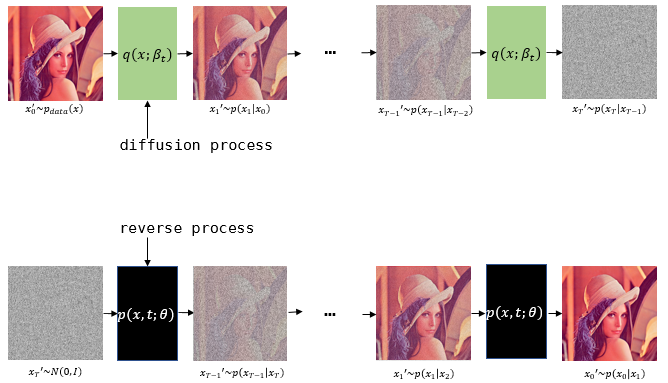
Stable diffusion이 나오기 전, diffusion model의 근간을 이룬 논문들을 소개하며 기본적인 개념을 다뤄보도록 한다.
1. 'Deep Unsupervised Learning using Nonequilibrium Thermodynamics' (Sohl-Dickstein et al., ICML 2015)
: Diffusion probabilistic process를 비지도학습을 위한 방법론으로 처음 활용한 논문으로, Flexibility와 tractability를 동시에 만족하는 생성 모델을 제안하였다.
1. Introduction
-
Input으로부터 단번에 latent vector를 얻어내는 것이 아닌, small perturbation(Markov diffusion kernel)을 여러 번 적용하여 tractable하게 만드는 방식이다.
-
어떠한 target distribution도 diffusion process로 capture 가능하다.
-
"We restrict the forward (inference) process to a simple functional form, in such a way that the reverse (generative) process will have the same functional form."
2. Algorithm
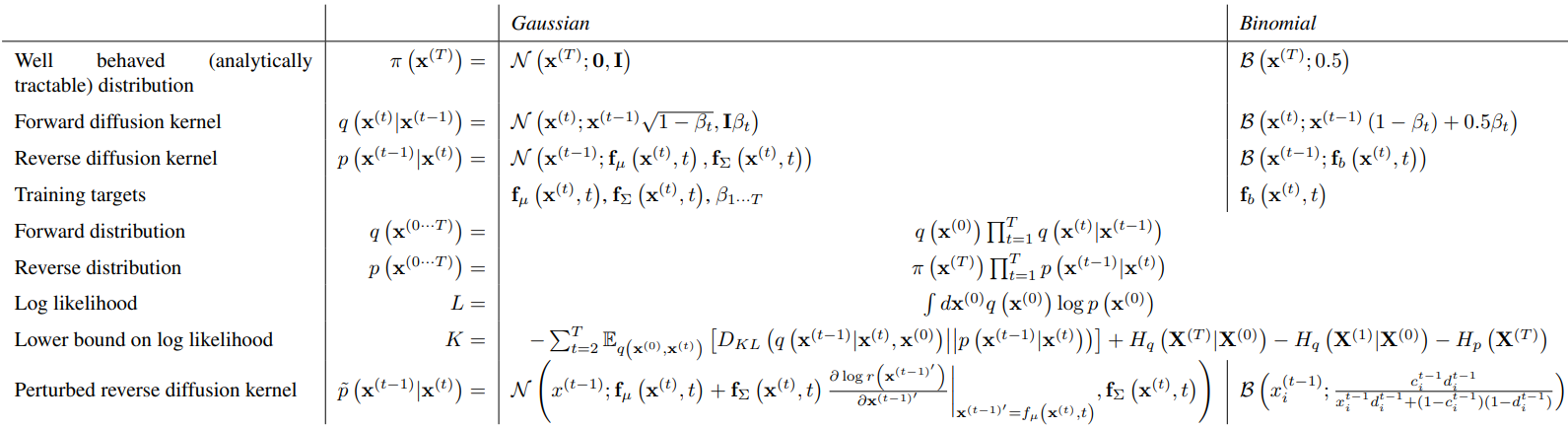
- Forward(inference) diffusion process : Repeated application of a Markov diffusion kernel with diffusion rate, .
