회사에서 발표한 자료를 공유합니다.
들어가며
- b tree file 기반 DB는 오랫동안 성능과 안정성에 테스트를 거쳐와서 많은 곳에 사용되고 있습니다.
- b tree file 기반 DB 는 Read는 안정적이고 빠르지만, Write Operation 이 느립니다.
- 업데이트 시 두개 이상의 쓰기를 하기 때문입니다.
- WAL (write ahead log) 쓰기
- index와 row 를 업데이트
- random key 에 대해서 memory page hit 비율에 따른 성능 차이 존재
- b tree index 에 밸런싱이 필요하면 간혹 많은 disk 변화가 필요합니다.
- 업데이트 시 두개 이상의 쓰기를 하기 때문입니다.
- 이런한 write operation 문제를 이 개선한 Log Base DB를 소개하려고합니다.
- 간단한 구조부터 만들어가보면서 차차 단점을 개선해보고, 그로 인한 특성을 이해해보고자 합니다.
Log DB V1.0
간단한 로그 기반 DB를 만들어봅시다.
수도 코드
db_set (key,value) {
// database 라는 파일에 ${key},${value} 로 만들어서 append 한다.
}
db_get (key) {
// database 에 첫번째 argument 로 시작하는 모든 줄을 찾는다.
// 마지막 라인의 value를 return 한다.
// 혹은 뒤에서 부터 읽어온다
}사용 예시
ternimal
db_set 1 jaquan1
db_set 2 jaquan2
db_set 1 jaqquan1_update
db_get 1 -> jaqquan1_update
db_get 2 -> jaquan2database file
1,jaquan1
2,jaquan2
1,jaquan1_update어떤 특성이 있을까요?
- 장점 : disk write 가 append only 여서 빠르다
- 단점 :
- key의 오래된 값이 남아있는다.
- read 할때 매번 파일 전체를 읽어서 조회를 해야해서 느리다.
- 개선방안
- read 시 문제를 해결하려면 index를 만들자
-> 간단하게 key 별로 disk offset 을 저장해보면 어떨까?
- read 시 문제를 해결하려면 index를 만들자
Log DB with Offset Index V1.1
수도 코드
index:= map[string]int{}
db_set (key,value) {
// database 라는 파일에 ${key},${value} 로 만들어서 append 한다.
// append 시 return 으로 디스크에서 삽입된 라인 수를 받는다.
// index[key] = offset
}
db_get (key) {
// offset := index[key]
// 없으면 null 로 return
// offset 으로 database 에 접근해서 한줄을 읽는다.
// value를 return 한다.
}동작
terminal
db_set 1 jaquan1
db_set 2 jaquan2
db_set 1 jaquan3
db_get 1 -> jaquan3
db_get 2 -> jaquan2database file
1,jaquan1
2,jaquan2
1,jaquan3
... index in memory
{
"1":3L
"2":2L
}어떤 특성이 있을까요?
- 장점 : write 또 빠르고, read 도 빠르다
- 단점
- 여전히, update 가 많아진다면 필요 없는 용량이 많아진다.
- 개선방안
- 주기적으로 불필요한 파일을 날리는 Compaction 을 하자
Log DB with Offset Index, Segment V1.2
Segment
- compaction 을 실행할 때, 동시성 문제를 피하면서 수행하기 위해 immutable file 단위로 쪼개보자
- 쪼개진 파일 단위를 segment 라고 하자
수도 코드
segmentId:= 0
db_set (key,value) {
// database_{segmentID} 라는 파일에 ${key},${value} 로 만들어서 append 한다.
// append 시 return 으로 disk 에서 라인 수를 받는다.
// index_{segmentID}[key] = offset
// database_{segementID} 파일이 특정 크기를 넘어가면 segmentID 를 올린다.
}
db_get (key) {
// key 를 찾을때까지 segmentID 를 순회한다.
// while (index_{segmentID}[key)){
if segmentID == 0 {
return null
}
segmentID-=1
}
// offset 으로 database_{segmentID} 에 접근해서 한줄을 읽는다.
// value를 return 한다.
