프로세서 개발자들은 단순히 명령어를 빠르게 처리하는 것 뿐만 아니라,
훨씬 더 복잡한 동작을 통해 CPU 성능을 늘릴 수 있는 다양한 기술을 개발해왔다.
지난 시간에 배운 것처럼, 16 나누기 4를 할 때 16 -4 -4 -4 -4와 같이 0 또는 음수가 나올 때까지 빼주는 방식으로 하면 클락 사이클이 너무 많이 소비되고 비효율적이다.
그래서 요즘 대부분의 컴퓨터 프로세서는 ALU에서 하드웨어로 처리하는 하나의 명령어로 나누기를 가지고 있다.
물론 이런 부가적인 회로들은 ALU의 크기를 크게 하고 설계를 복잡하게 하기도 하지만, 동시에 CPU를 더 능력있게 만든다.
복잡도 <- Trade Off -> 속도이러한 trade off는 컴퓨터 역사에서 여러번 있었다.
예를 들어, 현대 컴퓨터 프로세서는 특수 회로들을 가지고 있다.
그래픽 처리, 압축 비디오 복원, 파일 암호화 등과 같은 일을 처리하는 기능들은 표준적인 동작들로 수행하려면 어마어마한 클럭 사이클이 필요하다.
명령어 집합은 오래된 opcode들과 호환성을 유지하며 계속 확장되고 있다.(Backwards compatibility)
최초의 진정한 집적 CPU인 Intel4004는 46개의 명령어를 갖고 있었지만, 현대 컴퓨터 프로세서는 수천개의 명령어를 갖고 있다.
그런데 클럭 속도도 빨라졌고 명령어 집합도 커졌지만, CPU로 데이터를 가져오거나 내보내는 것이 과연 충분히 빠를까?
힘센 증기기관차가 있지만, 석탄을 빠르게 삽질해서 넣지 못한다면?

이 경우 RAM이 병목 지점이다.
RAM은 CPU 밖에 있는 메모리 모듈이다.
데이터를 버스라고 하는 데이터선들을 통해 RAM으로 전달되거나 RAM으로부터 가져와야 한다는 것이다.
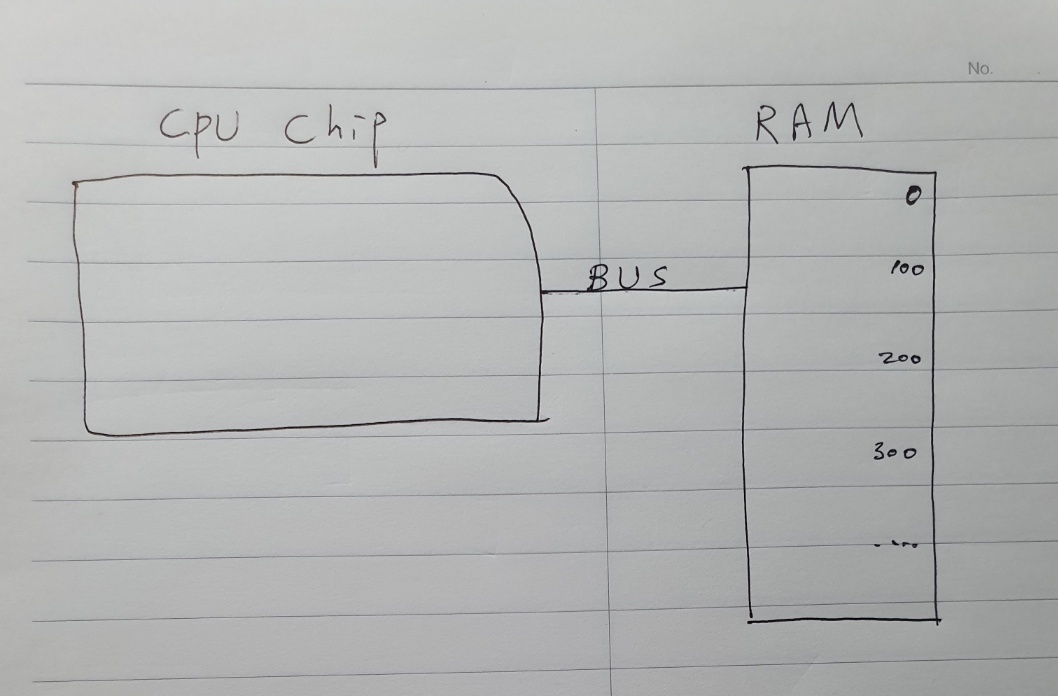
그런데 RAM은 주소를 보고 데이터를 찾아와서 출력시키는데 시간이 필요하다.
