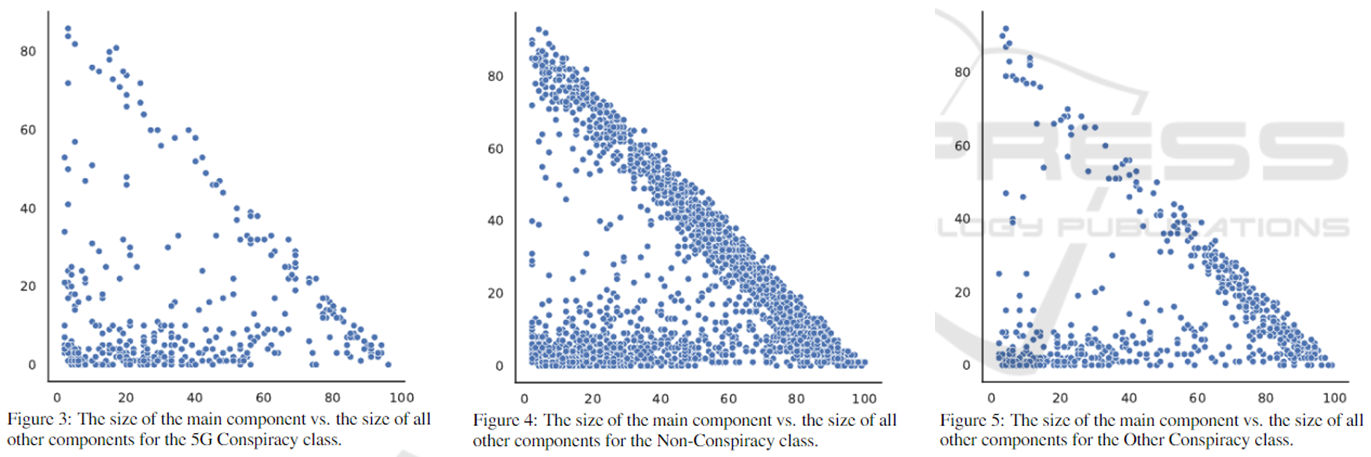
: Non-Conspiracy class의 경우 diagonal한 분포를 비교적 많이 보임. (Conspiracy class가 follower 간 폐쇄적 전파 형상을 나타내는 것으로 해석 가능. Global clustering coefficient가 작은 것도 일관된 결과.)
-
한계점. Following 기반 subgraph이기에 전파되는 경로가 직접적으로 나타나지는 않음. Conspiracy가 전파되는 구조가 구별되지 않을 수도 있음.
-
Baseline Experiments
: 1) Naive Bayes, 2) Random Forest Classifier, 3) GNN(Errica et al., 2020) 사용.
: Node#, Edge#, Radius(longest shortest path from origin), average CC를 subgraph feature로 활용.
: Graph Isomorphism Network (GIN) (Xu et al., 2018) 모델이 GNN 중 가장 좋은 성능을 보이나 Naive Bayes와 Random Forest에 비해 부족하였음.
: 'As there are numerous types of GNNs a full investigation would be outside the scope of this paper.'
Dataset 논문에서는 GNN의 성능이 다른 classical approaches에 비해 많이 떨어지게 나왔는데, 수업시간에 배운 개념들을 활용하여 성능을 높여볼 순 없을까!
4. Topic Refinement #2
Dataset 논문과 동일한 task에 parameter tuning만 추가한다고 논문의 수치를 상회하는 성능이 나올 것 같지 않음.
- 각 status에 대한 subgraph를 임의의 vector로 embedding을 한 뒤 하나의 node로 취급할 수 있을 것.
- 서로 다른 subgraph를 공유하는(두 status를 모두 retweet한) user가 있기에 subgraph node간 edge도 생성 가능(공유하는 user가 있는 경우 undirected edge 생성, 해당 user의 수로 weight 부여도 가능).
- 그렇게 구성된 통합 graph 상에서 edge prediction, 즉 두 subgraph를 공유하는 user가 존재할 확률 예측을 GNN에게 부여.
