
회사에서 발표한 자료를 공유합니다.
원제목: 다이나모: 아마존의 고가용성 키-값 저장소
들어가며
- dynamo 의 논문이 나오고 해당 구조는 많은 DB 에 영향을 줬습니다. (카산드라, 리악 등)
- aws 에서 dynamo를 설계할 당시 초기 요구조건과 방법, 그 안에 문제들과 해결책들을 살펴보려고 합니다.
- 그러면서 분산 시스템의 여러 개념들에 대해서 소개하려고 합니다.
- 단, 현재 aws 의 여러 새 조건들 때문에 DynamoDB 는 아래의 개념과 다르게 구현된점 참고 바랍니다.
요구조건과 분석
요구 조건
- 초당 수천만 건의 요청을 처리할 수 있어야 하며 요청은 점차 증가 할 수 있다.
- 서비스가 요청의 99.9%에 대해 300ms 이내에 응답 (일정한 시간 초 내에 응답)
- 디스크 장애가 발생하거나, 네트워크 문제가 생기던가, 토네이도로 인해 데이터 센터가 망가져도 사용가능해야한다.
- pk 접근 하여 읽거나 저장하는 등의 복잡도만 가지고 있고 복잡한 쿼리나 RDBMS에서 제공하는 조인, pk 쿼리등 관리 기능을 사용하지는 않는다.
- 데이터 정합성은 엄격하지 않아도 되고, 1초 이내에 맞춰지면 된다.
분석
- 초당 수천만 건의 요청을 처리할 수 있어야 하며 요청은 점차 증가 할 수 있다.
→ scale out 한 구조가 필수다
→ 데이터 파티셔닝(shard)이 중요하다
→ 고가용성을 보장하기 위해서 node의 대칭성을 보장해야한다. (모든 노드는 서로 동등한 책임을 져야한다.)
-
서비스가 요청의 99.9% 에 대해 300ms 이내에 응답 (일정한 시간 초 내에 응답)
→ constant 한 latency 를 보장하기 위해서는 index로 B tree를 사용하는데 무리가 있다. -
디스크 장애가 발생하거나,네트워크 문제가 생기던가,토네이도로 인해 데이터 센터가 망가져도 사용가능해야한다.
→ 고가용성이 매우 중요하다.
→ 다중화가 매우 용이한 구조여야 한다.
→ 다중화 하면서 중요한 데이터 전파, 장애 복구, 정합성 보장 등을 잘 처리해야한다. -
pk 접근 하여 읽거나 저장하는 등의 복잡도만 가지고 있고 복잡한 쿼리나 RDBMS에서 제공하는 조인, pk 쿼리등 관리 기능을 사용하지는 않는다.
→ index 를 hash 로 써보면 좋지 않을까? -
데이터 정합성은 엄격하지 않아도 되고, 1초 이내에 맞춰지면 된다.
정리
- 고가용성을 보장하기 위해 symetric 한 노드로 구성해야하고,
- 각 노드들은 데이터 파티셔닝에 유리한 구조여야 하며
- index 로는 해시구조를 이용해야한다.
파티셔닝 전략 - Consistent Hashing
Hash 로 Node 정하기 - 개념과 문제점
핵심 아이디어
- 특정 데이터를 찾을때 key 를 가지고 Hash 하여 접근한다고 가정하면 2번 조건과, 4번 조건안에서 구조를 설계 할 수 있다.
