2/27(월)에 교수님의 연락을 받아, 3/10(금)에 'Stable Diffusion' 모델에 관해 발표하기까지 공부한 내용을 아래의 순서로 정리해보도록 한다.
- Generative Model Basics (VAE, GAN)
- Diffusion Models (DDPM, DDIM)
- Conditioning Algorithms (Attention, Classifier-Free Guidance)
- Stable Diffusion
Generative Models
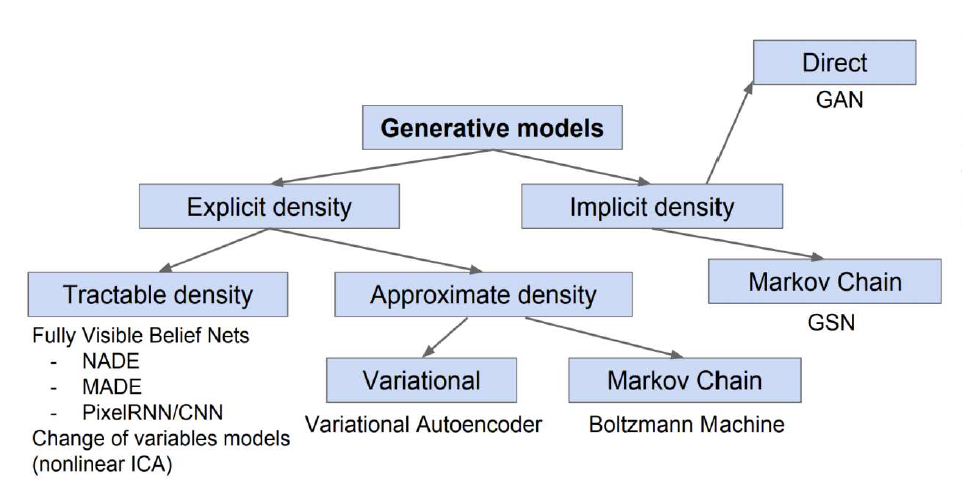
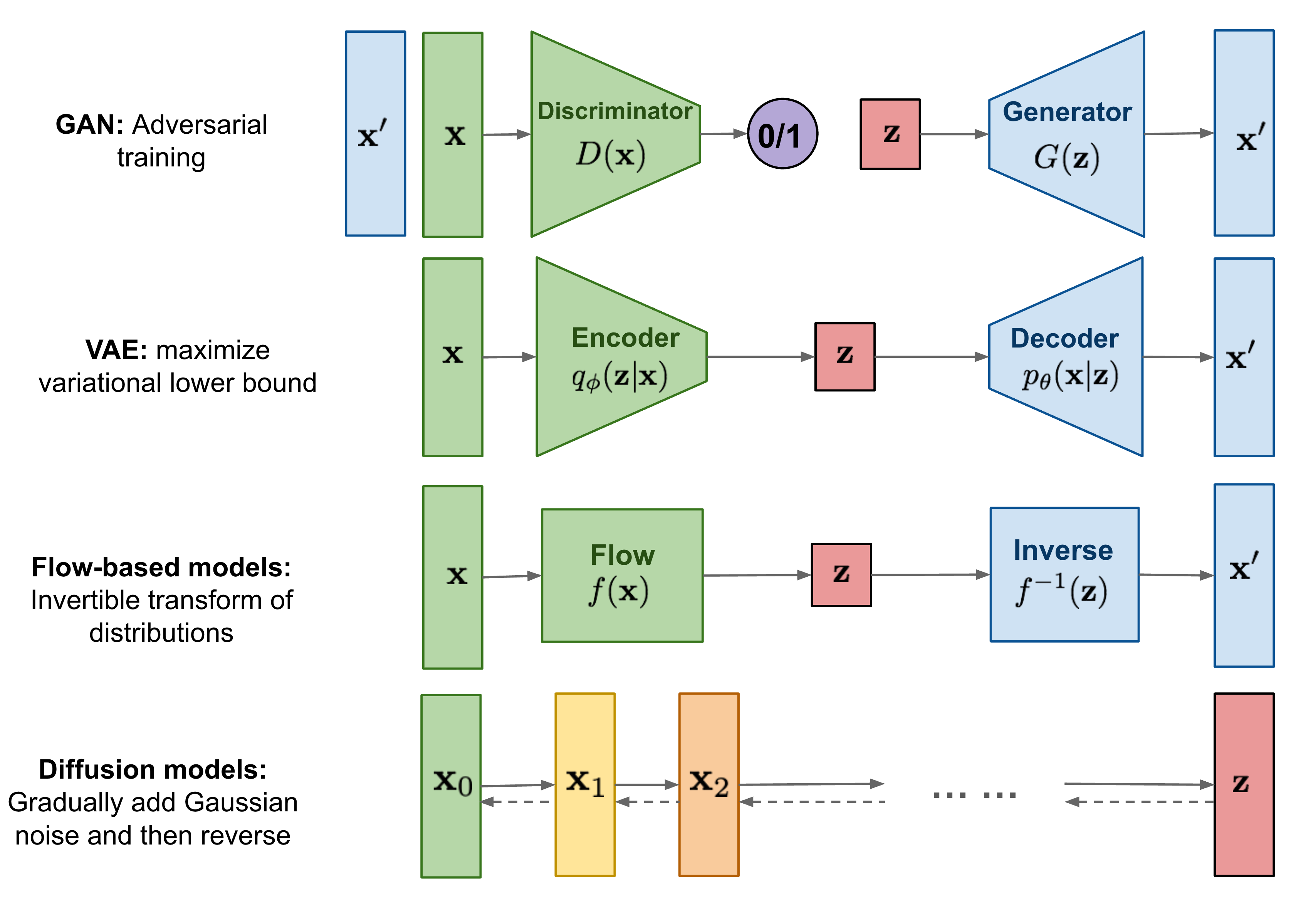
Diffusion model에 대해 다뤄보기 전, generative model의 기본적인 taxonomy와 대표 model들의 두루 살펴보자. 특히 diffusion model의 objective function을 이해하기 위해선 VAE의 수식 전개를 정확히 이해하는 것이 중요하겠다.
Generative model이란, unsupervised learning의 일종으로 input data의 distribution(underlying hidden structure)을 학습(density estimation)하여 그와 유사한 sample을 새롭게 생성하는 방식이다. 이 때, input data를 특정한 분포를 따르는 확률변수로 보는 관점이 핵심이다.
크게 1) input data의 distribution 을 explicit하게 정의하여 학습하는 explicit density와 2) generated data가 input data와 직접적으로 비슷해지도록 학습하는 implicit density로 구분되며,
특히 explicit density는 1-1) distribution 을 수식으로 정의할 수 있는(수학적으로 미분과 적분 등이 가능한 분포를 갖는) tractable density와 1-2) 분포가 intractable하여 parameter로 추정하는 approximate density로 나뉜다.
Explicit Density
Tractable Density
-
PixelRNN : Image의 좌상단 pixel부터 우하단으로 이동해가며 이전 pixel 값들을 RNN(LSTM)에 입력해 현재 pixel 값을 유추해내는 sequential generation 방식이다.