Gaussian diffusion into a Gaussian distribution with identity-covariance, or binomial diffusion into an independent binomial distribution(bit flip)
-
Reverse generative distribution : Forward process의 reverse trajectory로, kernel의 repeated application.
가 작은 값의 Gaussian(binomial) distribution을 갖는다면 는 와 identical functional form을 가진다(Tragectory가 길수록 의 값은 작아짐). 즉, 도 Gaussian(binomial)로 설정 가능하다. -
Training: Model log likelihood 를 maximize하도록 학습한다. Lower bound strategy()를 사용한다.
,
Forward diffusion에서의 diffusion rate 와, reverse diffusion에서 각각 mean과 covariance를 출력하는 함수 와 가 를 maximize하도록 학습!
-
Denoising이나 inpainting을 위해선 모델 분포 에 bounded positive function 를 곱해야 하는데( ), 두 분포를 곱하는 것은 costly & difficult하다. 하지만 diffusion model에서는 각 step에서의 small perturbation으로 간주하여 단순화가 가능하다. 본 논문에서는 이를 time-step에 따라 constant하게 두었다.
2. 'Denoising Diffusion Probabilistic Models' (Ho et al., NeurIPS 2020)
: a.k.a. DDPM. 기존 diffusion model의 loss term과 parameter estimation 과정을 더 학습이 잘 되는 방향으로 발전시켰다.
1. Introduction
- 본 논문은 diffusion model이 high quality sample을 생성하는 capability를 보여주었다는 것에 의의를 둔다.
- 특정 parameterization of diffusion models가 denoising score matching과 동일하다는 것을 보였다.
2. Background
: 역시나 true data distribution 를 학습하는 것이 목표이다.
-
Forward(diffusion) process : Posterior
*Variance 값을 1로 유지 + 임의의 timestep 에 대한 sampling 가능
: , , -
Reverse process : Joint distribution
-
Variational lower bound on negative log likelihood
(regularization term) (denoising process term) (reconstruction term)
*는 intractable하나 는 tractable!
3. Diffusion models and denoising autoencoders
-
Forward process : Diffusion rate 를 고정시켜 parameter의 학습이 이뤄지지 않는다.
-
Reverse process :
-
(regularization term) : Forward process 와 를 각각 untrained parameter를 가지는 정규분포로 가정했기 때문에 term으로는 학습이 진행되지 않는다.
(Fixed noise scheduling으로도 충분히 많은 diffusion kernel을 통해 'isotropic Gaussian' latent space를 획득할 수 있어 regularization이 불필요하다.) -
(denoising process term) : 1) 와 를 구성하는 2) , 3) 를 구해야 한다.
-
,
where ,
and (reparameterization) -
: Untrained time dependent constants
위 식을 항에 대입하면, 가 forward process posterior mean인 를 predict할 때 최소의 loss 값을 가지며, 해당 값에 의 reparameterization 식을 대입하면 로 표현된다. 즉, 는 학습 과정에서 sampling되어 주어지므로, 가 의 함수로 나타내어지는 값을 predict해야 한다.
이 때, 로부터 값을 approximate하는 를 정의하여 식을 아래와 같은 denoising matching의 관점으로 새롭게 정의하면,
이며, 이를 다시 항에 대입하면, 아래와 같은 loss term이 만들어진다.
-
-
(reconstruction term)
위 loss term을 통해 충분히 학습 가능하며 무시할 경우 sample quality가 좋아지는 것으로 알려져 있다.
-

-
Data scaling, reverse process decoder, and
- {0,1, ..., 255}의 픽셀 값을 [-1, 1]의 범위로 scale하였다.
-
Simplified training objective
에 dependent한 상수 값을 생략하여 L2 loss와 같은 형태의 objective function을 구하였다. 이는 작은 의 loss term에 대해 down-weight하는 효과를 가진다.