}동작
segment 단위를 3L 으로 한정한다고 가정하자
terminal
db_set 1 jaquan1
db_set 1 jaquan2
db_set 1 jaquan3
// segement id 1 증가
db_set 1 jaquan4
db_set 1 jaquan5
db_set 1 jaquan6
// segemetn id 1 증가
db_set 1 jaquan7
db_set 1 jaquan8
db_get 1
-> index_{2} 에서 찾아서
-> jaquan8
db_get 2
-> index_{2} 에서 찾고
-> index_{1} 에서 찾고
-> index_{0} 에서 찾고
-> 없네!
database_{0}
1,jaquan1
1,jaquan2
1,jaquan3database_{1}
1,jaquan4
1,jaquan5
1,jaquan6database_{2}
1,jaquan7
1,jaquan8index_0 (memory)
{
"1": 3L
}index_{1} (memory)
{
"1": 3L
}index_{2} (memory)
{
"1": 2L
}Log DB with Offset Index, Segment, Compaction V1.3
Compaction
- 현재 사용중인 segment 를 제외하고는 더이상 변화가 없는 immutable 한 파일이다.
- 이를 가지고 write 에 대한 걱정 없이 불필요한 부분을 제거(merge) 할 수 있다.
수도 코드
... 위와 같음
background_compaction_cron_job (){
// 연속된 version의 segement 파일들을 가지고 와서
// key 를 최신화 한다.
// 컴팩션된 오래된 파일과 인덱스는 제거한다.
}
background_compaction_cron_job()동작
- 2번은 write 되는 대상임으로, 0과 1만 병합할 수 있다.
database_0
1,jaquan1
1,jaquan2
1,jaquan3database_1
1,jaquan4
1,jaquan5
1,jaquan6⇒ compaction_database_{0,1}
1,jaquan6⇒ compaction_index_{0,1}
{
"1": 1L
}어떤 특성이 있을까요?
- 장점
- write 도 빠르고 read 도 빠르다.
- 불필요한 disk 를 병렬 처리 문제를 피하면서 compaction 할 수 있다.
- 단점
- read 시에 순회하게 되는데, 넣은 적 없는 key를 찾으려면 매번 모든 segment 대상으로 full scan을 하게 된다.
- key range 쿼리는 불가능하다
- 1~10 사이에 item을 가져오지 못한다.
- key 는 모두 메모리에 들고 있어야 한다.
- 키가 엄청 많은 요청에 대해서는 관리가 어려워질 수 있다.
- 어떻게 개선할 수 있을까요?
- read 개선 방안
- read 시 bloom filter를 도입한다.
- bloom filter 란
- 여러 hash function 을 통해 없음을 보장 할 수 있는 확률적 자료구조
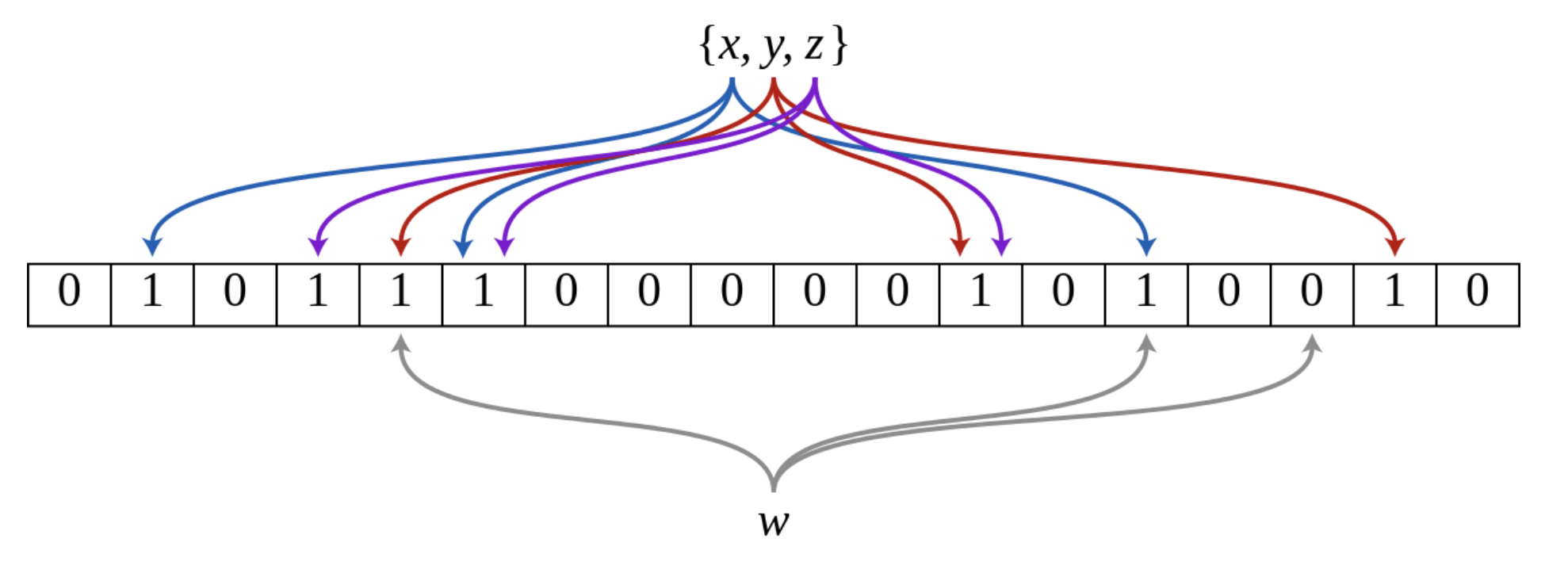
- False positive matches are possible, but false negatives are not – in other words, a query returns either "possibly in set" or "definitely not in set"
- 여러 hash function 을 통해 없음을 보장 할 수 있는 확률적 자료구조
- range query 및 메모리 사용량 개선 방안
- key range query를 지원하고 메모리를 줄이기 위해서는 LSM tree와 SS table 이라는 개념을 도입하면 가능하다.
