이번엔 팀원들과 함께 대용량 트래픽 관리 프로젝트를 진행해보기로 하였다.
137,000 여 건의 데이터가 저장되어있는 csv 파일로부터 값을 받아와 DB에 업로드하고, 필터 기능과 Pageable 기반으로 값을 불러오는 작업을 해볼 예정이다.
대상이 되는 자료는 서울시 인터넷 쇼핑몰 현황 ( https://data.seoul.go.kr/dataList/OA-2256/S/1/datasetView.do ) 으로, 초기엔 csv 로 데이터를 불러와보고 이후엔 OpenAPI 를 통해 값을 불러오는 것도 도전해볼 예정이다.
개발 내용을 정리해보자면 다음과 같다.
필수 구현
- Intellij Ultimate 활용하여 csv 파일로 Database 테이블 생성하기
- 업체 리스트 조회 중 필터 기능
- '전체평가' 필터 조회 : 0~3 점으로 저장되는 필드. 입력한 점수에 해당하는 업체만 조회
- '업소상태' 필터 조회 : 업소 상태 중 1개를 선택하여 해당 업체만 조회
- '모니터링날짜'의 내림차순으로 정렬하여 출력
- index 생성하여 작업 속도 줄이기
선택 구현
- Pageable 기반 업체 리스트 조회
- '전체평가' 필터와 '업소상태' 필터를 동시 적용하여 결과물 조회
- csv 를 database 에 입력하는 API 생성
- 서버 내 특정 위치의 csv 파일을 1개 행씩 읽어 Database 에 차례로 Insert
심화 구현
- QueryDsl 을 사용하여 커서 기반 페이지네이션 적용
- OpenAPI 를 통해 database 에 Insert
- 100개 단위로 읽어 Insert 하기
ERD 는 다음과 같이 구성하였다.
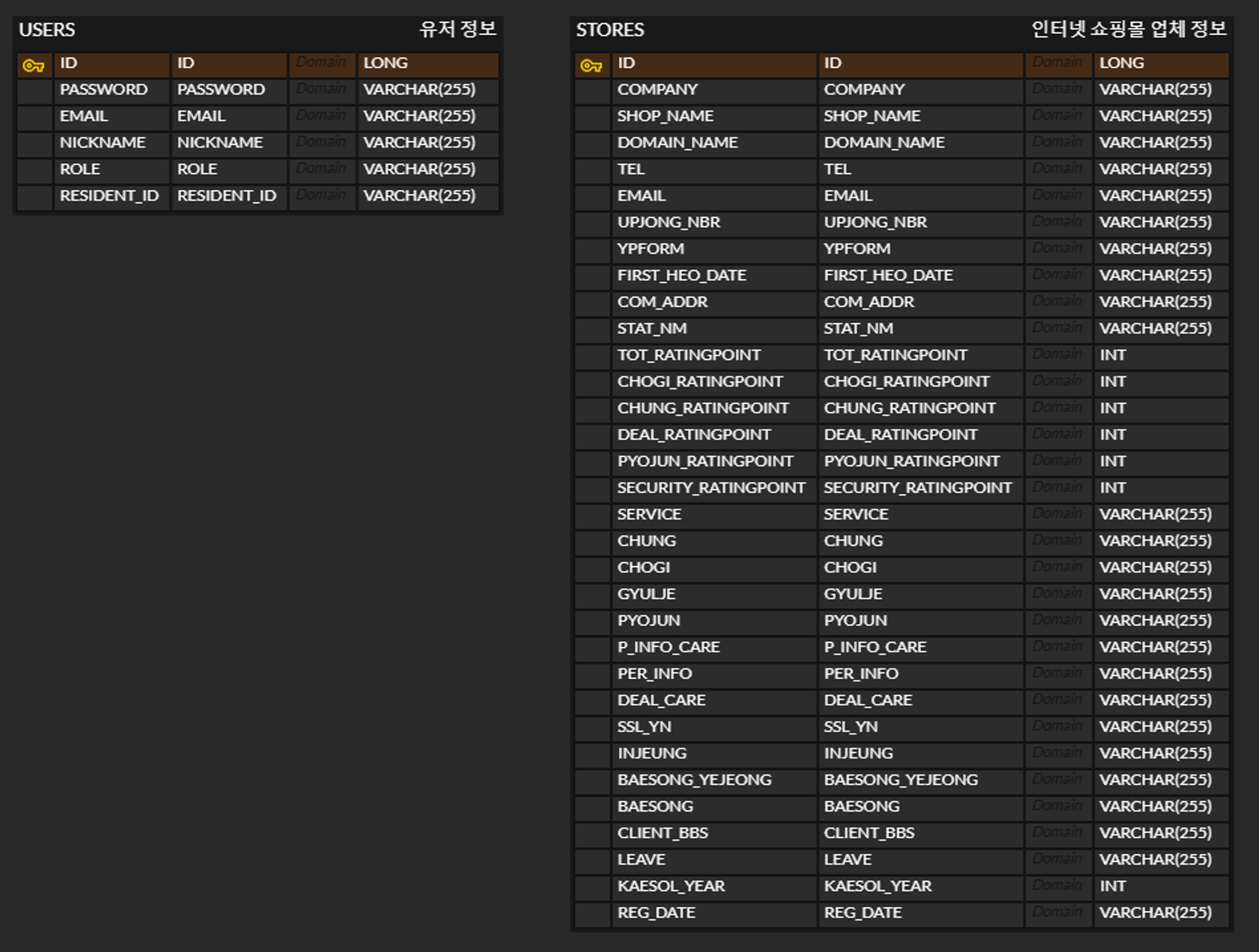
주어진 데이터에 필드가 굉장히 많고, nullable 한 필드도 많아 파악에 애를 먹었다.
사용자가 결과물을 조회할 땐 Projection 을 통해 간단한 내용만 조회할 수 있도록 하는 기능도 추가하려 한다.
주요 API 명세는 다음과 같다.

같은 결과라도 상세조회 / 단순조회로 구분하여 Projection 을 이용하기로 하였다.
지난번 공부했던 QueryDSL 의 기능들을 활용해보는 프로젝트이기에 내용을 제대로 숙지하고 있는지, 구조를 잘 구성할 수 있는지 확인해볼 수 있는 기회가 될 것 같다.
그리고 대용량의 데이터를 어떻게 처리해야 하는지 여러 방법으로 구현해보며 각 구조를 연구해보는 시간을 가지려 한다.
여기에 추가로 @cacheable 어노테이션으로 조회결과를 캐싱하는 내용도 도전해볼 수 있으면 좋겠다.

Not Yet