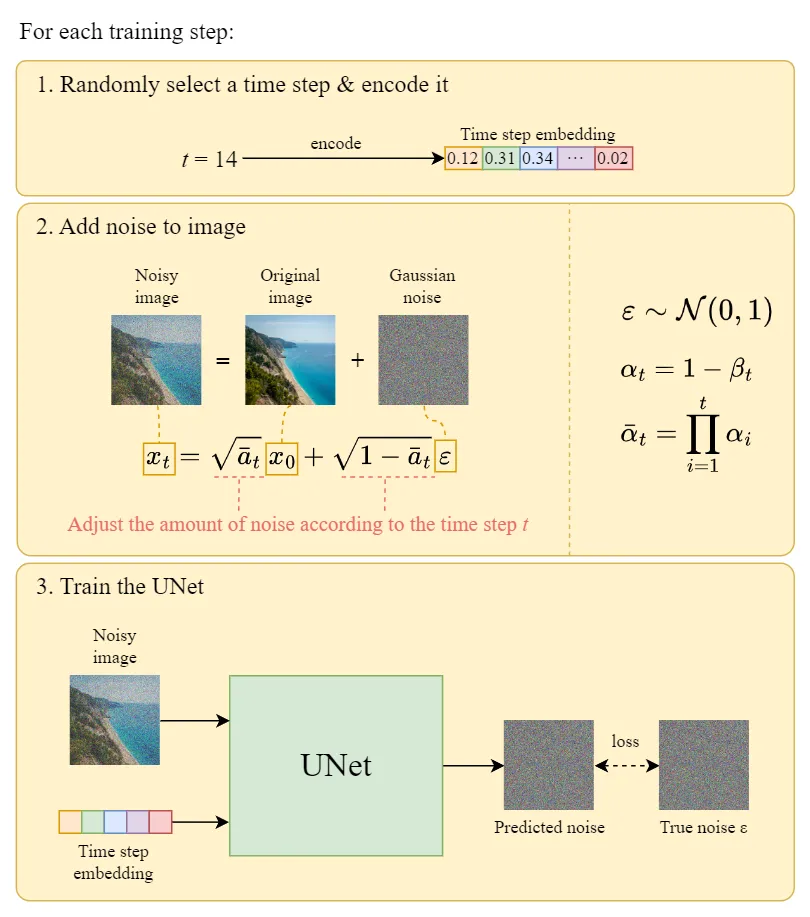
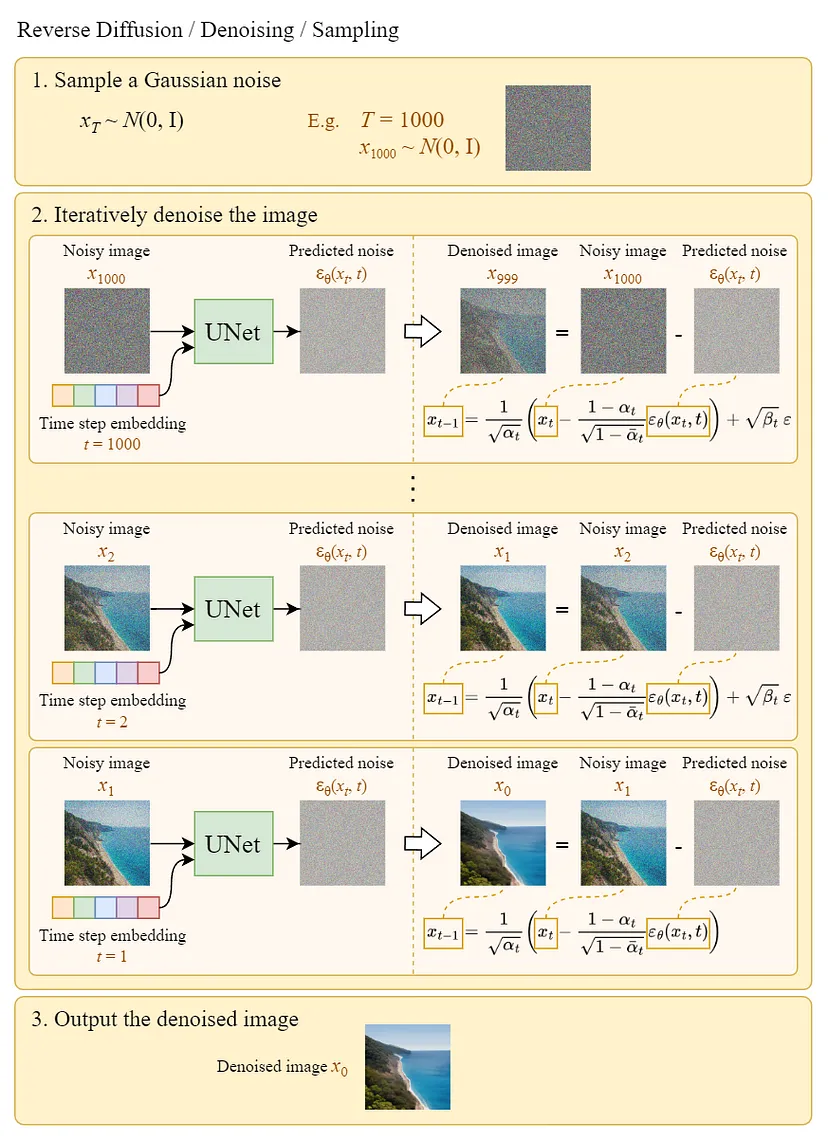
4. Experiments
- T=1000, linearly increasing constant : to
- U-Net backbone with group normalization
- Simplified objective가 training에서의 codelength는 안좋게 나왔지만 최고의 sample quality를 보여준다. 또한 에 대한 prediction이 해당 objective에 더 적합했다고 한다.
3. 'Denoising Diffusion Implicit Models' (Song et al., ICLR 2021)
-
a.k.a. DDIM. 기존의 DDPM을 non-Markovian diffusion process에 대해 일반화한 모델이다.
-
로 process를 재정의하며, 의 Gaussian noise 를 0으로 두면 deterministic generative process가 가능해진다. 즉, 임의의 noise에 대한 image가 유일하게 결정된다.
-
DDPM보다 더 적은 sampling step으로 fast sampling이 가능하며, 요샌 DDPM으로 학습시킨 모델을 DDIM의 generation 방식으로 sampling하는 것이 일반적이다.
4. 'Score-based Generative Modeling with Differential Equations' (Song et al., ICLR 2021)
-
별개의 방향으로 연구된 'score-based method'가 'diffusion model'과 동일함을 밝힌 논문이다.