그래서 RAM에서 LOAD하는 명령어는 완료되는데 수십 클락 사이클이 필요할 수도 있고,

이 시간동안 프로세서는 데이터를 기다리면서 앉아서 놀고 있게 된다.

이를 해결하는 방법으로 캐쉬(cache)라고 하는 작은 RAM 조각을 CPU 안에 넣을 수가 있다.
프로세서 칩의 공간이 그리 크지 않기 때문에, 대부분의 캐쉬는 kilobyte에서 megabyte의 크기를 갖는다.
(RAM은 gigabyte의 크기)
CPU가 메모리의 한 위치에 접근할 때, RAM은 전체 데이터 블록 중에 달랑 값 한개를 전달할 수 있다.
만약 캐쉬에 데이터 블럭 전체를 저장한다면? 굉장히 도움이 된다!
ex. 프로세서가 식당의 일일 매상의 총합을 계산하는 일을 한다고 해보자.

RAM의 주소 100번지로부터 첫번째 거래 정보를 fetch하는 것부터 시작하자.
이 때 RAM은 값 1개만 보내는 것이 아니라, 100번지에서 200번지까지 데이터 블럭 전체를 보내서 캐쉬에 복사시킨다.
그러면 프로세서가 총합을 계산하기 위해 101번지에 있는 다음 거래 정보를 요청할 때 캐쉬가 CPU에 해당 정보를 바로 넘겨줄 수 있기 때문에 RAM까지 가야할 필요가 없다.
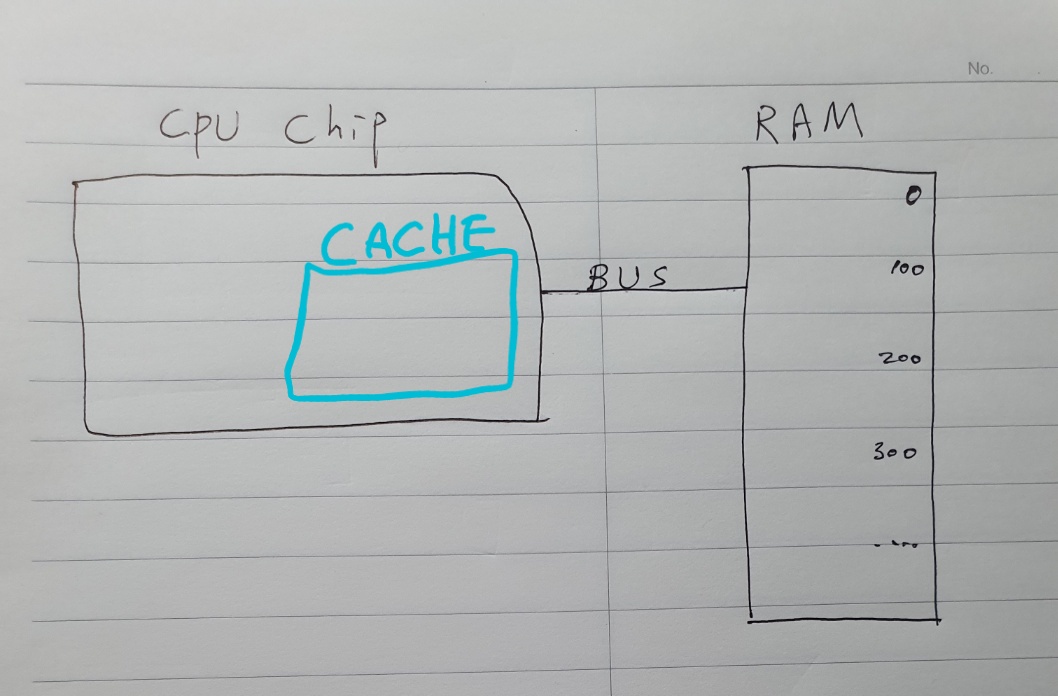
캐쉬는 프로세서에 딱 붙어 있기 때문에, 데이터를 한 클럭 사이클에 보내줄 수 있다.
이렇게 하면 매번 RAM에 왔다갔다 할 때보다 무시무시하게 속도를 향상시킬 수 있다.
RAM에 요청할 데이터가 이미 캐쉬에 저장되어 있는 경우를 캐쉬 히트(Cache hit)라고 한다.
