Oversampling
1. Resampling
- 다수 vs 소수 데이터 셋의 비교에서 소수 데이터를 단순히 복제하여 그 수를 늘린 뒤에 분류경계선을 형성하는 방법
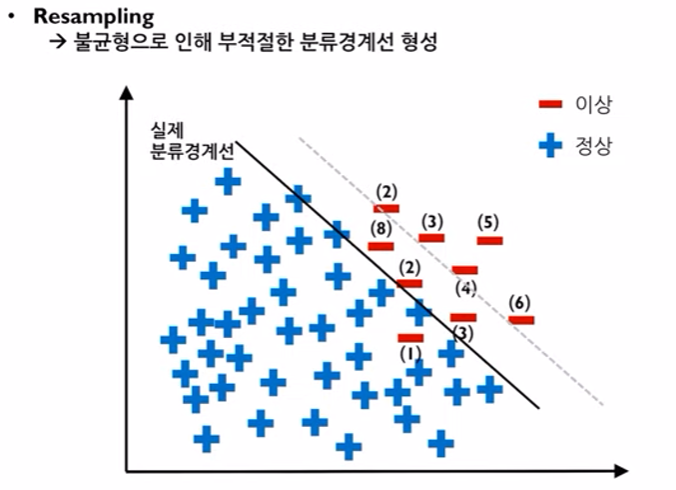
- (2), (3)의 숫자는 이 숫자만큼 해당 데이터를 복제했다는 의미
- 기존에 회색점선으로 형성 되었던 분류경계선이 데이터 복제 후에 경계선이 좀 더 이상적인 형태로 형성되는 것을 볼 수 있다.
단점
- 너무 소수데이터셋에 초점을 맞추다보니 overfitting이 발생할 수 있다.
2. SMOTE(synthetic minority oversampling technique)
- 소수 데이터들 간의 거리를 비교하여 중간중간에 새로운 소수데이터를 형성하는 방식
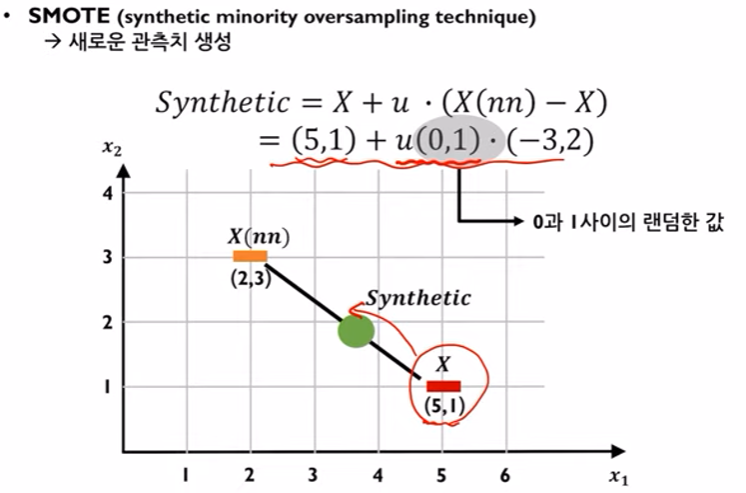
- 위와 같은 계산식을 이용하여 모든 소수데이터들 사이사이에 중간데이터를 형성한다.
- 결과적으로 아래와 같이 소수데이터가 증폭된 형태를 보이게 된다.