- 'Conspiracy theory를 공유한 user가 또다시 다른 conspiracy theory를 공유할 확률이 non-conspiracy를 공유할 확률보다 클 것이다'라는 가설을 입증할 수도 있을 것으로 보임.
New Topic
Link Prediction Among Subgraphs: Based on Twitter Subgraph Related to the Spread of 5G-COVID19 Conspiracy Theories
//
Q. Link prediction을 위해 negative example에 대한 값을 최소화하는 방향으로 model을 학습시킬텐데, future link probability를 추측하기 위해 해당 값을 이용하는 것이 모순되지는 않는가?
A. 학습 과정에서 사용되는 margin-based ranking loss는 negative edge를 완전히 틀린 edge로 가정하는 것이 아니라, negative edge 대비 positive edge의 score를 높이는 방향으로 학습이 진행됨. 따라서 semantic embedding이 학습되어 예측 단계에서는 새로운 link를 예측할 수 있는 것.
추가로, 현 graph에 존재하는 link에 대한 prediction task도 학습 과정에선 test edge가 없다는 전제 하에 학습이 이뤄지므로 future link prediction과 동일한 task에 해당함.
//
5. Draft



6. Experiments
1. End-to-End pipeline의 LPAS 모델
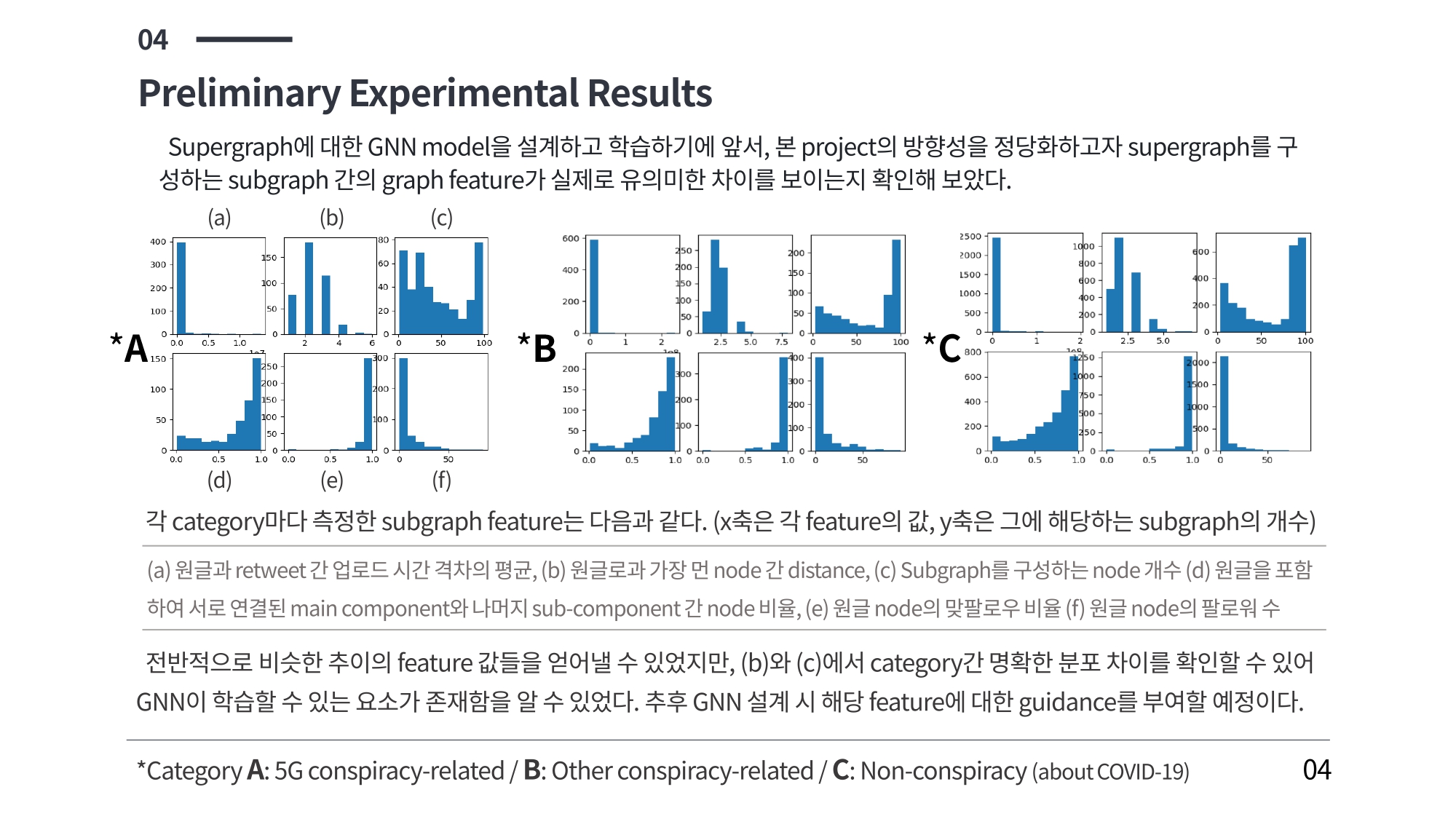
: Node features를 GATv2에 입력한 뒤 average pooling하여 subgraph의 implicit feature를 얻어내고, 이를 subgraph의 explicit feature와 concatenate한 뒤, edge prediction까지 일괄적으로 수행.
