Stable Diffusion model에 이어, 3/10(금)에 교수님께서 새롭게 내주신 논문을 리뷰해보기로 한다.
Scalable Neural Video Representations with Learnable Positional Features (Subin, Sihyun, et al. NeurIPS 2022)
논문 코드: https://github.com/subin-kim-cv/NVP
Introduction
- CNR(Coordinate-based Neural Representations)은 gigapixel images, audios, 3D scenes, large city-scale street views와 같은 complex signal을 coordinate grid 상이 아닌 parameterized neural network 상에서 compact하게 저장하는 방식이다.
- 특히, 최근 CNR을 video signal에 접목하려는 시도가 이루어지고 있으며, 이는 형태의 neural network, 즉 임의의 time 에 대한 좌표의 RGB pixel 값을 출력하는 함수를 학습시키는 것이다.
- 이는 복잡한 temporal dynamics와 커다란 spatial variation을 동시에 고려해줘야 하는 video의 특성상 어려움이 있는데, Chen et al.의 연구에서는 temporal dimension에 대해서만 modeling하는 방식으로 현존하는 video codec만큼의 성능을 이끌어내기도 하였다.
- 하지만 CNR의 가장 큰 한계점은 극심한 compute-inefficiency로, real world data에 적용하기 어려워진다.
- 이를 해결하기 위해 CNR을 1) coordinate-to-latent mapping (latent grids 로의 embedding function)와 2) latent-to-RGB mapping 의 단계로 나누어 해결하려는 시도도 이루어졌는데, 이는 input dimension에 따라 너무 많은 parameter가 소요된다는 문제점이 있다.
Contribution
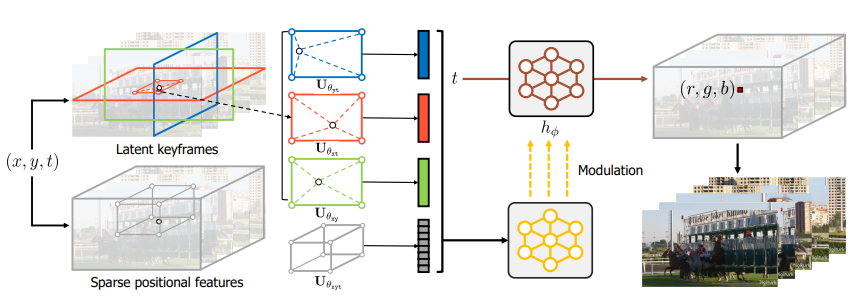
- 제안된 NVP(neural video representations with learnable positional features) 모델은 다음의 세 가지 contribution을 포함한다.
-
의 size의 full-dimentional 3D array 대신 learnable positional features를 도입한다.
, for- Latent keyframes : 는 각 spatio-temporal axis에 대해 video contents를 학습해 "image-like" 2D latent grid 로 mapping한다.
- Sparse positional features : 는 video pixel보다 작은 size로 local video detail을 학습해 "video-like" 3D latent grid 로 mapping한다.
-
기존의 image & video codec(JPEG, HEVC)을 활용하여 parameter 의 개수를 줄였으며, 이는 trained parameter에 대해 re-training이 불필요하므로 compute-efficiency도 높인다.
- 이는 기존의 hashing-based latent grid 방식에는 적용할 수 없다.
-
에서, temporal coordinate에 대해 modulated network를 사용하여 encoding quality를 높였다.
Related Work
Coordinate-based Neural Representations (CNRs)
- 흔히 multilayer perceptron (MLP)가 high-frequency sinusoidal activation 혹은 Gaussian activation과 결합되어 있는 형태로, signal을 neural network로 encoding하는 방식을 일컫는다.
- Video encoding에 대한 연구가 진행되고 있으나, 아직 부족한 편이다.
Hybrid CNRs
- Coordinate-to-RGB mapping을 대신하여 그 사이에 grid structure를 따르는 latent code를 두는 방식을 일컫는다.
- Grid-shaped latent code는 video의 locality를 유지하여 좋은 성능을 보이지만, 필요한 parameter의 개수가 data resolution에 비례하여 증가한다.
