주제 : Data Manipulation
1. 학습 목표
- pandas를 통해 데이터를
concat/merge할 수 있다. - tidy 데이터 에 대한 개념을 이해한다
melt와pivot/pivot_table함수를 사용하여 wide와 tidy 형태의 데이터를 서로 변환 할 수 있다.
2. 과제 질문
- 여러개의 엑셀 데이터 한번에 불러와서 합치기 - Concat
- 데이터 합치기 - merge()
- 한글 폰트 깨짐 현상 해결하기 - 폰트설정, 마이너스 폰트 설정, 글씨 선명도
- 특정 열에 속한 문자 지우기 - lambda 이용
- 인덱스 설정하기 - set_index()
- tidy 형태 만들기 - melt()
- column 명칭 변경하기 - rename()
- 인덱스 숨기기 - style.hide_index()
- 구글 코랩에서 드라이브에 있는 파일 경로 보기
- 특정 column별로 평균내기 - groupby()
3. 과제 명령어 모음
(1) 여러개의 엑셀 데이터 한번에 불러와서 합치기 - Concat
def mydf(myurl):
df = pd.read_csv(urlhead + myurl).transpose()
new_header = df.iloc[0]
df=df[1:] #df 1행부터 재설정
df.columns = new_header
return df[-1 :] # 제일 최근 분기의 데이터를 뽑아 오기 위한 과정🌟 csv파일을 불러옴과 동시에 transpose() 수행
🌟 header를 설정하는 방법 2 (1은 앞에서 정리함)
df = pd.concat([mydf('000080.csv'),mydf('000890.csv'), mydf('005300.csv'), mydf('027740.csv'), mydf('035810.csv'), mydf('136480.csv')])
df = df.reset_index()
df = df.drop(df.columns[0], axis=1)🌟 함수와 Concat을 이용해서 한번에 데이터 합치기
🌟 인덱스 초기화 하기
🌟 컬럼이 0인 부분의 열 제거하기
(2) 데이터 합치기 - merge()
df2= left.merge(right, how='left')🌟 pandas merge option
left
왼쪽 테이블은 그대로, 합쳐지는 테이블은 공통부분은 옮겨지고 공통되지 않은 것은 null값 부여.right
오른쪽 테이블은 그대로, 합쳐지는 테이블은 공통부분은 옮겨지고 공통되지 않은 것은 null값 부여.outer
좌, 우측 테이블의 모든 데이터를 읽어온다. 이때, 중복된 데이터는 삭제한다inner
교집합cross:
creates the cartesian product from both frames, preserves the order of the left keys. 두개의 테이블의 행 * 행 만큼의 행으로 이루어진 테이블이 만들어진다
(3) 한글 폰트 깨짐 현상 해결하기 - 폰트설정, 마이너스 폰트 설정, 글씨 선명도
import matplotlib as plt
plt.rc('font', family= 'NanumGothic') ## 나눔고딕 폰트로 설정
plt.rc('axes', unicode_minus=False) ## 마이너스 폰트 설정
%config InlineBackend.figure_format = 'retina' # 글씨 선명하게 출력하는 설정🌟 설정했음에도 폰트가 깨진다면??
(4) 특정 열에 속한 문자 지우기 - lambda 이용
df['매출액']=df['매출액'].apply(lambda x : x.replace(',',''))🌟 lambda 함수는 일시적으로만 썼다가 지워지는 함수.
(5) 인덱스 설정하기 - set_index()
df.set_index('종목명', inplace=True)🌟 특정 열로 인덱스를 설정할 수 있다
(6) tidy 형태 만들기 - melt()
df_tidy = df.melt(id_vars=['종목명'], value_vars=['매출액','자산총계','EPS(원)'])🌟 종목명에 따른 value_vars의 Observation값 구함.
🌟 tidy 형태는 Seaborn과 같은 시각화 라이브러리에서 유용하게 쓰인다.
🔥 참고 pivot_table: Tidy -> Wide
# 파라미터에 대한 설명
# index: unique identifier
# columns: "wide" 데이터에서 column별로 다르게 하고자 하는 값.
# values: 결과값이 들어가는 곳 (wide 데이터프레임의 내용에 들어갈 값)
wide = tidy1.pivot_table(index = 'row', columns = 'column', values = 'value')
wide🌟 pivot_table을 통해 wide 구조로 바꿀 수도 있다
(7) column 명칭 변경하기 - rename()
df_tidy = df_tidy.rename(
columns = {
'variable':'Feature',
}
)🌟 이름 바꾸는 방법 헷갈리네..??
🌟 df.columns([' ~~']) 도 있었던 것 같은데?
(8) 인덱스 숨기기 - style.hide_index()
df2.style.hide_index()🌟 colab에서는 안 됐었는데..?
(9) 구글 코랩에서 드라이브에 있는 파일 경로 보기
🌟 왼쪽에서 아이콘 클릭으로 마운트를 먼저 해주자!
🌟 content -> drive -> mydrive에서 원하는 파일 찾기
🌟 파일 우클릭 후 경로 복사
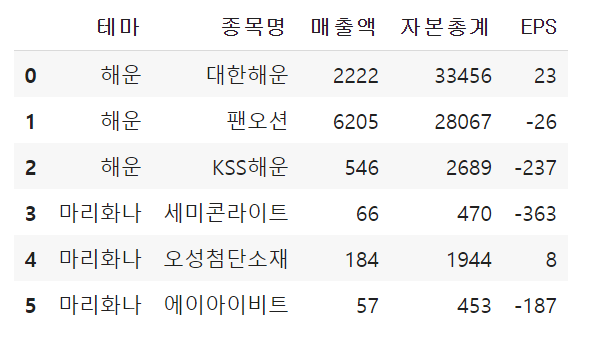
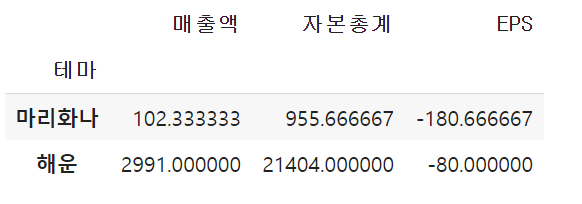
(10) 특정 column별로 평균내기 - groupby()
df5.groupby('테마').mean()🌟 테마를 기준으로 다른 모든 숫자형 값들에 대해 컬럼별로 평균을 구한다
-
Before
-
After
.jpg)
취준생