[paper-review] Robots That Ask For Help: Uncertainty Alignment for Large Language Model Planners
LLM
목록 보기
11/11
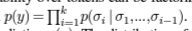
Uncertainty에 대한 접근 방식 제안
1. 개요
- Uncertainty
- 정확하게 모델링, 계산하는 것은 오랫동안 해오던 과제
→ 이를 '언어'로 해결해보고자 한다
→ LLM을 사용하면 다양한 장점이 있지만 '환각'에 대한 문제가 있다
→ 심지어 현실에서는 사람들의 말에 '모호함'도 많아서 이해를 잘 못할 수 있다
- 정확하게 모델링, 계산하는 것은 오랫동안 해오던 과제
- 방향성
- task 성공을 위해 충분한 도움을 요청해야 한다
- 로봇은 Uncertainty를 줄여서 도움의 양을 최소화해야 한다
- KNOWNO
- Uncertainty 측정, 언제 알고 모르는지를 파악하여 도움을 요청하는 프레임워크
- 사람의 도움을 최소화하면서 통계적 보장을 제공하기 위해 Conformal Prediction(CP)을 기반
2. 방법
-
Contribution
- 언어 명령 → LLM을 활용하여 실행 가능한 작업들을 생성 → CP를 활용하여 하위 집합을 선택
- 사용자가 지정한 레벨 1-를 사용하면 로봇 1-%의 시나리오에서 작업을 올바르게 수행한다고 판단하면 도움 요청
- 평가는 현실, 시뮬레이션 둘 다 진행했고 실험에서 10~24% 도움 요청이 최소화된 것을 확인
-
Language-based planners
-
각 단계 y는 가변 길이 시퀀스(,,...,)로 구성 또는 인터프리터에 의해 실행되는 로봇 코드
-
LLM은 토큰에 대한 결합 확률이 다음 토큰 예측의 조건부 확률의 곱으로 인수분해될 수 있는 각 단계 y를 예측
-
다음 단계의 를 특정하는 것에 관심을 둔다
→ p의 분포는 k에 매우 민감 → 의 계획 단계가 자연어로 표현되면 다소 약한 점수로 사용된다
-
-
Planning as multiple-choice Q&A
- 길이 편향 해결 트릭
- 다음 단계에서 할 몇 가지 절차를 만든다
- 선택 작업은 객관식 Q&A (MCQA)
→ 가능성 없는 절차는 삭제하여 다음 단계 예측 선택 사항을 줄인다
이런 확률은 임계값, 앙상블 방법과 같은 다양한 Uncertainty 정량화에 사용할 수 있다
- 길이 편향 해결 트릭
-
Robots that ask for help
- 환경 e → POMDP로 공식화 가능
- Multiple-choice generation
계획 라벨 집합
① 각 단계에 관찰된 정보 ② user interaction ③ 가능한 다른 시나리오 몇 가지
①~③ 포함된 텍스트 prompting에 의해 생성
- Prediction set generation
가 주어지면 예측 에서 LLM의 신뢰도 를 사용하여 하위 집합 를 선택하기 위해 CP를 사용한다
- Human Help
만약 예측 세트가 하나가 아니라면, 로봇은 사람으로부터 도움을 받아야 한다
- Low-level control
모듈 는 를 로 변경한다
- 환경 e → POMDP로 공식화 가능
-
Goal : Uncertainty Alignment
- Uncertainty를 최소한의 도움으로 해결하는 것이 목표
- D를 고려하여 공식화
- 로봇 policy가 ~ 절차에서 확률로 성공
- 그 policy는 ~ 전반적으로 를 최소화
3. 실험
- 사람이 충실히 도와준다는 가정
- 누적 임계값을 기반으로 하지만 서로 다른 종류의 점수 기준 (Simple Set, Ensemble Set)
- 누적 임계값 대신 CP를 사용해서 통계적 보장이 가능
- 두 개의 prompt baseline (Prompt Set, Binary)
- Prompt Set : LLM이 예측 셋 직접 출력
- Binary : LLM이 Uncertainty에 대한 이진 표시 직접 출력하도록 유도
1.Simulation : Tabletop Rearrangement
- 3가지 유형의 Uncertainty 설정
① Attribute ② Numeric ③ Spatial
→ 목표 작업 성공률을 달성하는지 조사 (실패 수준 )
→ KNOWNO는 CP 덕분에 전반적으로 최소 편차 달성 - ↓하면 성공률↑, 사람 도움↑ 필요
- Ensemble Set이 성능은 좋지만 컴퓨팅 비용이 비싸다
2. Hardware : Multi-Step Tabletop Rearrangement
- error level : 로 설정
simple set은 - KNOWNO는 사람의 도움 비율을 줄여나갔다
- 양손 조작 실험 결과도 있다
3. Hardware : Mobile Manipulator in a kitchen
- KNOWNO랑 Simple Set 비교 ( 다르게 해서)
→ KNOWNO 좋음 - 두 가지 LLM을 이용하여 진행
PaLM-2L, GPT-3.5 둘 다 결과에 영향이 조금 있다, 그래도 KNOWNO는 성공률 면에서 강건
4. 결론
- Related Works
- MCQA를 기반으로 하지만 자연어 생성에도 적용가능
- CP를 자연어 생성에 최초 적용
→ 로봇의 행동이 미래 입력 분포에 영향을 미치는 설정에서 시퀀스 수준 보정으로 전체에 대한 정확성 보장 - 로봇이 필요할 때 질의응답으로 도움 요청
- 결론
- Conformal Prediction이 제일 핵심
- 한계는 LLM planner가 제안한 절차가 성공적으로 실행 가능하다고 가정
- 또 로봇이 인간의 도움이 필요하면 충실하게 도움을 제공해야 한다