-
Taylor expansion을 통해 에 대한 sampling 관계식을 아래와 같이 표현 가능하다.
-
위 관계식을 stochastic differential equation(SDE)의 형태로 나타내면, 아래와 같다.
-
위 식의 RHS은 앞선 drift term(pulls towards mode) 와 diffusion term(injects noise) 로 구분 가능하다.
-
핵심은 score function 를 optimize 하는 것이며, 이는 intractible하므로 을 학습하도록 수정하였다.
에 대한 reparameterization으로 수식을 정리하면 기존 DDPM의 loss term과 동일해진다.
위와 같이, diffusion model을 처음으로 제시한 논문과 해당 모델의 실용성을 발전시킨 DDPM, DDIM 논문을 통해 diffusion model의 기초 내용을 다뤄보았다. 다음 글에선 stable diffusion 모델을 다뤄보기 전 마지막으로 conditioning algorithm에 해당하는 attention과 classifier-free conditioning에 대해 살펴보도록 하겠다.
References
['Deep Unsupervised Learning using Nonequilibrium Thermodynamics']
- 김지훈 님의 논문리뷰
- 아이공의 AI 공부 도전기 :: 논문 Summary
- Diffusion model 설명(Diffusion model이란, Diffusion model 증명)
- Diffusion Model 입문하기
[DDPM]