- 입력된 node의 feature는 time, friends, followers, CC.
- 이와 동일한 차원으로 embedding된 subgraph feature에 추가된 explicit subgraph feature는 time avg, time std, radius, node #, component ratio, following ratio.
- 모델이 최종적으로 출력하는 link likelihood 값은 실제 link의 유무와 비교한 mse loss 값으로 계산되어 모델의 학습에 사용.
2. Subgraph Embedding & Classification pipeline의 EMBDLPAS 모델
: Node features를 GATv2에 입력하여 얻어낸 subgraph의 implicit feature와 explicit feature로부터 class로의 classification task만 일차적으로 수행.
- End-to-end model 중 subgraph embedding pipeline에 적절한 guidance를 부여하여 학습을 개선시킬 목적으로 진행.
- 모델이 최종적으로 출력하는 classification likelihood 값은 실제 class에 대한 one-hot vector와 비교한 cross entropy loss 값으로 계산되어 모델의 학습에 사용.
- Mini-batch training scheme에 대해서도 성능 평가.
3. Link Prediction pipeline의 LINKLPAS 모델
: 앞선 pre-trained EMBDLPAS 모델이 출력해내는 subgraph embedding 값을 입력받아 link prediction을 수행.
- 앞선 end-to-end model과 학습방법 동일.
7. Results
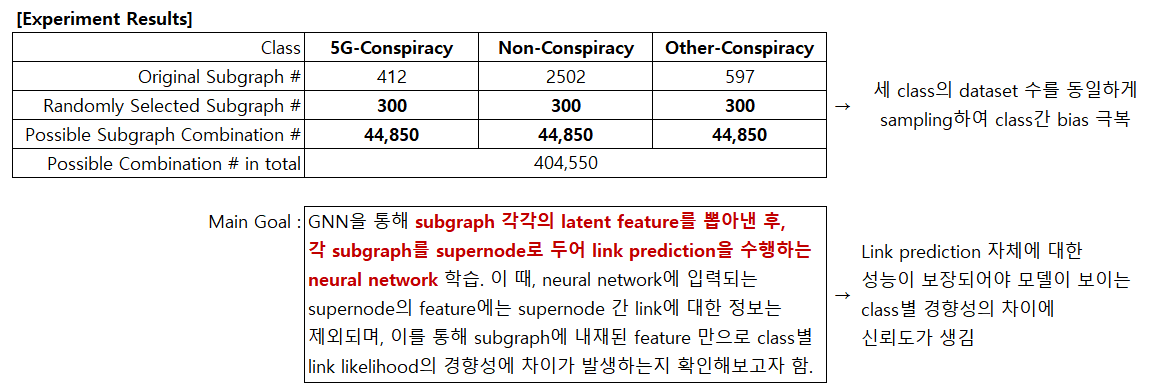
- 각각 412, 2502, 597개의 subgraph를 포함하는 5G conspiracy, non-conspiracy, other conspiracy의 dataset에 대해, class 간 불균형을 없애고자 300개씩의 subgraph를 무작위로 sampling하여 사용.