- read 개선 방안
LSM(Log structured merge) tree with SSTable V1.4
앞서 다뤄본 고민들을 개선한 LSM table(with sstable) 을 소개합니다.
LSM table 과 SS Table
Write 시 동작
- in-memory 구조체인 memtable 에 넣기
- 임시 log file 에 쌓기
- in memory 인 memtable 은 휘발적이기 때문에, crash 대비용
- write operation 은 여전히 append only 여서 빠르다
memtable 이란?
in memory 안에 balanced b tree 형태로 key, value 들을 들고 있는 자료 구조를 뜻한다.
- 메모리 사이즈를 유지하기 위해서, 일정 크기가 지나면 키를 순회하면서 sstable 을 disk에 작성
- balanced b tree 이기 때문에, SStable에는 sorted 된 key 로 정렬되어서 저장할 수 있음
- sstable 작성도 append only 여서 write가 빠름
- sstable 작성이 완료되면 임시 log 파일을 제거한다.
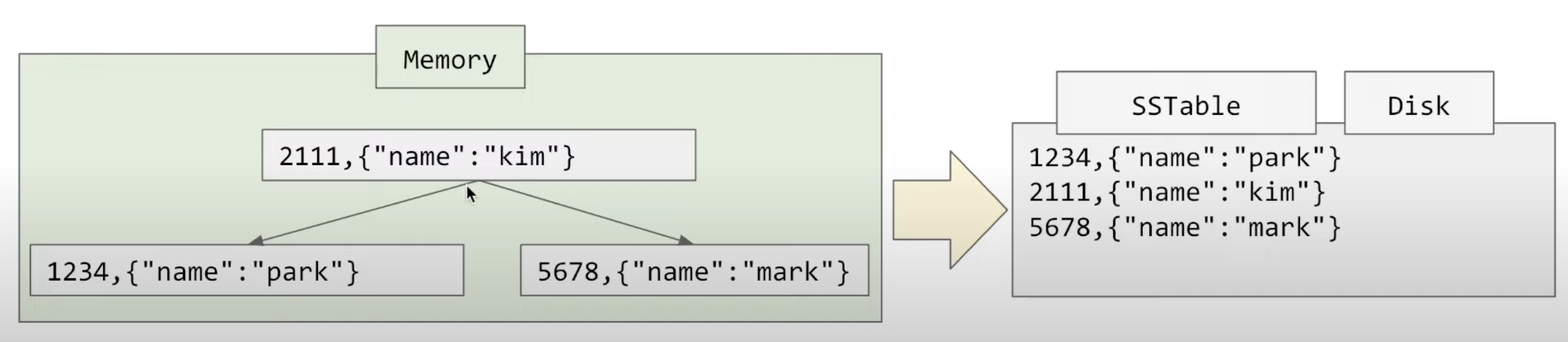
SS table (string sorted table) 이란?
disk 안에 key 를 sorted 하게 보관하고 있는 segment
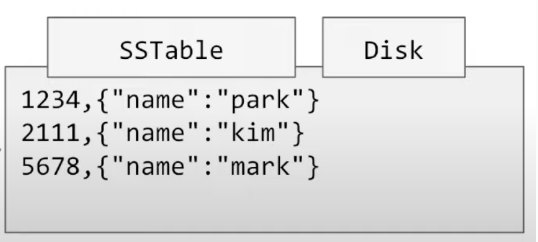
-
file full scan query 를 개선하기 위해서 offset key index 를 들고 있는다.