NVP: Neural Video Representations with Learnable Positional Features
- Goal: 주어진 video signal 에 대해, compact neural representation 을 학습하는 것.
1. Architecture
-
( )
-
Coordinate-to-latent mapping
: witha. Learnable latent keyframes
- Image-like 2D latent spatial grid 는 -level multi-resolution structure를 가지며( i.e. ), 각 spatial grid 은 , 의 size를 가진다. (coarse to fine)
for
다양한 크기의 동일한 객체에 대한 학습을 기대. - 예를 들어, 는 temporal axis에 대해 공통적인 특징들(ex. 배경, 워터마크 등)을 학습한다.
- 의 각 좌표에 해당하는 latent code 은 -dimensional vector에 해당하며, latent vector 은 가장 인접한 네 개의 latent code를 linearly interpolate한 값을 갖는다. (이 때, 주어진 좌표에 대한 grid의 relative position이 고려되며, 핵심은 latent code가 학습된다는 것과 across spatial axes에 대해서도 고려한다는 것.) and for NVP-S and NVP-L, respectively.

b. Sparse positional features
- Video-like 3D latent spatial grid 는 실제 video의 3D RGB grid보다 훨씬 작은 의 크기를 가진다.
for ShakeNDry, for UVG-HD - 의 각 좌표에 해당하는 latent code 는 -dimensional vector에 해당하며, latent vector 는 인접한 개의 latent code를 concatenate하여 구해진다. (는 hyperparameter에 해당한다.)
Sparse 3D grid 상의 latent code 하나만으로는 주어진 좌표에 대한 정보가 충분히 담기지 않아 여러 vector를 concatenate하였으며, linear interpolation은 computational cost가 증가하여 선택하지 않았다.
and for NVP-S and NVP-L, respectively. - 임의의 좌표에 대한 RGB 값을 구하기 위해 network 상의 모든 parameter를 활용했던 기존의 CNR과는 달리, 의 locality를 활용하여 계산 효율을 높였다.
정리하면, 아래의 표와 같다.
Latent keyframes Sparse positional features Grids "Image-like" 2D latent grids
L-level multi-resolution structure"Video-like" 3D latent grid Latent codes 각 grid에 대해, -dimentional vector 이 만큼 존재 -dimentional vector 가 만큼 존재 Latent vector 는 각각 가까운 네 개의 latent code 를 linear interpolate한 값에 해당 는 가까운 개의 latent code를 concatenate한 값에 해당 - Image-like 2D latent spatial grid 는 -level multi-resolution structure를 가지며( i.e. ), 각 spatial grid 은 , 의 size를 가진다. (coarse to fine)
-
Latent-to-RGB mapping
:- Latent vector 를 값으로 mapping하는 과정에 Multi-Layer Perceptrion(MLP)을 적용하는 것이 일반적이지만, 동적인 video에 대해서는 expressive power가 떨어진다.
- 따라서, -layer MLP의 synthesizer network와 별도의 modulator network를 병렬적으로 두어 latent vector 와 time coordinate 를 각각 통과시키는 방법을 택하였다.
K=3, ||
a. Modulated implicit function
- Synthesizer(-layer MLP)는 -1번째 layer에서 전달된 값을 변형하는 weights 와 bias 로 구성되어 있으며, sinusoidal activation을 사용한다.
- 반면 modulator는 각 번째 layer에 대한 hidden feature 로 구성되어 있으며, ReLU와 같은 piecewise linear activation(LeakyReLU)을 사용한다. 이를 수식과 그림으로 나타내면 아래와 같다.
for

2. Compression procedure
- Parameter 수를 줄이기 위해 training 후 magnitude pruning이나 quantization 등을 접목한 기존의 아이디어는 CNR parameter에 대한 재학습이 수반되어 커다란 computational cost가 필요했다.
- Magnitude pruning: 특정 값을 기준으로 weight 값을 thresholding하는 방법. 보통 학습 후 pruning을 진행한 sparse network에 대하여 학습을 다시 수행한다(iterative pruning).