- 담당하는 node ID =
hash(key) % len(node)
- 담당하는 node ID =
문제점
- node 의 갯수가 달라질때, 많은 데이터의 책임 노드가 변경되어서 많은 데이터를 이동시키는 과정을 가져야함
- 데이터 이동이 많아지면 네트워크 비용, 실패 확률, 이동에 걸리는 시간이 높아져서 운영 측면에 좋지 않음
- 특정 하나의 노드로 고정해버리면 고가용성을 보장하기가 어려움
Consistent Hashing
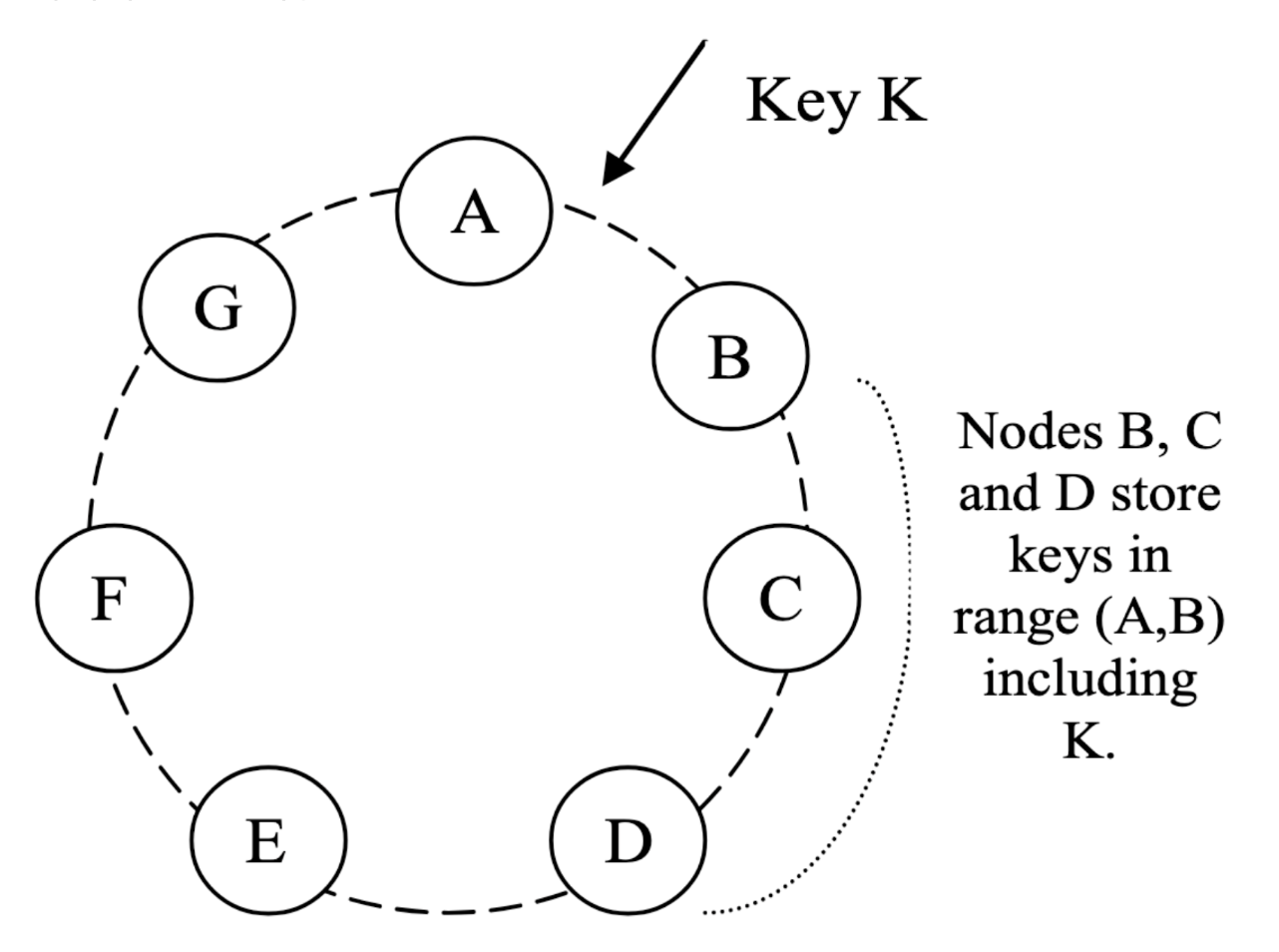
- hash 함수의 반환 범위를 링(가장 큰 해시 값과 가장 작은 해시 값이 연결된 고리 형태)으로 가정한다
- 시스템의 각 노드는 이 공간 안의 랜덤 값을 배정
- 자신의 키를 해싱하여 위치를 산출한 다음, 링을 시계 방향으로 돌며 자신의 위치보다 큰 위치에 있는 첫 번째 노드에 자신을 할당한다.
- 복제시 요청 받은 가장 인접한 노드(B) 가 코디네이터 역할을 하여서 range에 대해서 복제를 담당한다.
- 코디네이터 노드가 자신의 로컬 및 시계 방향 N-1개 까지 하여 N개의 복제를 운영한다.
이점
- 노드의 추가 삭제시 데이터들은 인접한 노드로만 적당량의 데이터만 이동하면 된다.
- 한 key에 대해서 여러 노드들이 책임을 질 수 있다.
문제와 대책
- 링에 있는 각 노드의 위치를 랜덤하게 배정하면 불균형한 부하 분산을 야기할 수 있다.
- 기본적인 알고리즘은 노드의 성능을 신경쓰지 않는다.
→ 가상 노드 도입으로 해결
- 단순히 원 위에 하나의 점으로 노드를 매핑하는 것이 아니라, 각 노드에 여러 개의 위치를 배정하는 것이다. 이를 위해 다이나모는 “가상 노드”(virtual nodes)라는 개념을 사용한다.
→ 고르게 분산 할 수 있다. (뭉칠 가능성이 줄어든다)
→ 성능에 맞게 가상 노드 갯수를 조절하여 성능에 맞는 부하를 줄 수 있다.
데이터 일관성 보장 전략
- 높은 가용성을 보장을 위한 일관성 보장을 포기할 수 밖에 없다. (
CAP 이론)- CAP 이론이란?