-
PixelCNN : 앞선 PixelRNN 모델의 'Pixel Recurrent Neural Networks' 논문에서 함께 소개된 모델이다. 마찬가지로 좌상단의 pixel부터 시작하나 이전의 모든 pixel 값이 아닌, convolutional layer를 활용해 filter의 context region에 포함되는 이전 pixel들로만 현재 pixel 값을 추측한다. PixelRNN보다 training 속도가 빠르지만 generation 속도는 여전히 느린 편에 속한다.
Approximate Density
-
Autoencoder : Input data에서 encoder로 low-dimensional feature(latent vector)를 추출, 이를 다시 decoder에 넣어 input data를 reconstruct하는 모델이다. 모델이 생성한 sample과 input data 간의 L2 loss를 통해 학습시키며, decoder는 encoder가 유효한 feature를 뽑아낼 수 있도록 학습시키기 위한 도구에 불과하다. 이는 supervised model의 dataset이 부족한 경우 unlabeled data로 encoder를 학습해 모델을 initialize하는데 유용히 활용된다.
-
Variational Autoencoder (VAE)
: AE는 latent space에 대한 제약을 두지 않고 단일 input을 latent space 상의 한 점으로 mapping하는 것에 비해, VAE는 하나의 distribution으로 mapping하여 latent space를 형성함으로써 overfitting 가능성을 줄인다. 기본적인 아이디어는 latent vector 를 decoder network 에 통과시켜 새로운 를 생성하는 것(generation)과, 이 때 학습이 잘 되기 위한 를 sampling하는 encoder를 학습시키는 것(conditioning)이다."A variational autoencoder can be defined as being an autoencoder whose training is regularised to avoid overfitting and ensure that the latent space has good properties that enable generative process."