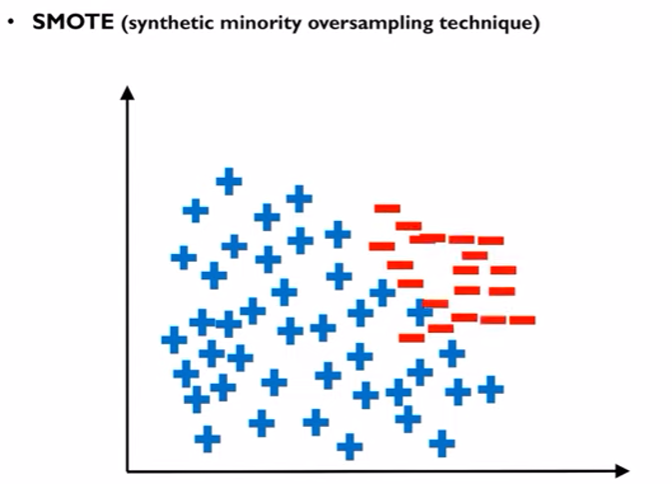
- 이 때 중간값을 형성하기 위한 두개의 소수데이터는 랜덤으로 선택되도록 하며 따라서 KNN 방식을 사용하되 K 값을 1이 아닌 값으로 설정해야 한다. K 값이 1인 경우 계속 같은 데이터가 선택되기 때문에 새롭게 형성되는 데이터들이 같은위치에 뭉쳐서 나타나게 되는 문제가 생긴다.
Bordline-SMOTE
소수와 다수 데이터가 적절히 섞인 borderline을 찾는다
K = 5 라고 가정 할 때,
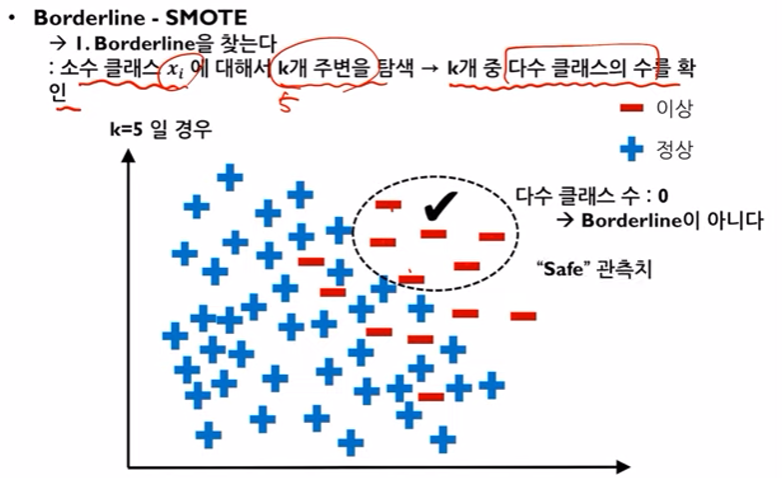
1) "Safe"관측치
- 소수데이터를 기준으로 주변의 5개의 데이터를 확인한 결과, 이렇게 소수데이터만 존재하는 것은 Borderline이 아니다.
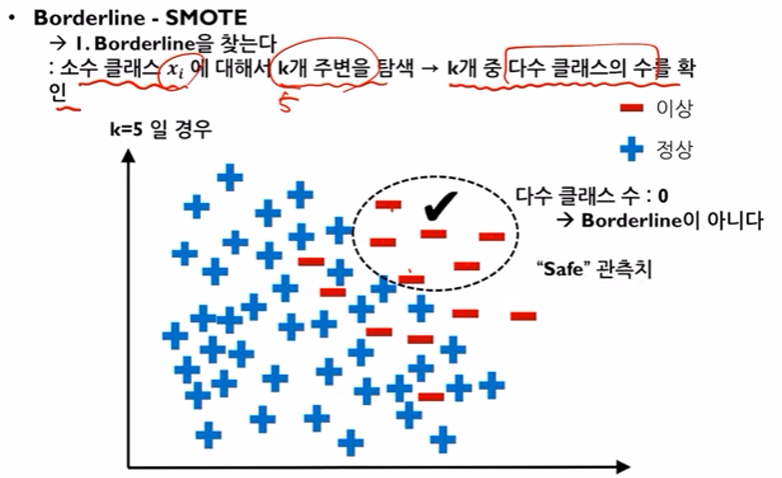
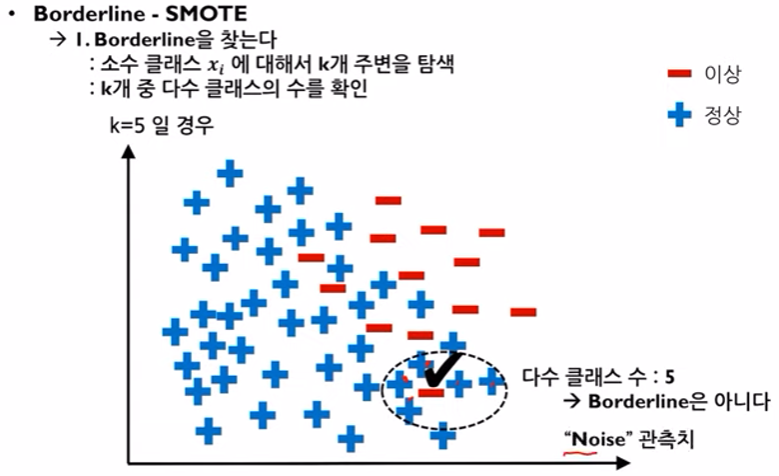
2) "Danger" 관측치 - 다수와 소수가 섞인 이와같은 형태를 Borderline이라고 한다.