- consistency(일관성), availabilty(가용성), parition tolerence(분할 허용성) 이론으로 “적절한 응답 시간 내 세 가지 속성을 모두 만족시키는 분산 시스템을 구성할 수 없다”는 이론이다.
- 분할 허용성은 분산 시스템에서 있을 수 밖에 없으니, C 나 A 중에 집중해야한다.
- CAP 이론이란?
- DDB 는 어떤방식으로 가용성을 보장하고, 일관성을 유지하려 최대한 노력 하려했는지 전략을 살펴 본다.
Quorum Consensus (정족수 합의)
Quorum Consensus 란
-
Quorum (정족수) 뜻
- 합의체가 의사를 진행시키거나 의결을 하는 데 필요한 최소 한도의 인원 수
- 분산 시스템에서는 보통 노드의 갯수를 뜻한다.
-
replica 끼리 일관성을 보장하기 위한 read/write 설정
- N - 시스템의 총 노드 수 W - 성공적인 쓰기 작업에 필요한 최소 노드 수 R - 성공적인 읽기 작업에 필요한 최소 노드 수
- 예를 들어 replica 갯수가 3 인 경우 (N=3)
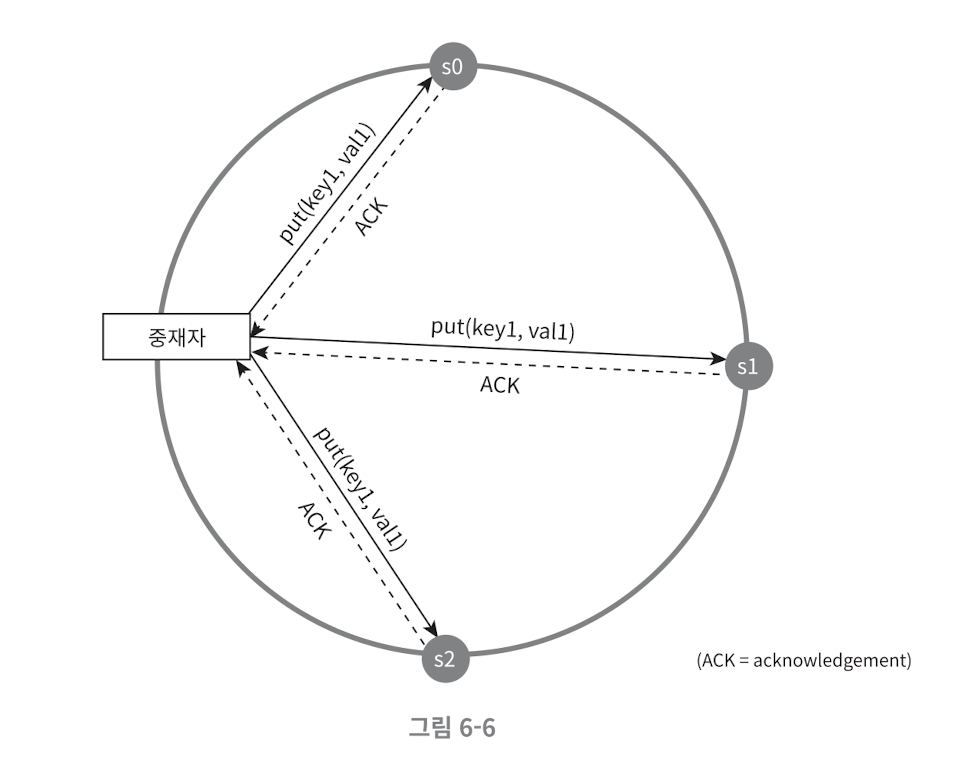
- R=1 , W=3 인 경우 (R+W>N)
- 빠른 읽기가 가능
- R=3, W=1 인 경우 (R+W>N)
- 빠른 쓰기 가능
- R=2, W=2 인 경우 (R+W>N)
- 적당히 빠른 읽기와 적당히 빠른 쓰기
- R=1, W=1 인 경우 (R+W≤N)
- 빠른 읽기와, 빠른 쓰기가 가능하지만 업데이트가 되지 않은 결과가 반영될 수 있음
- 강한 일관성 보장 (R+W>N)
- 모든 읽기 연산은 최근 성공한 쓰기의 결과를 반영 한다.
- 단, 레플리카의 일부 장애가 있을 시, 실패하는 경우가 증가하여 가용성이 떨어 질 수 있음
- 약한 일관성 보장 (R+W≤N)
- 강한 일관성이 보장 되지 않음 (약한 일관성)
- 최종 일관성은 약한 일관성의 종류
Dynamo 의 Qurom Consensus
- 다이나모는 모든 레플리카(해당 키를 담당하는 노드)에게 업데이트를 비동기적으로 전달하고, 최종 일관성만 보장 하면 된다.
