앞선 'NVP2(1) - Ideas proposal on sparse positional features' 글에서 나열한 아이디어를 하나씩 살펴보며 구현 및 실험해보도록 한다.
1. Sparse Positional Features Optimization
Codec이 효율적으로 압축할 수 있는 형태로 3D latent grid를 재설계해보기! YUV space에서의 fitting도 고려해볼 것.
사실 높은 압축률으로 압축될 수 있는 video는 spatial, temporal information이 적은 형태일 것이고 임의의 tensor로 학습된 spatial positional features의 정보량을 유지하며 해당 형태로 변환하는 것은 불가능..?해보인다.
또 어차피 codec이 곧바로 YUV space로 변환해주지 않나..? 우선 이 아이디어는 패스.
2-1. Codec Choice: Various Codecs
현 3D latent grid에 적합한 새로운 codec 탐색하기! 저화질 비디오 전용 codec이나 흑백 비디오 전용 codec 등을 시도해볼 것.
기존 모델에서 codec compression을 하기 이전에 (NVP-S 기준) 32-bit floating-point format의 Tensor로 이루어진 (300, 300, 600) size의 sparse grid를 8-bit로 quantize한 후, png 파일로 저장한다. 이 때, 각 위치좌표마다 하나의 값만 저장되므로, single-channel의 흑백 사진이 저장된다. 따라서 RGB video에 적용되는 HEVC codec 대신 grayscale video에 특화된 codec 모델을 사용하면 이점을 누릴 수도 있어 보이는데.. 우선 grayscale image나 video만을 위한 specialized codec은 따로 없는 것 같다.
우선 ffmpeg에서 사용 가능한 아래 codec들에 대해 압축을 시도해보고 성능을 측정해보도록 한다.
('compression.ipynb' 파일에서 ffmpeg 커맨드 codec 변경, save_path에서 dst_codec_name으로 변경, 'eval_compression.py' 파일 실행 시 --codec codec_name argument 추가)
# List all encoders of FFmpeg
ffmpeg -encoders
# View more details on an encoder
ffmpeg -h encoder=libx264V.S... ffv1 FFmpeg video codec #1
V..... h261 H.261
V.S... mpeg1video MPEG-1 video
V.S... mpeg2video H.262 / MPEG-2 video
V..... h263 H.263 / H.263-1996
V.S... h263p H.263+ / H.263-1998 / H.263 version 2
V..... libx264 libx264 H.264 / AVC / MPEG-4 AVC / MPEG-4 part 10 (codec h264)
V..... libx265 libx265 H.265 / HEVC (codec hevc)
V..... pgm PGM (Portable GrayMap) image
V..... libvpx libvpx VP8 (codec vp8)
V..... libvpx-vp9 libvpx VP9 (codec vp9)
[Baseline]
w/o codec: BPP: 0.8754 / PSNR: 40.11
hevc: BPP - 0.1782 / PSNR - 37.01
w/o codec(288x352 sparse grid): BPP - 0.9632 / PSNR - 40.23
hevc(288x352 sparse grid): BPP - 0.1360 / PSNR - 36.15
- ffv1: ('.avi' 확장자로 저장) BPP - 0.5009 / PSNR - 39.42
- h261: ('.avi' 확장자로 저장, 352x288 size로 sparse grid 수정하여 다시 학습) BPP - 0.07047 / PSNR - 27.30
(The specified picture size of 300x300 is not valid for the H.261 codec. Valid sizes are 176x144, 352x288.) - mpeg1video: BPP - 0.0675 / PSNR - 28.97
- mpeg2video: BPP - 0.0675 / PSNR - 28.83
- h263: ('.avi' 확장자로 저장, 352x288 size로 sparse grid 수정하여 다시 학습) BPP - 0.06889 / PSNR - 29.04
(The specified picture size of 300x300 is not valid for the H.263 codec. Valid sizes are 128x96, 176x144, 352x288, 704x576, and 1408x1152. Try H.263+.) - h263p: ('.avi' 확장자로 저장) BPP - 0.06803 / PSNR - 28.54
- libx264: BPP - 0.1295 / PSNR - 35.71
- libx265: BPP - 0.1246 / PSNR - 35.74
- pgm: ('.pgm' 확장자로 저장 후 'eval_compression.py'에서 모든 frame의 압축 파일을 nparray 형태로 불러오도록 수정) BPP - 0.7529 / PSNR - 39.42
- libvpx: ('.webm' 확장자로 저장) BPP - 0.06804 / PSNR - 31.37
- libvpx-vp9: ('.webm' 확장자로 저장) BPP - 0.4014 / PSNR - 37.38
2-2. Codec Choice: RGB Sparse Grid
그렇다면 반대로 temporal axis 상에서 인접한 세 frame에 대한 3D grid 값을 묶어 rgb space로 저장한 후 압축해준다면..?