3) "Noise" 관측치 - 다수 클래스만 존재하는경우 이 또한 Borderline이 아니다.
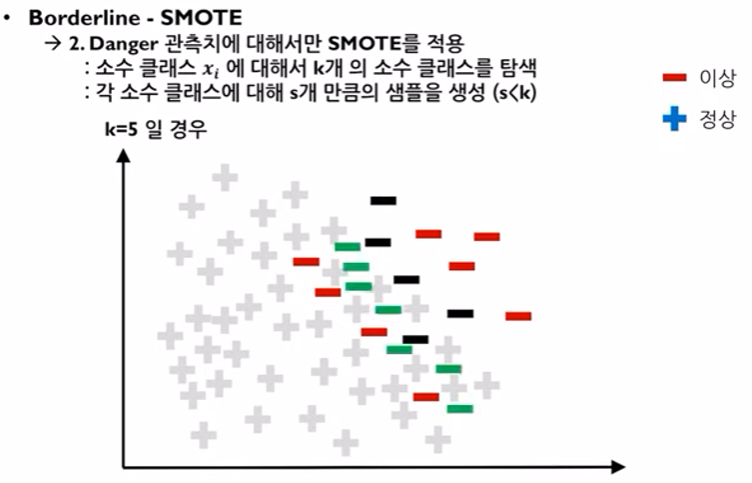
- 이렇게 선정된 "Danger"관측치(그림상의 검정색 데이터)에 대해서 SMOTE 방식을 적용하여 새로운 소수 데이터셋(녹색)을 만든다.
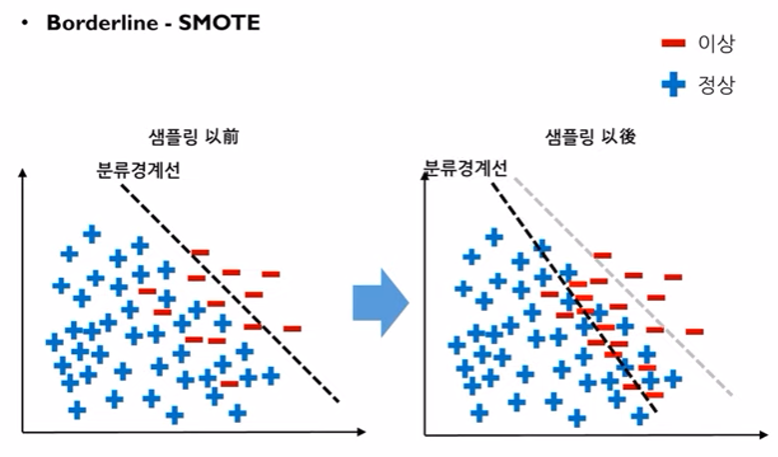
- 결과적으로 이와 같은 형태로 분류경계선이 재 형성 된다.

초심자