- 그렇다면 간단하게 약한 일관성 보장을 사용하면 된다
- 퀴즈 - 다이나모의 정족수는 어떻게 되을까 (N=3 이라고 한다면)
-
N=3, R=2, W= 2
(N, R, W) 설정은 많은 다이나모 인스턴스에서 일반적으로 (3, 2, 2)으로 사용된다. 이 값은 SLA에서 요구하는 수준의 성능, 내구성, 일관성, 가용성을 충족하기 위한 것이다.
-
약한 일관성 보장을 사용하면 장애가 없는 상황에서도 꽤 자주 사용자가 의도치 않게 업데이트 되지 않은 상황을 경험하게 됨
-
- 퀴즈 - 다이나모의 정족수는 어떻게 되을까 (N=3 이라고 한다면)
Sloopy Consensus(느슨한 정족수) 그리고 Hinted handoff(임시 위탁)
- 간단한 설명 : 강한 일관성을 평소에 유지하다가 노드들이 다운되면 백업 노드에 임시로 저장하고 살아나면 다시 받아온다.
- 노드 A가 쓰기 동작 도중에 일시적으로 다운되거나 접근할 수 없게 된다면 A에 존재했던 데이터가 노드 b로 전송된다.
- 노드 B로 보내진 레플리카는 메타데이터에 어떤 노드가 원래 수신자(여기서는 노드 A)였는지 암시하는 단서를 포함하고 있다.
- 임시 위탁된 레플리카를 수신하는 노드는 주기적으로 스캔되는 별도의 로컬 데이터베이스에 레플리카를 보관한다.
- 노드 A가 복구되었음을 감지하면, 노드 B는 레플리카를 노드 A에게 전달한다. 전송이 성공적으로 끝나면, 노드 B는 로컬 저장소에서 객체를 제거한다.
- 장애 해결 후 업데이트를 공유하는 이 프로세스를 hinted handoff 라고 한다.
- 네트워크 장애가 발생하면 시스템은 sloopy consensus을 사용하여 쓰기 작업을 성공한 것으로 표시하지만, 이 업데이트된 레코드의 모든 노드가 가장 최근 업데이트와 동기화되는 것은 아닙니다.
- 따라서 시스템의 클러스터가 서로 통신할 수 없더라도 클라이언트가 오래된 클러스터에 읽기 요청을 보낼 수 있으며 오래된 값을 수신할 수 있습니다.
- 결국 일관된 결과를 허용할 수 있는 시스템이 이 방법론에 가장 적합한 후보입니다
- 실제 사례 : 여러분이 휴식을 취하고 있을 때 동료가 여러분을 대신하여 메시지를 받고 여러분이 돌아와서 그 메시지를 공유하는 경우입니다.
- 돌아왔는데 메시지가 공유되기 전에 질의를 한다면 강한 일관성이 깨진 정보를 보게 된다.
Vector Clock
문제 상황
- 앞서 이야기한 것 처럼 느슨한 정족수 및 임시 위탁을 사용하는 Dynamo는 최종적 일관성만을 보장한다. 따라서 다음과 같은 상황이 생길 수 있다.
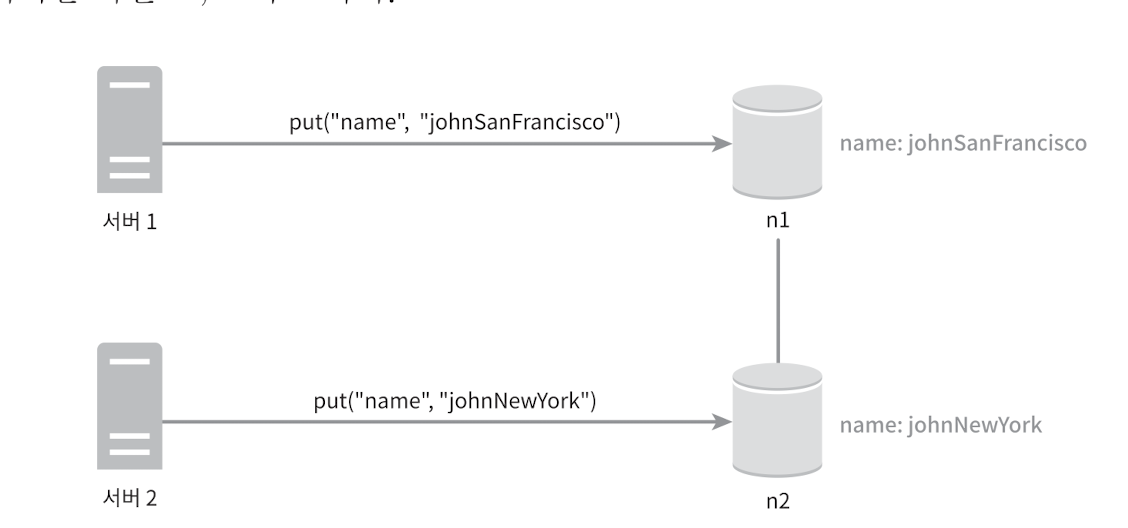
- 어떻게 충돌을 해소해야하나?