이에, compress_sparse_grid 함수를 아래와 같이 수정 후 압축을 진행하였다.
outputdata = np.array(quantized_tmp_features) # [f, h, w] = [600, 300, 300]
outputdata = np.moveaxis(outputdata, source=0, destination=-1) # [h, w, f] = [300, 300, 600]
for i in range(t_resolution // 3):
cv2.imwrite(os.path.join(tmp_save_path, f"{str(i).zfill(5)}.png"), outputdata[:,:,3*i:3*i+3]) # [300, 300, 3]기존의 압축 방식이 600장의 png 파일을 생성하였다면, 수정된 압축 방식은 인접한 세 frame을 한 장의 rgb image로 합치기 때문에 200장의 png 파일만을 생성한다. 아래는 해당 png 파일 중 하나로, 인접한 세 frame의 공통된 부분은 grayscale로, 차이가 나는 부분은 특정 색상으로 표현되고 있음을 확인할 수 있다.

BPP : 0.1043(41.5% 감소), PSNR: 34.13(7.78% 감소)
(cf. 기존 모델 BPP : 0.1782, PSNR: 37.01)
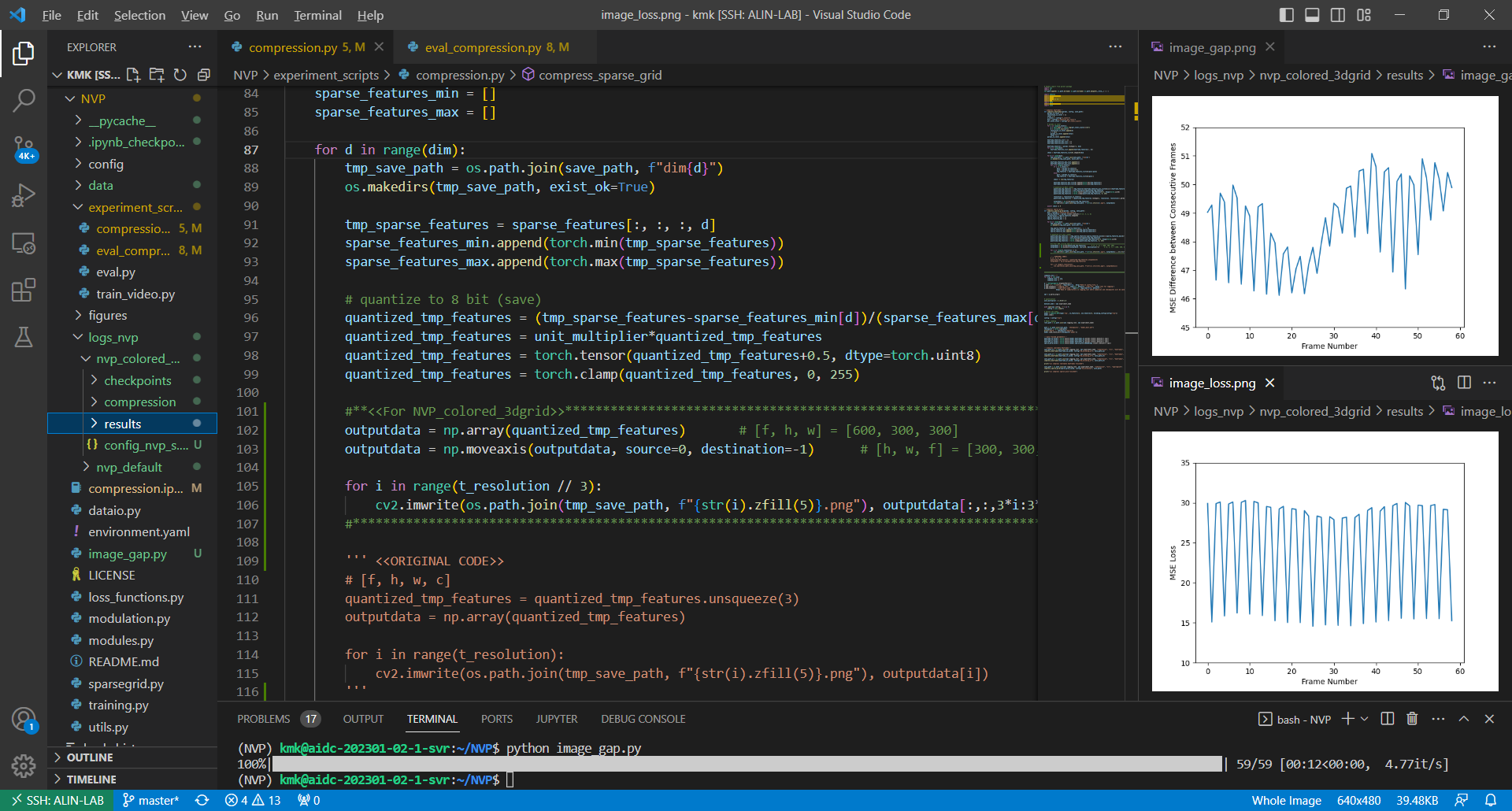
BPP score가 약 41.5% 감소하는 동안, 성능 하락은 단지 7.78%에 그친 것을 확인할 수 있었다. 성능 하락의 원인을 살펴보고자 각 frame마다의 MSE loss를 plotting 해보았다.
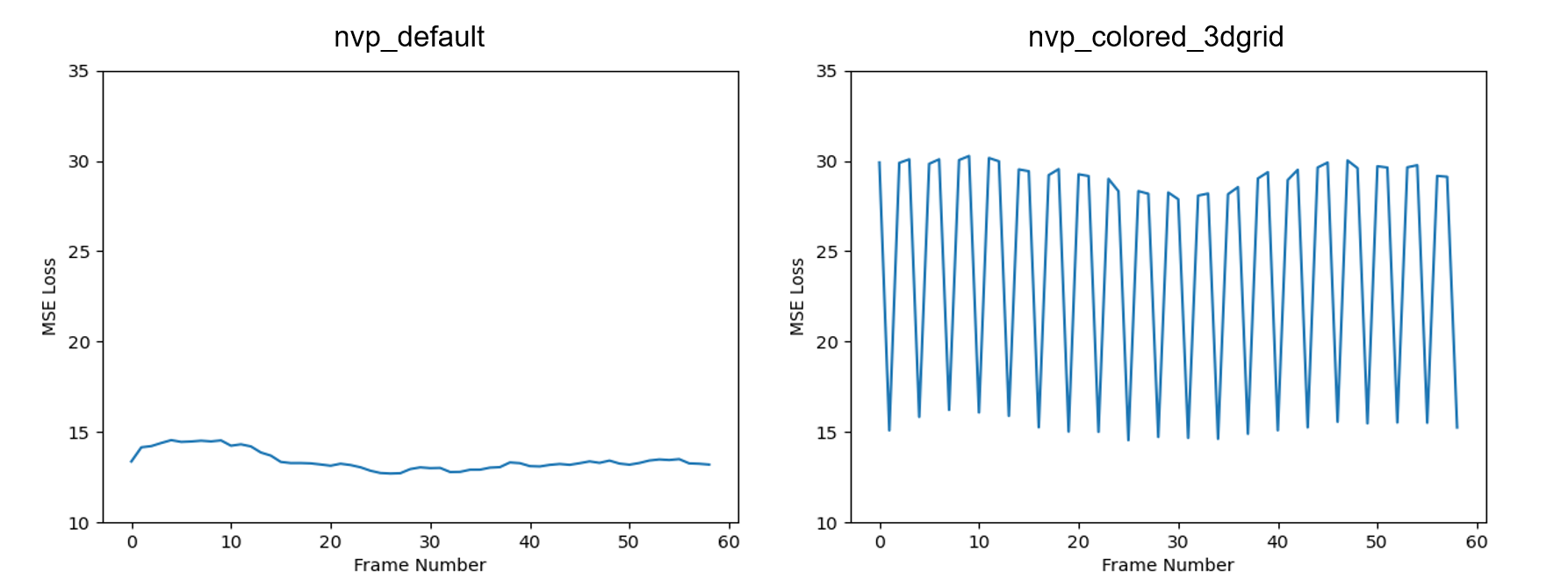
nvp_colored_3dgrid 모델에서의 frame-wise MSE loss 값의 추이를 보면, 세 frame씩 묶었을 때 가운데 frame의 양 옆 frame들의 loss 값이 크게 증가한 것을 확인할 수 있었고, PSNR score의 하락은 해당 부분에서 기인하였다고 볼 수 있다. 3D sparse grid의 각 frame을 세 frame씩 묶어 rgb image의 형태로 저장하였으므로, 각 frame을 R, G, B-frame이라 칭한다면, R, B-frame의 loss 값이 증가한 셈이다. 실제로 임의의 3k, 3k+1, 3k+2 번째의 frame의 화질을 비교해보면 아래와 같이 3k+1 번째 frame이 가장 선명한 것을 확인할 수 있다.

이는 codec이 RGB frame을 YCbCr 형태로 변환하며 사람의 눈이 둔감한 chroma(색차) 성분을 줄이는 chroma subsampling을 진행하는데, 가운데 G-frame을 기준으로 R, B-frame의 성분 차이가 image 상으로는 색으로 나타나기 때문에 해당 정보의 손실이 비교적 크게 발생한 것으로 예상된다.

3-1. Tensor Decomposition: CP-Decomposition
Codec을 사용하는 환경과 사용하지 않는 환경 모두에 대해 CP-decomposition이 압축률 및 성능에 얼마나 영향을 주는지 실험해보기!
Tensor decomposition 연산은 아래와 같이 설치한 TensorLy 패키지를 기반으로 구현하였다.
git clone https://github.com/tensorly/tensorly
cd tensorly
pip install -e .우선 학습된 3D latent grid에 대해, 아래와 같은 CP-decomposition을 적용하여 3개의 2D matrix로 분해한 뒤 이를 다시 합성하여 성능을 측정해보았다.
CP-Decomposition
CP-decomposition의 rank는 최소 10부터 최대 300까지 10 간격의 모든 값에 대해 수행 후 결과를 기록하였으며, 그에 대한 PSNR-BPP plot은 다음과 같았다.