를 prior에서 unconditionally sampling하면 decoder는 단순히 MSE 관점으로 비슷한 를 출력하도록 학습되어 원하는 결과가 나오지 않는다. 대표적인 예시로, MNIST dataset에 대해, 모든 pixel이 오른쪽으로 한 칸씩 이동한, 사실상 동일한 이미지의 MSE loss가 pixel 일부가 지워져 존재하지 않는 문자가 되어버린 이미지의 값보다 커지게 되는데, 에 conditioning을 하지 않는다면 그러한 image가 생성된다.
이 때 생성된 는 input data의 distribution을 따라야 하며, 이를 위해 1) input data 가 latent vector 로부터 생성되었을 확률인 likelihood 를 maximize하는 model parameter 와 2) latent variable 를 찾는 maximum likelihood estimation 문제를 해결해야 한다.
이 때, latent vector 가 normal distribution을 따른다고 가정해도 DNN의 초기 layer가 이를 latent value로 mapping하고, 그 이후의 layer가 그에 맞는 를 생성해내기에 임의의 manifold를 represent할 수 있다.
VAE 모델의 수식전개에 앞서, Bayesian statistics에서 사용되는 아래 용어를 정리할 필요가 있다.
Steps of Bayesian Inference
1. Prior distribution: 사전 지식이나 가정에 따라 모델의 파라미터나 상태에 대한 prior distribution 설정(데이터를 관찰하기 전에 알고 있는 정보).
2. Likelihood function: 모델의 파라미터나 상태가 주어진 데이터를 생성할 확률을 나타내는 likelihood function 설정.
3. Posterior distribution: Bayes' theorem을 기반으로 prior distribution과 likelihood function을 결합해 posterior distribution 계산.
4. Inference & Update: 계산된 posterior distribution을 통해 모델의 파라미터나 상태를 추정하고 업데이트.
Prior : / Evidence(marginal likelihood) :
Likelihood : / Posterior :
Input 가 evidence로 주어졌을 때, generator의 학습이 잘 이뤄질 수 있게 해주는 를 sampling해주어야 하고, 이를 수행하는 encoder network 를 parameter 에 대해 정의한다. 는 intractible한 posterior distribution 을 approximate하게 되는데, 이를 variational inference(VI)라고 칭한다.
따라서, VAE는 기본적으로 1) input data 로부터 distribution의 mean vector 와 standard deviation vector 를 출력하는 encoder network(recognition/inference network) 와, 2) 해당 값의 Gaussian distribution에서 sampling한 로부터 distribution의 평균 와 표준편차 를 출력하는 decoder network(generation network) 로 구성되는 것이다.
MLE의 대상인 는 다음과 같이 각 input data point들에 대한 likelihood의 합으로 나타낼 수 있고,
각 input data point에 대한 likelihood는 아래와 같이 정리된다.
RHS의 첫 번째 항(reconstruction error)은 decoder network로부터 sampling 가능하다. Encoder를 통해 sampling된 로부터 decoder가 생성한 의 log likelihood 값으로, encoder와 decoder의 reconstruction 성능을 나타낸다.
두 번째 항(regularization error)은 encoder network와 prior 간 KL divergence로 쉽게 계산 가능하다. 근사된 posterior 의 분포가 normal distribution과 얼마나 가까운가에 대한 척도로, VAE가 reconstruction task만 잘하게 되는 것을 방지한다.
세 번째 항의 는 intractable하나, KL divergence가 항상 0 이상의 값을 가지므로 위 log likelihood의 lower bound를 구할 수 있게 된다.
위 lower bound는 tractable하며, variational lower bound 혹은 ELBO(Evidence Lower Bound)라고 불린다. 이 lower bound를 maximize하는 parameter , 를 구하는 것이 목표이며, 이처럼 maximum likelihood 문제를 neural network로 수렴시킬 수 있는 optimization 문제로 치환한다는 것이 핵심이다.
ELBO()를 maximize하는 로 이상적인 sampling 함수를 찾고, MLE 차원에서 network parameter 를 구하는 것이다. (lower bound가 optimize될 때 likelihood도 동시에 optimize 된다.)