-
상황 1
- 서버 1 에서 john→ johnSanFancisco 에서 업데이트 하고 서버 2에서 해당 결과 값을 받은 후 johnSanFancisco→ johnNewYork 으로 변경한 상황
- → johnNewYork 이 맞다
-
상황 2
- 서버 1 에서 john → johnSanFancisco , 서버 2에서 john→johnNewyork 을 한 순간
- → conflict 라서 둘 중 하나를 포기하여야 한다.→ 만약 set , array 라면 더 복잡해진다.
-
vector clock(벡터 클럭)
- 어떤 버전이 선행 버전인지, 후행 버전인지, 아니면 충돌이 있는지(중재가 필요한지) 판단하는데 사용한다.
- 벡터 시계는 [node 번호, 버전] 의 순서쌍을 데이터에 단 형태를 말한다.
- D([S1,V1], [Sn,Vn])
- 서버 Sn 에 D를 기록하면 [Sn,Vn] 가 있으면 Vn 을 증가시킨다.
- 그렇지 않다면 새항목 [Sn,1] 을 만든다.
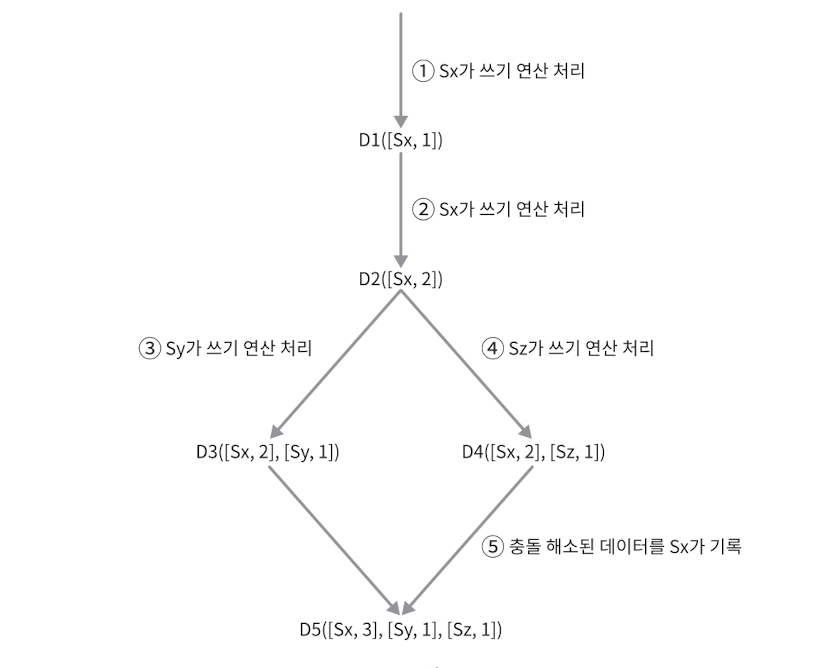
- 5번 과정에서 충돌 해소가 될 수 있는지, 혹은 Last-Write-Win(최종 쓰기 승리) 등으로 합쳐버릴지, 에러를 만들지는 결정해서 구현하면 된다.
- 다이나모가 다양한 버전에 대해 단순한 타임스탬프 기반 중재 로직을 수행하여 "최종 쓰기 승리"를 적용한다
- 추후에 너무 벡터가 길어지면 클럭 절단(truncation) 방식을 사용한다. 임계치(가령 10개)에 다달았다면, 오래된 페어를 클럭에서 제거한다.
- 버전 벡터의 효용성 측정
다음 실험에서, 장바구니 서비스에 반환된 버전의 개수는 24시간 동안 집계되었다. 이 기간 동안 요청의 99.94%는 단 하나의 버전을 응답받았다. 요청의 0.00057%는 두 개의 버전을 받았고, 요청의 0.00047%는 3개 버전, 요청의 0.00009%는 4개 버전을 받았다. 이는 버전 분기가 거의 일어나지 않음을 보여준다.
장애 감지와 처리
장애 감지는 어떻게 이뤄질까?
- 하트비트, 핑, 하트비트 아웃소싱, 가십 프로토콜 등이 있다
- 하트비트 : 나 살아있다
- 핑 : 살았니?
- 하트 비트 아웃소싱: 결과의 신뢰성을 높일 수 있는 방법. 각 프로세스는 네트워크의 모든 프로세스가 아닌 일부 주변 프로세스의 존재 여부만 알아도 된다.