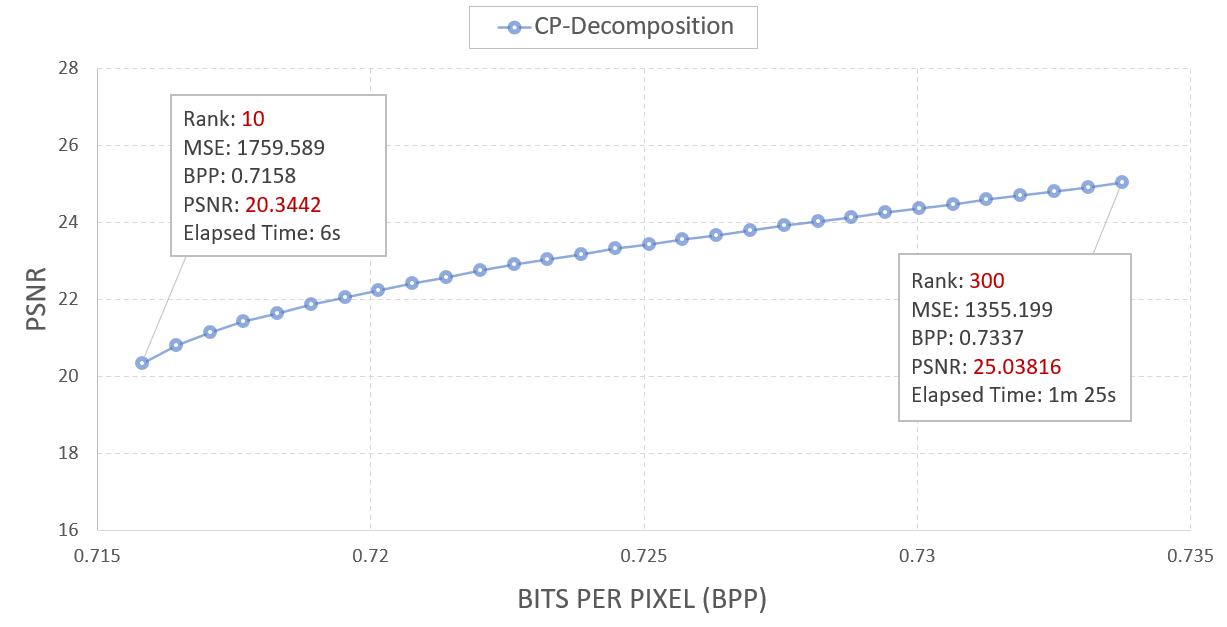
CP-decomposition의 rank에 따라 BPP 값이 비교적 작게 변화함을 알 수 있으며, 압축률 면에서만 보았을 땐 훌륭한 성능을 거두었다. 이를 latent grid quantization(32bit 8bit)을 수행한 결과와 비교해보면 아래와 같다.
| Metric | Quantization(8bit) | CP-Decomposition |
|---|---|---|
| MSE Loss | 41.13 | 1365.81 |
| BPP | 0.8754 | 0.7337 |
| PSNR | 40.11 | 24.74 |
표에서도 볼 수 있다시피 quantization에 비해 BPP 값을 더 큰 폭으로 줄일 수 있었지만, PSNR 값 면에서는 비교적 좋지 못한 결과를 보였다. 실제로, CP-decomposition의 결과값으로 다시 video를 생성하였을 때 임의의 frame을 살펴보면 아래와 같다.


Quantization만 진행한 모델과 sparse positional features를 비교해봤을 때, high-frequency detail은 대부분 손실된 것을 확인할 수 있었다. 