이를 통한 학습 방식을 요약하면, 1) input data 를 encoder network 에 통과시켜 의 분포를 출력, 2) 그로부터 를 sampling한 뒤 decoder network 에 통과시켜 의 분포를 출력, 3) 그로부터 를 sampling한 뒤 ELBO 값 계산, gradient ascent 방법으로 parameter , 값을 update하는 것이다.
하지만 decoder에 입력되는 가 randomly sampling되므로, 미분 가능하지 않아 gradient를 구할 수 없게 된다. 이를 해결하기 위해 reparameterization trick이란 기법을 사용해 backprop이 가능케 한다.
이 기법은 로 두어, 는 로 deterministic하며 외부의 random noise 가 별도로 입력되는 것처럼 하여 stochastic한 성질을 배제하는 것이다. 이를 통해 end-to-end로 미분 가능한 network를 구성할 수 있다.
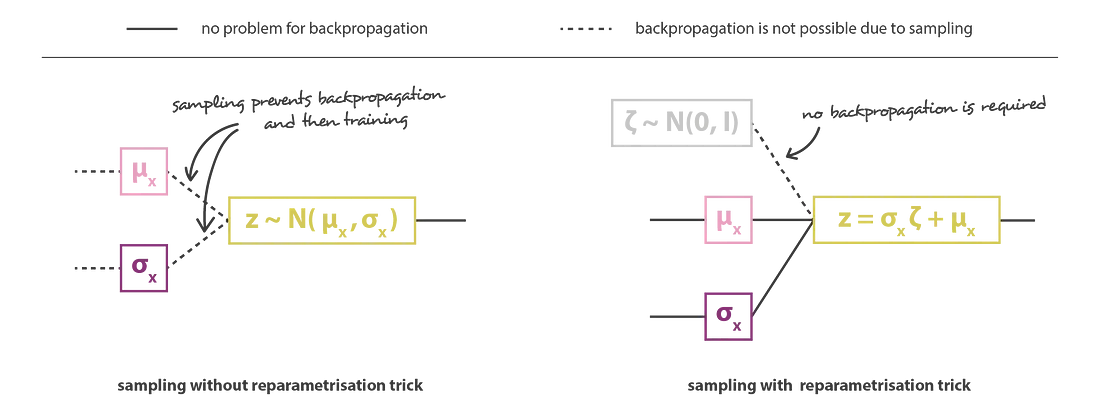
VAE에서 쓰인 Lower bounding technique의 핵심은,
1. Input data에 대한 model(decoder) parameter 의 log-likelihood 값을 maximize하는 방향으로,
2. latent variable (를 생성하는 encoder parameter )와 decoder parameter 를 update하는 것.
3. 를 직접 구하기는 어려우니, 이를 tractable term들로 치환하는 lower bounding technique를 사용하여 해결하는데,
4. Decoder network의 gradient가 encoder network까지 전달되게 하기 위해 random variable 의 stochastic feature를 random noise 로 reparametrize하여 학습!

Implicit Density
: Tractable density를 정의하지 않고 직접적인 data generation만 가능하게 되더라도 복잡한 data에 대해서는 더 효율적일 수 있다.
-
GAN
: Adversarial(적대적) 관계의 두 network를 game theory를 기반으로 동시에 학습시키는 방식이다.Random variable 로부터 fake image를 생성하는 generator network 는 discriminator network가 자신의 출력물을 real image라고 판단하도록, 즉 값이 1에 가까워지도록 학습시킨다.
반면, discriminator network 는 real image와 fake image를 정확히 구분할 수 있도록, 즉 값이 1에, 값이 0에 가까워지도록 학습시킨다.
이를 수식으로 나타내면 아래와 같다.
따라서 Discriminator에 대해선 gradient ascent, generator에 대해선 gradient descent를 교차하여 반복 수행한다.
다만, 초기 단계에서 함수의 기울기 값이 작아 학습속도가 느리므로 아래와 같이 generator에 대한 loss function을 따로 정의하여 gradient ascent 수행한다.
위와 같이, diffusion model을 살펴보기에 앞서 여러 고전적인 generative model에 대해 살펴보았다. 다음 글에서는 본격적으로 diffusion model의 개념에 대해 살펴보도록 하겠다.
References