- 친구가 연락 안받으면, 주변 지인(다른 친구, 친구 부모님)한테 물어보는 격 (아까 승민이 10분전에 집에 갔어요)
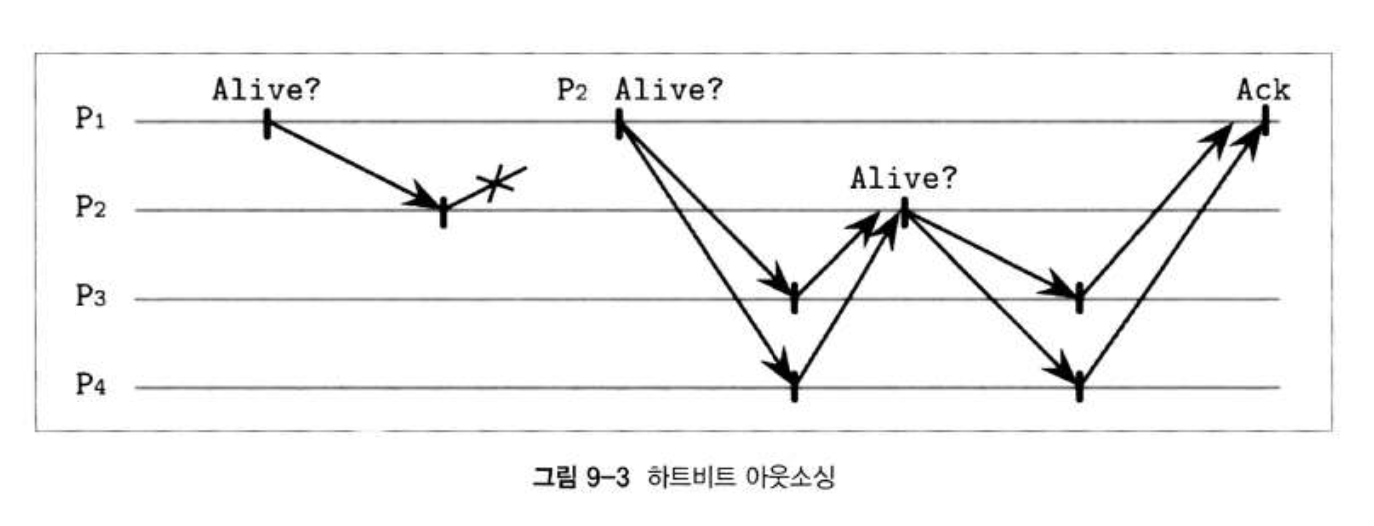
- 친구가 연락 안받으면, 주변 지인(다른 친구, 친구 부모님)한테 물어보는 격 (아까 승민이 10분전에 집에 갔어요)
- 다이나모는 그 중에 가십 프로토콜을 이용한다.
가십 프로토콜
- 각 노드는 전체 노드 목록과 각 노드의 하트비트 카운터 그리고 마지막으로 카운터가 증가된 시간을 나타내는 타임스탬프 값을 저장한다.
- 주기적으로 자신의 카운터를 업데이트하고, 목록을 임의의 노드로 전송한다.
- 목록을 전달받은 노드는 자신의 목록과 높은 것으로 머지한다.
- 일정 기간 동안 업데이트 되지 않은 노드가 있으면 해당 노드에 장애가 발생했다고 판단한다.
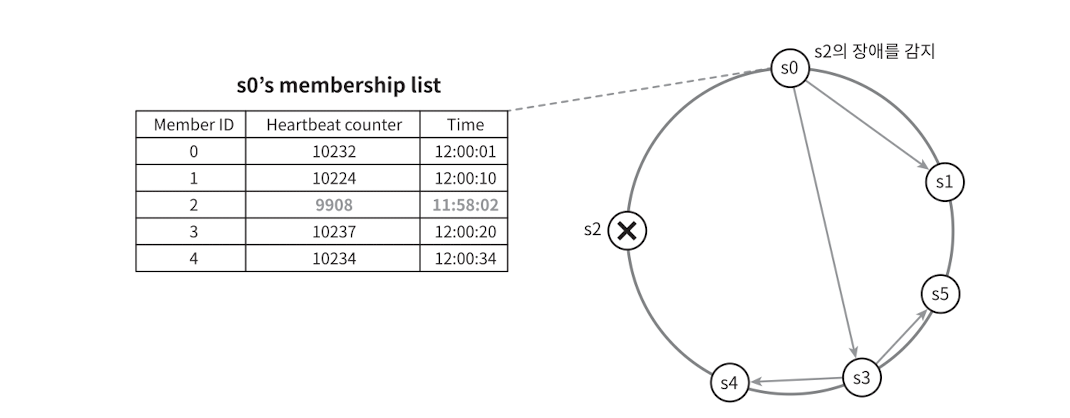
- 장애 뿐만 아니라, 노드의 추가 변경 등과 같은 변경 사항들에 대해서도 가십프로토콜로 전파한다.