이는, video의 형태가 600x300x300으로 크게 비대칭적이기 때문에, 정해진 rank 값에 대한 분해 과정에서 temporal axis에 대한 정보 손실량이 큰 것으로 판단하였다. 따라서, 300x300x300 크기로 나누어, CP-decomposition을 각자 진행한 뒤 다시 합치는 방식도 시도해보았으며 그 결과는 아래와 같았다.
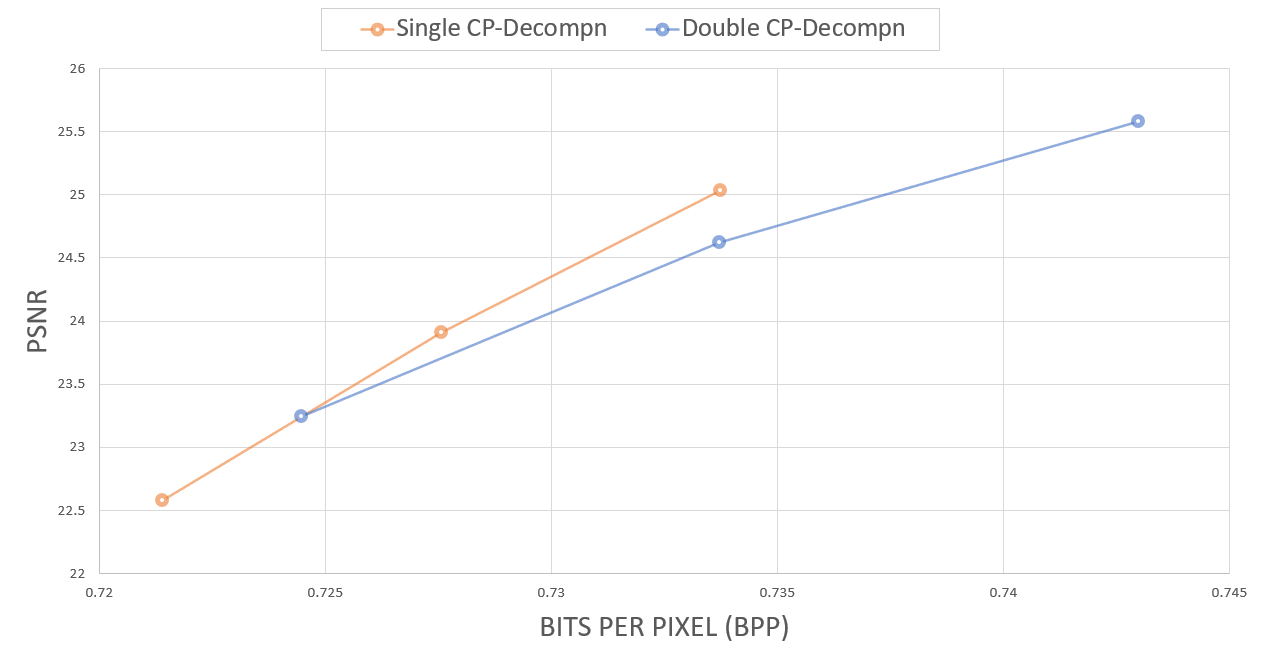
기존의 방법에 비해 PSNR 값이 조금 오른 것을 확인할 수 있었지만, 실제 결과물의 변화를 인지하기도 어려워 괄목할 만한 결과는 아니었다. CP-decomposition은 아무래도 정보 손실량에 있어 한계가 있어 보인다.
3-2. Tensor Decomposition: Tucker Decomposition
Codec을 사용하는 환경과 사용하지 않는 환경 모두에 대해 Tucker decomposition이 압축률 및 성능에 얼마나 영향을 주는지 실험해보기! Tucker decomposition으로 후처리된 sparse grid를 활용한 neural net initialization도 시도해볼 것.
