Imbalanced data
- 비교하는 두 data의 범위의 차이가 심한 형태의 dataset
ex) 98% 정상 vs 2% 비정상 데이터
Undersampling
-
Undersampling은 다수 vs 소수 의 데이터 구성에서 여러 방식을 통해 다수쪽의 데이터를 지워나가며 좀 더 명확한 구분을 가능하게 하는 방식이다.
-
Random undersampling
- 말그대로 랜덤하게 sample의 범위를 나눔
- 의외로 잘 작동하지만 여전히 오분류의 문제가 많음
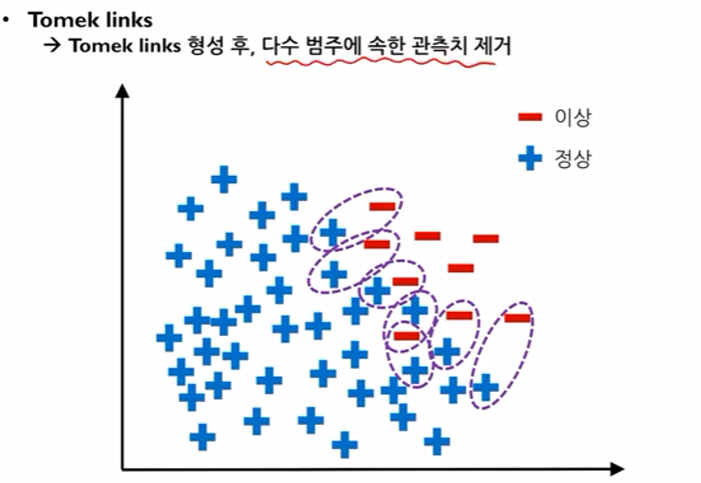
- Tomek links
-
두 데이터 사이에 아무런 데이터가 없는 link를 만든뒤에 링크에 해당하는 sample을 제거한다.
-
이 예제의 경우 정상(+) 데이터가 major(다수) 데이터 이므로 tomek link 형성 후 (+)데이터를 삭제한다.
-
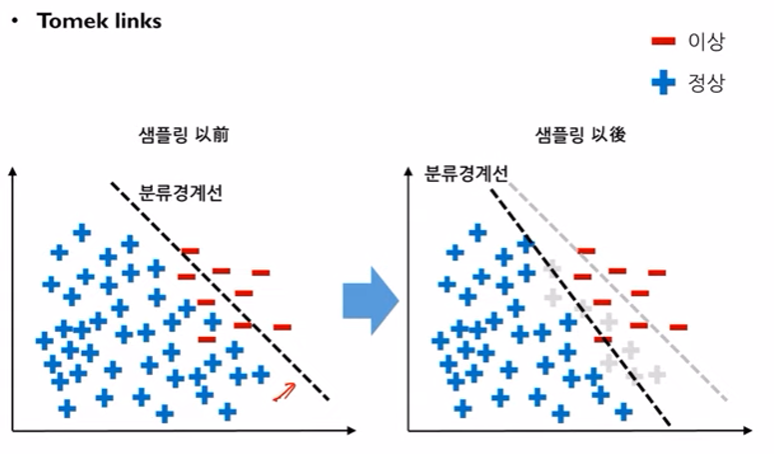
제거 전 vs 후 비교
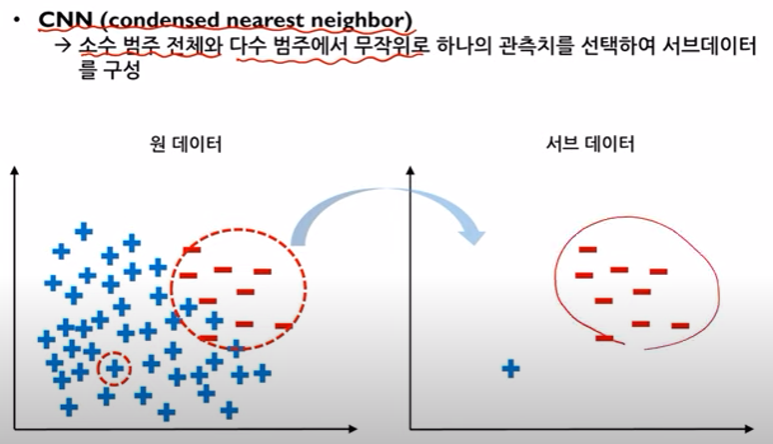