- 왜 가십이라 불리냐
장애 처리 방식
-
노드가 죽었다가 다시 살아났을때, 모든 사본을 다 옮기는 일은 오래 걸린다.
-
레플리카 사이의 불일치를 빠르게 감지하기 위해, 그리고 전송 데이터의 양을 최소화하기 위해 머클 트리를 사용하여 비교한다.
-
머클 트리는 리프 노드가 개별 키에 대한 값의 해시인 해시 트리이다.
- 예를 들어, 두 트리의 루트 노드 해시 값이 같다면, 리프 노드도 같을 것이기 때문에 동기화가 필요하지 않다. 그렇지 않다면 일부 레플리카의 값이 다르다는 의미다.
- 이런 경우에 노드는 자식 노드의 해시 값을 교체하고, 트리의 리프 노드에 도달할 때까지 해시를 비교하며 어떤 키가 동기화되지 않았는지 알 수 있다.
-
storage를 어떻게 머클 트리로 유지하지?
-
key space가 1-12 까지 라면
-
1단계
- 키 공간을 다음과 같이 뭉텅이(버킷)로 나눈다. (여기서 4개라고 가정하자)
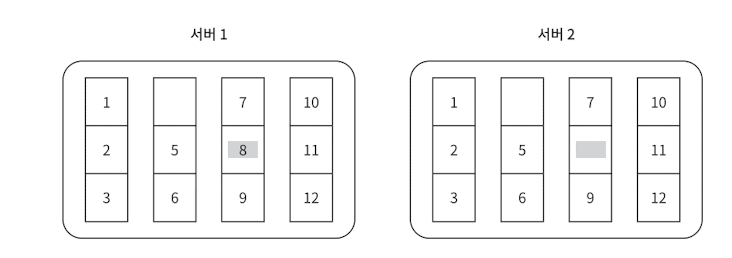
- 키 공간을 다음과 같이 뭉텅이(버킷)로 나눈다. (여기서 4개라고 가정하자)
-
2단계
-
각 key의 value 를 hash 하여 값을 계산한다.
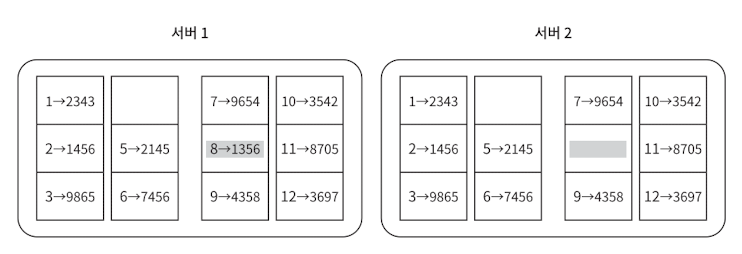
-
-
3단계
- 버킷 별로 해시값을 계산한 후, 해당 해시 값을 레이블로 갖는 노드를 만든다
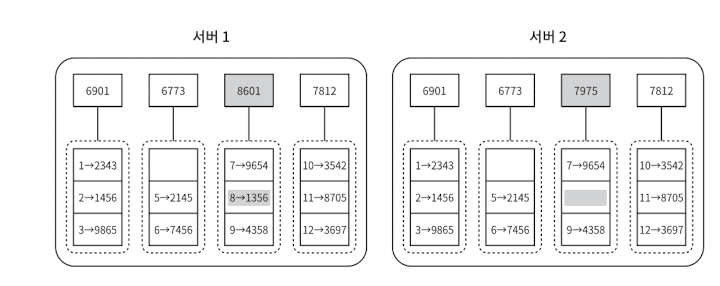
- 버킷 별로 해시값을 계산한 후, 해당 해시 값을 레이블로 갖는 노드를 만든다
-
4단계
- 자식 노드의 레이블로부터 새로운 해시 값을 계산하여, 이진 트리를 상향식으로 구성해 나간다.