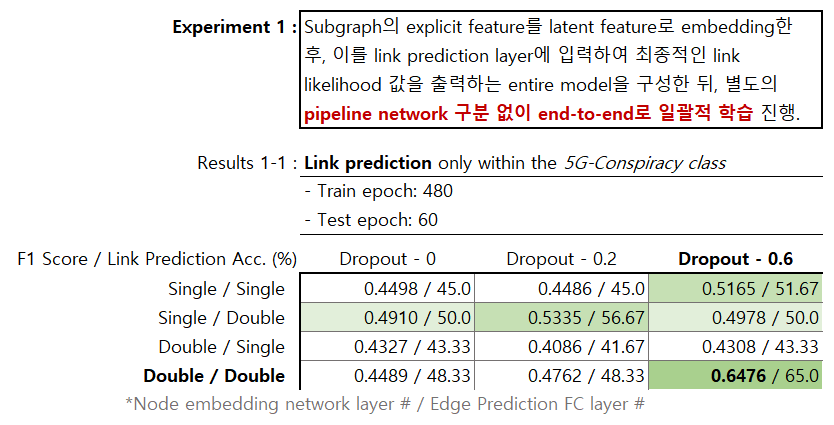
- End-to-end model에 대한 학습(structure / hyperparameter tuning). 5G conspiracy dataset에 대해 우선적으로 학습시켰으며, 'Double / Double / Dropout-0.6'의 모델이 가장 좋은 성능을 보임.
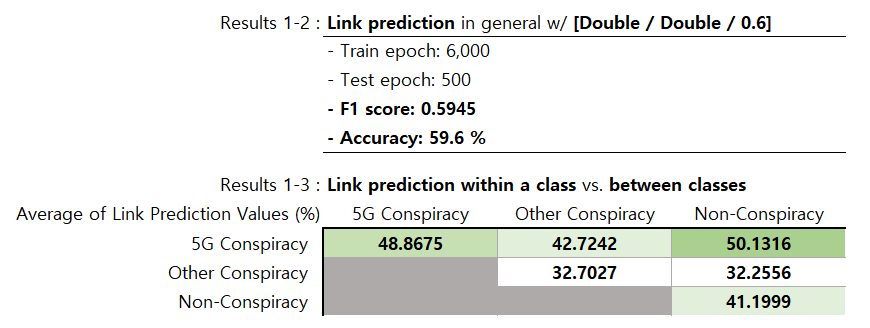
- 앞서 가장 좋은 성능을 보인 모델에 대해 모든 class에 대해 training epoch를 늘려 다시 학습. 0.5945의 F1 score를 보였으며, 5G conspiracy와의 link가 높은 likelihood 값을, other conspiracy와의 link가 낮은 likelihood 값을 보임.
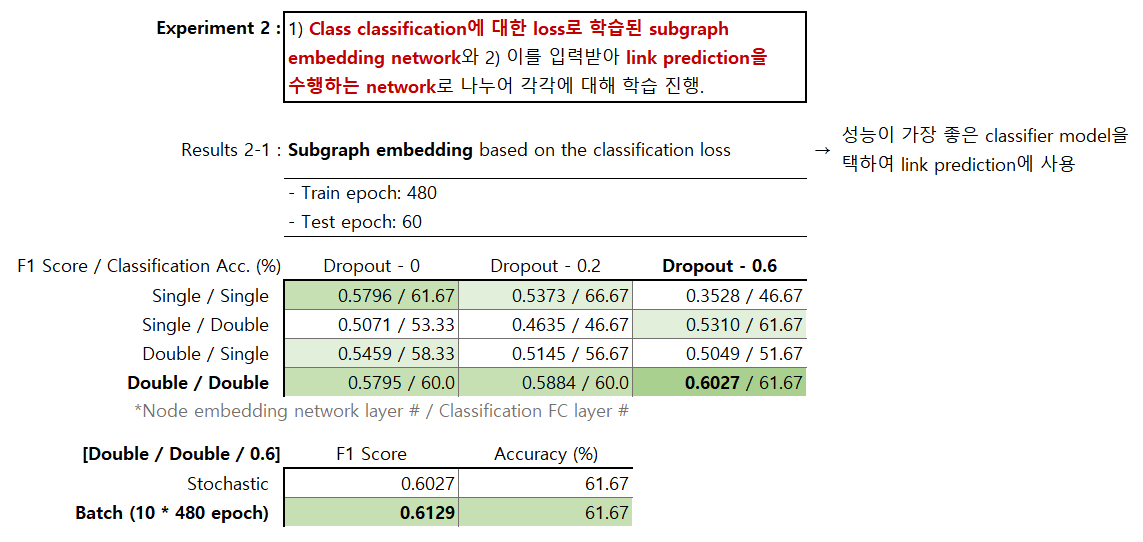
- End-to-end model의 앞단인 subgraph embedding model에 대한 학습. 모든 class의 dataset을 사용하였으며, 'Double / Double / Dropout-0.6' 모델이 가장 좋은 성능을 보임. 또한, batch 단위로 학습시켰을 때 약간의 성능 개선을 보임.