-
다만, sorted 되어있기 때문에 부분적으로만 들고 있을 수 있다.

-
예를 들어서 key
2111은 memeory index에 없어도 유추해서 찾을 수 있다. -
또한 range query 를 수행 할 수 있다.
-
-
주기적으로 compaction 을 통해 최적화를 진행한다.
최종 구조
- memtable 과 sstable 들을 조합으로 구성되어있다.
- 해당 구조 때문에, 어색하지만 lsm Tree 라고 부른다.
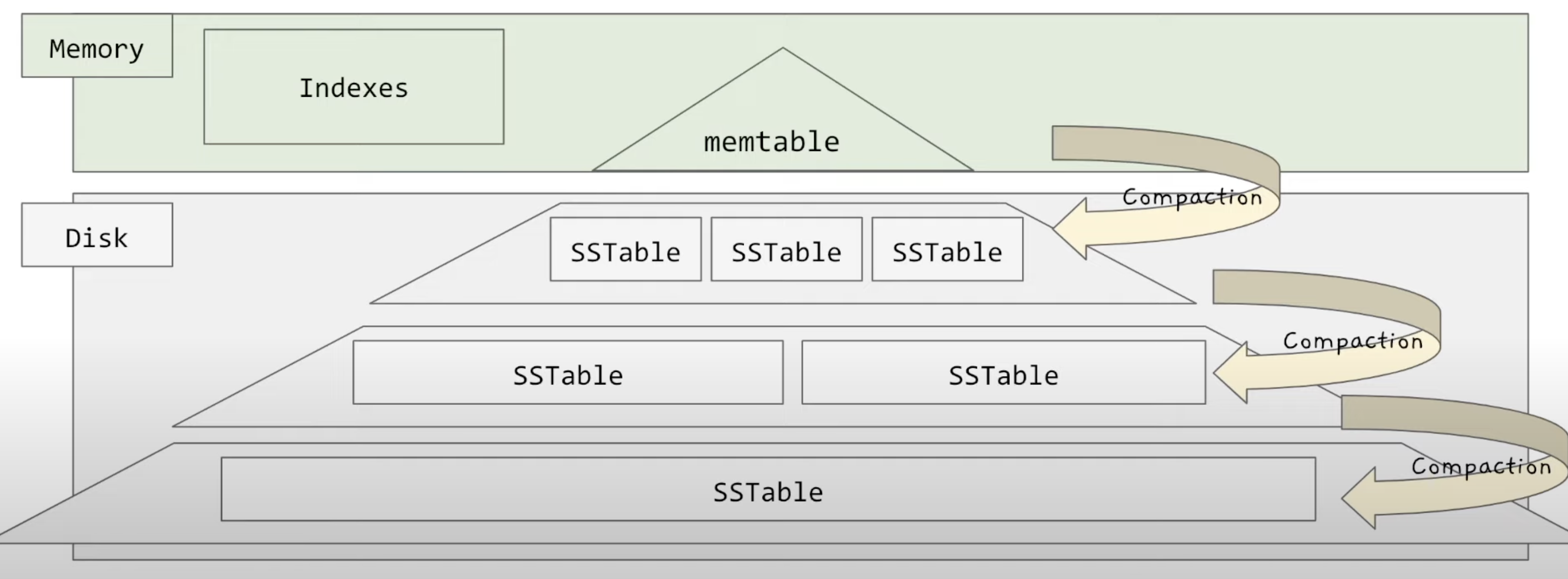
Read 동작 정리
- key 가 들어오면
- memtable 안에 있는지 확인
- 없다면 sstable과 sparese index 을 순차적으로 조회
- bloom filter 를 도입하여 성능을 개선 시킬 수 있다.
Write 동작 정리
0.key,value 가 들어오면
1. memtable, 임시 로그 파일에 삽입
2. memtable 의 사이즈가 일정 이상이면 sstable 로 변환
2. 주기적으로 segment 단위당 머지를 수행
마무리 하며
언제쓰면 좋을까
- Write 많고 Read가 적을때 사용
- 키가 많지 않을때 사용되면 좋다
실제로 많이 사용하나요?
- cockroach의 peddle, cassandra 등에서 각 노드의 엔진으로 사용 중
- 의외로 dynamoDB는 사용하지 않는다.
- NoSQL 들의 write 처리량이 많고 빠른 이유 중에 하나가 됩니다.
- 또한 NoSQL 의 key value hashed Cluster 를 생각해보면, key 단위로 second index 를 구성할 수 있는 좋은 조합이 됩니다.
참조