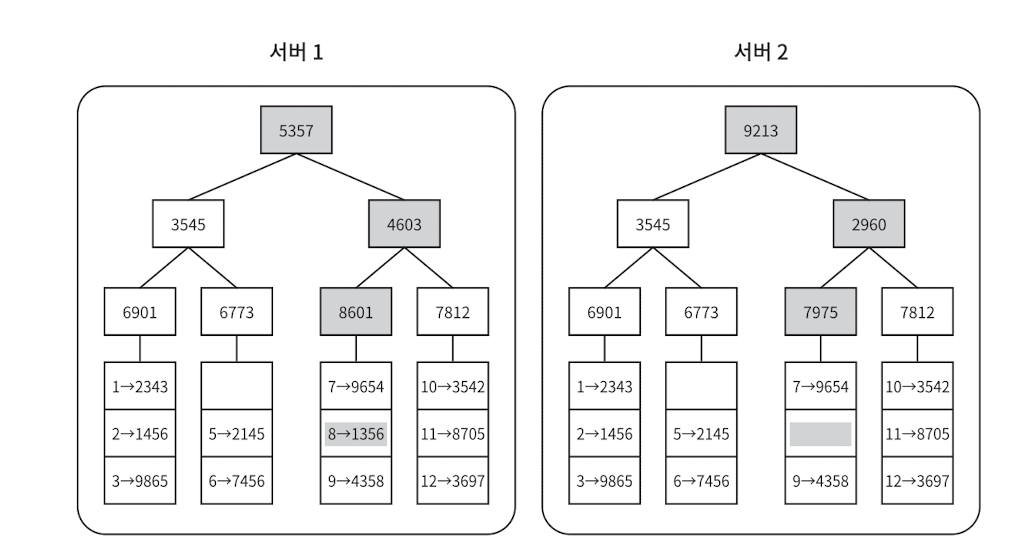
- 자식 노드의 레이블로부터 새로운 해시 값을 계산하여, 이진 트리를 상향식으로 구성해 나간다.
-
마무리하며
- 간단한 퀴즈
- 왜 다이나모는 primary key로 range 쿼리를 할 수 없나?
- gsi는 어떤 구조로 되어있을까?
- ddb의 consistent read 옵션은 어떻게 만들어졌을까?
- trasactionWrite는 어떻게 만들어졌을까?
- 아래는 논문에 나와있는 문제와 그 기술들이다.
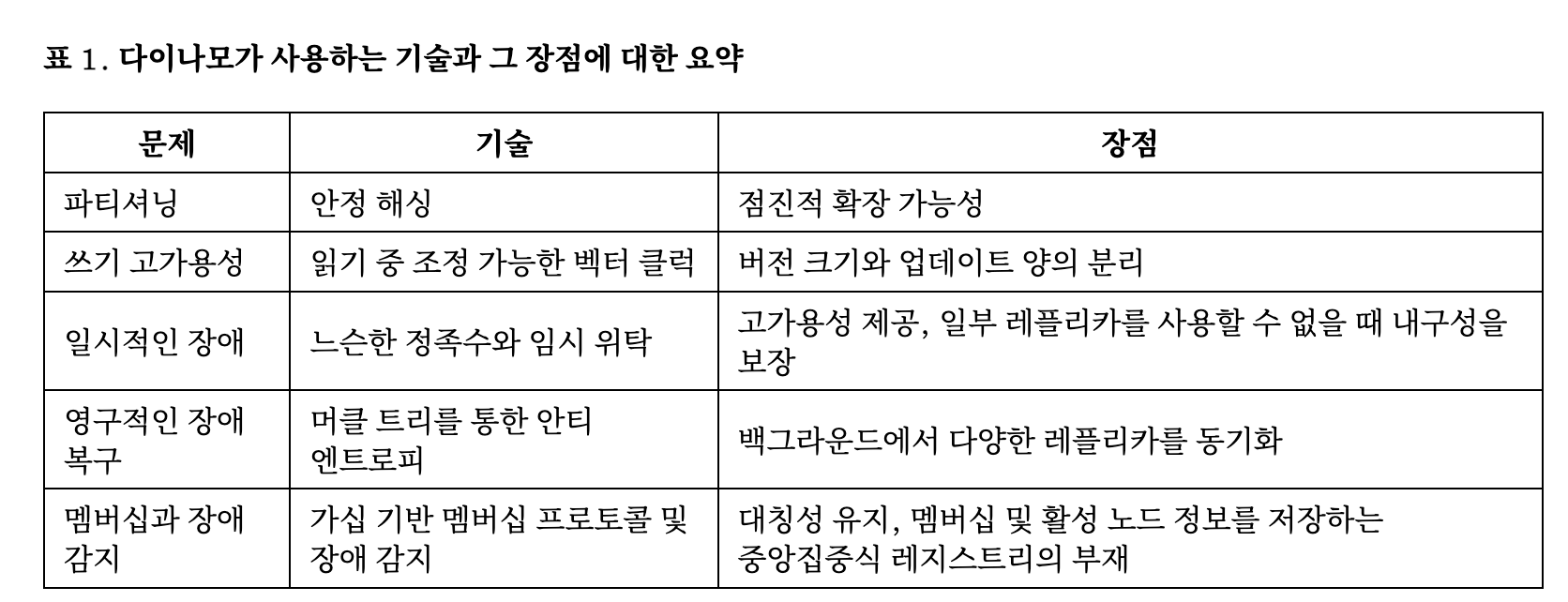
참조