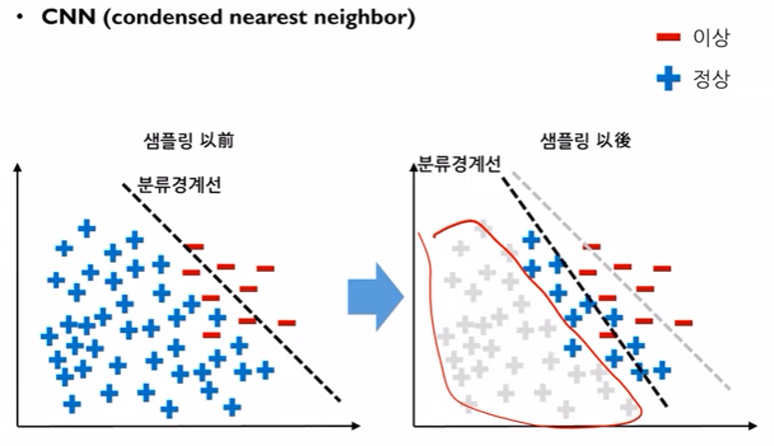
- CNN (condensed nearest neighbor)
-
소수 데이터 전체와 다수데이터 하나로 구성된 서브 데이터 셋을 형성
-
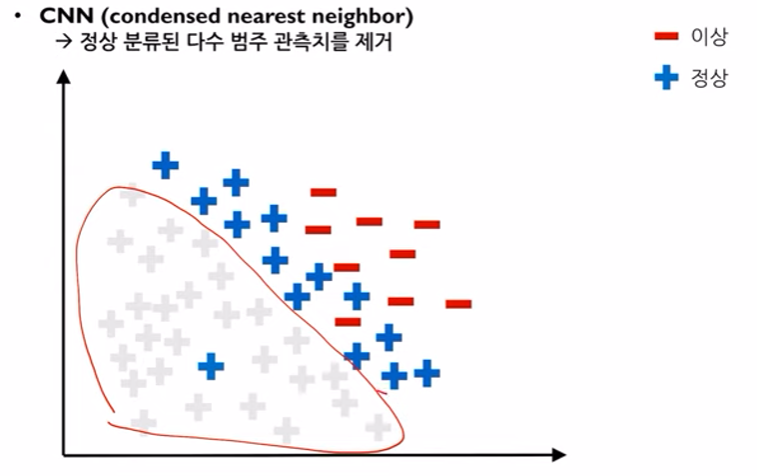
1-NN(KNN과 동일한 방식) 으로 소수데이터에 가까운 다수 데이터를 선별하고 나머지는 모두 제거함으로써 분류 경계선을 재설정한다.
-
KNN과 같은 방식이지만 K값을 1외의 값으로 사용할 경우 모든 데이터가 지워지는 문제가 발생하기 때문에 K값은 무조건 1로 설정하고 사용해야 한다.
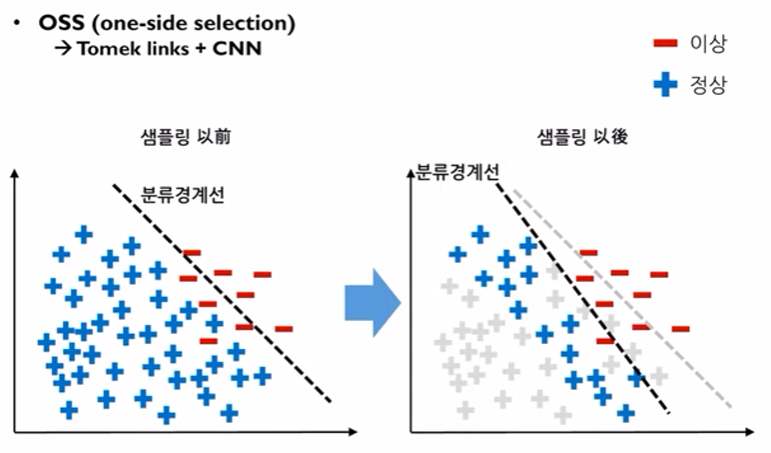
- OSS (one-side selection)
- Tomek links + CNN 의 혼합 방식
- Tomek links 에 해당하는 다수데이터와 CNN에 해당하는 다수데이터를 모두 제거한다.
장점
- 다수 데이터의 제거로 계산 시간 감소
- 데이터 클랜징으로 클래스 오버랩 감소
단점
- 데이터 제거로 인한 정보손실 발생

초심자