- Coordinate-to-latent mapping 의 parameter를 줄이는 것이 핵심이며, 현존하는 image & video codec(HEVC, JPEG)을 활용해 latent spatial grids 를 8-bit latent code로 quantize하였다.
Experiments
- UVG-HD의 7개 video에 대해 성능을 측정(각 frame에 대한 값을 전체 video에 대해 평균)하여 평균내었으며, metric으로는 PSNR, LPIPS, FLIP, SSIM을 사용하였다.
- Encoded video와 원본 간의 perceptual similarity를 측정하는 LPIPS 수치를 크게 향상시켰으며 모델의 robustness에 해당하는 variance 값도 작았다.
- Applications: Video inpainting, video frame interpolation, video super-resolution, video compression에 좋은 성능을 보였다.
- Sparse positional features 는 latent code 간의 non-smooth transition을 완화시키고, video의 sharp detail을 학습하는 것으로 해석하였다. 또한, 상에서 linear interpolation을 적용하면 더 smooth한 pattern을 보이지만, 학습시간이 1.61배 소요되었다.
Discussion and Conclusion
- Video의 특성에 맞게 architecture나 hyperparameter를 변형하면 더 좋은 성능을 기대해볼 수 있을 것이다.
Appendix
Baseline methods
- SIREN: High frequency sine activation을 적용해 로 mapping하는 모델.
- FFN: Random fourier feature를 활용하여 positional embedding layer를 구성하고, ReLU activation을 적용한 모델.
- NeRV: Video에 특화된 CNR 모델로, time index를 입력받아 그에 해당하는 RGB image를 출력.
- Instant-ngp: Trainable feature vector로 구성된 multiresolution hash table을 활용하는 모델.
추가로 고민해봐야 할 것
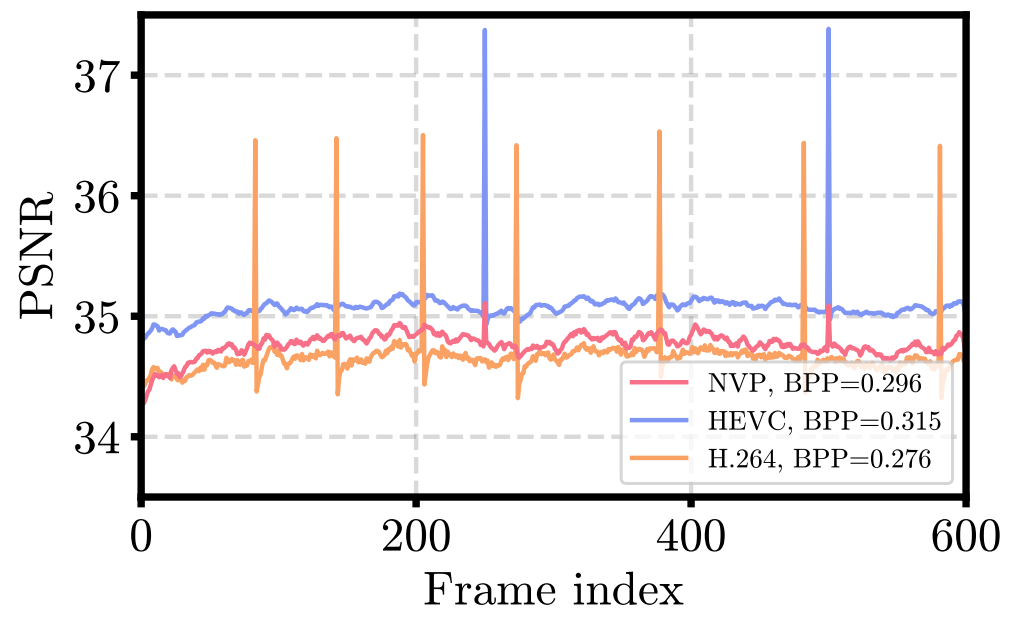
NVR 모델은 압축에 특화되어 있지는 않기 때문에 현존하는 다른 video codec에 비해선 다소 떨어지는 reconstruction 성능을 보여준다. 압축에 특화되도록 아이디어를 발전시켜 본다면?

K'AI'ST 학부생까지의 기록