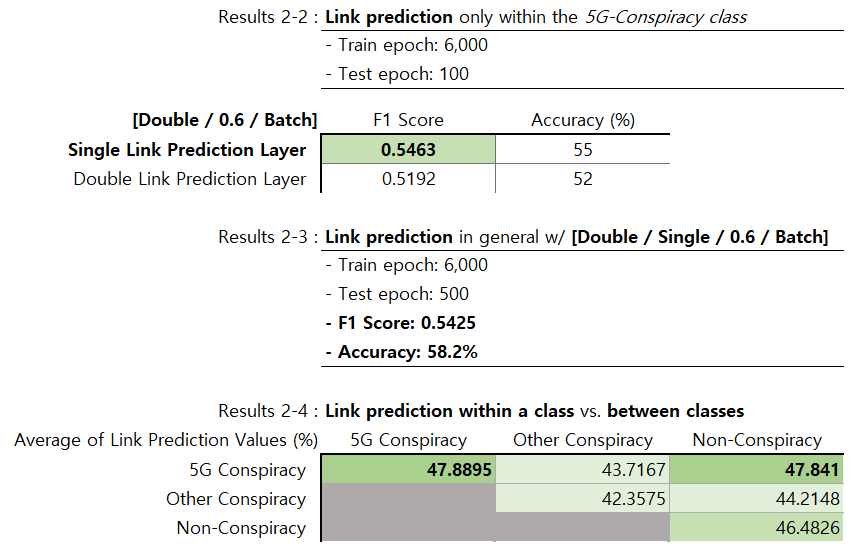
- 앞서 가장 좋은 성능을 보인 모델이 출력해내는 subgraph embedding 값을 활용하여, link prediction model을 따로 학습시킴.
- End-to-end 모델과 마찬가지로 5G conspiracy dataset에 대해 우선적으로 학습시켰으며, single link prediction layer를 갖는 모델의 성능이 비교적 좋았음.
- 따라서 single link prediction layer로 두어 전체 class에 대해 training epoch를 늘려 다시 학습시켰으며, 앞선 end-to-end model과 비슷한 link likelihood 분포를 보였으나 link prediction accuracy에서는 괄목할 만한 성능 개선이 이루어지지는 않음.
Link likelihood within 5G conspiracy class 값이 높은 것은 기존 가설과 일치하는 경향을 보여주며 link likelihood within other conspiracy 값이 가장 낮은 것은 해당 class의 특성상 서로 다른 주장의 conspiracy를 동일 사용자가 공유할 확률이 떨어질 수 있으므로 reasonable함.
다만, 5G-non conspiracy 간의 link likelihood 값이 높게 나오는 것은 5G conspiracy를 공유한 사용자가 사실 기반의 내용은 비교적 덜 공유할 것이란 기존 가설을 반증함. 이는 실제로 그러한 경향이 있을 수도, link prediction 자체의 성능 부족으로 인한 오차일 수도 있음.
8. Poster

Useful Websites