앞선 방법과 비슷하게, 우선 quantization 없이 Tucker decomposition만을 적용해보았으며, 결과는 다음과 같았다.
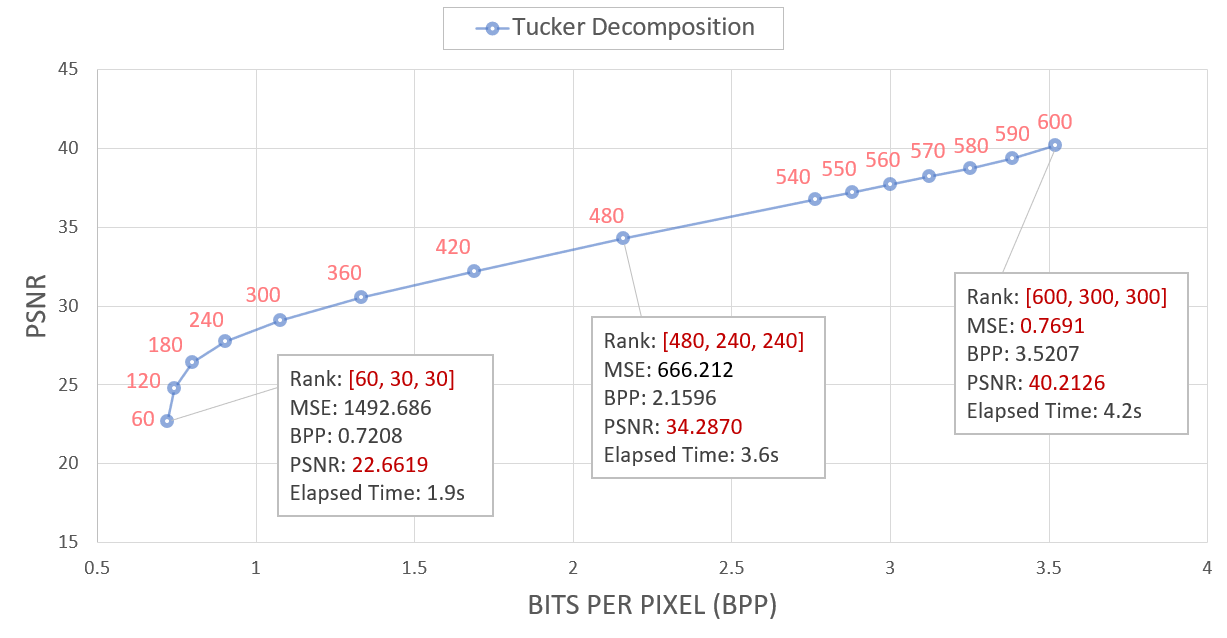
| Metric | Quantization(8bit) | Tucker Decomposition(Rank 480, 240, 240) |
|---|---|---|
| MSE Loss | 41.13 | 666.2 |
| BPP | 0.8754 | 2.1596 |
| PSNR | 40.11 | 34.29 |
기존 40대의 PSNR 값에서 core tensor의 rank를 절반으로만 낮춰주어도 30 아래의 PSNR 값을 보임을 확인할 수 있다. 이를 앞선 CP-decomposition에서의 결과값과 함께 plotting하면 아래와 같다.
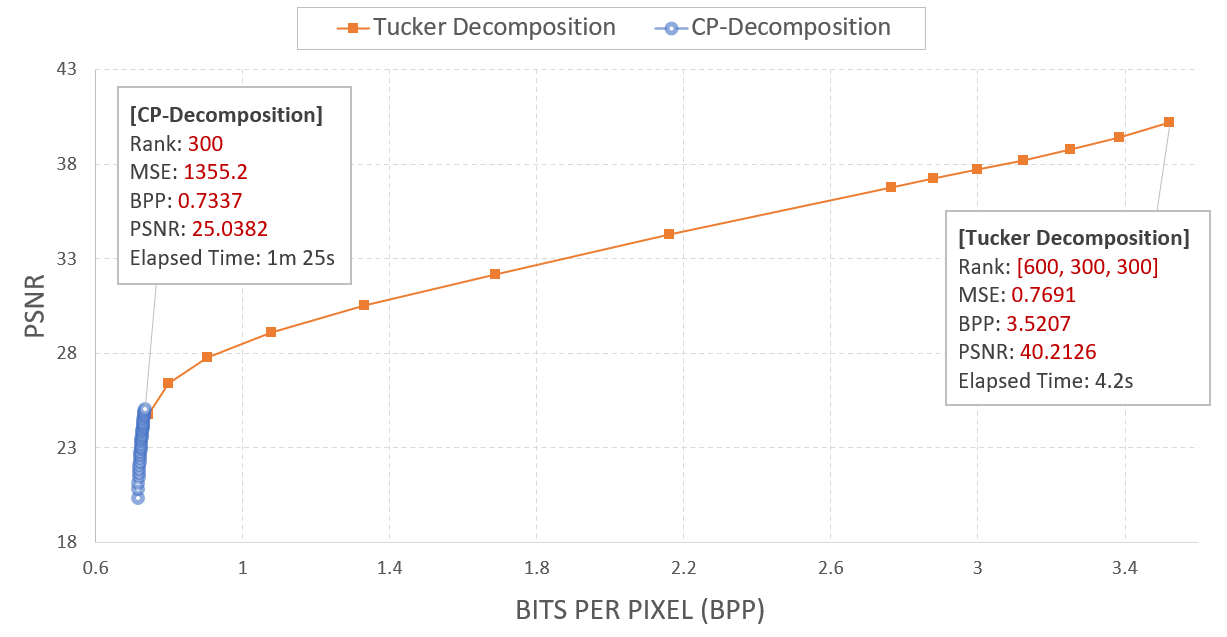
예상할 수 있었듯이, CP-decomposition은 상대적으로 압축률은 높으나 그만큼 정보손실이 컸고, Tucker decomposition은 비교적 적은 압축률을 보이긴 했으나 실용적인 PSNR 수준을 유지하면서 BPP 값을 유의미하게 낮추진 못했다.