반대로 캐쉬에 요청한 데이터가 없는 경우는 RAM까지 가야하는데, 이를 캐쉬 미스(Cache miss)라고 한다.
캐쉬는 길고 복잡한 계산을 할 때 중간값들을 저장하는 임시 저장소로도 사용할 수 있다.
프로세서가 하루 전체 매출 계산을 끝냈고, 그 결과를 150번지에 저장한다고 해보자.
마찬가지로 이 값을 저장하기 위해 RAM까지 가는 대신 캐쉬에 저장할 수 있다.
그게 저장도 더 빠르고, 나중에 계산이 필요하면 더 빨리 접근할 수 있게 된다.
그런데 이렇게 하면 인터뤠스팅한 문제가 발생한다.
캐쉬에 복사된 데이터와 실제 RAM에 있는 데이터가 달라질 수가 있다.
이렇게 발생한 불일치는 반드시 기록해두어야만 특정 시간에 동기를 맞출 수가 있기 때문에, 캐쉬는 저장된 각 메모리 블럭에 대한 특별한 플래그가 있다. 이를 dirty bit라고 한다.
캐쉬가 꽉 차있고 프로세서가 새로운 메모리 블럭을 요청할 때 동기화가 가장 빈번하게 일어난다.
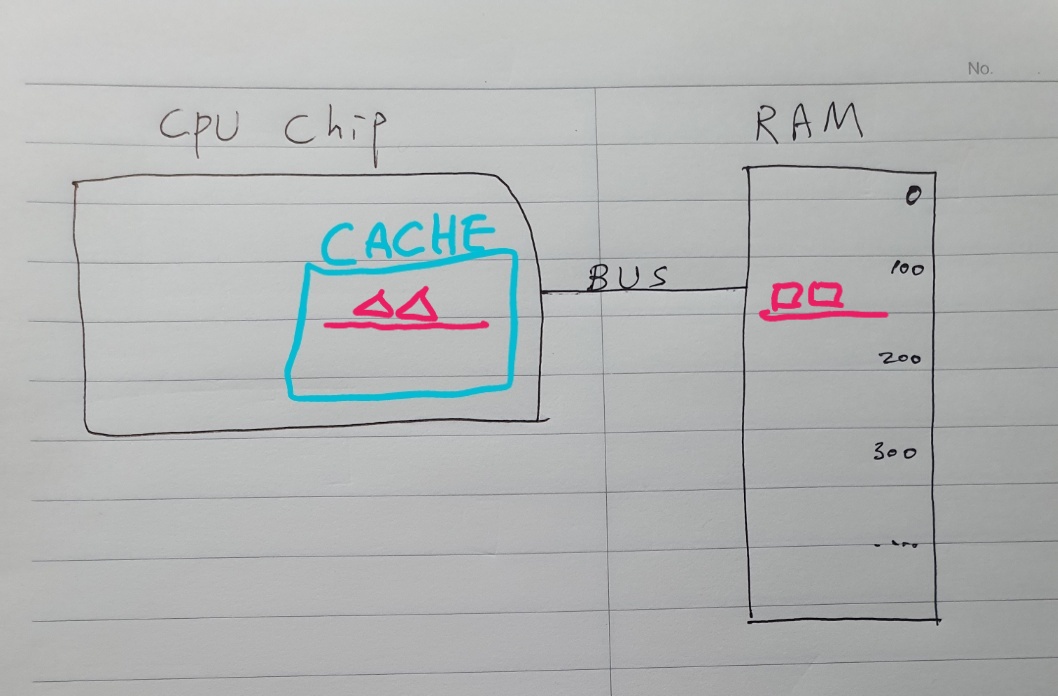
캐쉬가 오래된 블럭을 지워서 공간을 확보하기 전에 dirty bit를 체크하고, dirty하다면 새 블럭을 옮겨오기 전에 우선 오래된 블록을 RAM에 옮겨 적는다.
CPU 성능을 높일 수 있는 다른 트릭은 명령어 파이프라인이라는 것이다.
세탁기와 건조기가 있을 때 건조기가 끝날 때까지 기다리지 않고 세탁기를 동시에 돌리면 속도를 두배로 올릴 수 있다. 작업을 병렬로 처리하는 것이다.
프로세서에도 이런 원리가 적용된다.
에피소드 7에서 우리 예제 CPU는 fetch-decode-execute 사이클을 순차적으로 수행했다.
fetch-decode-execute,fetch-decode-execute,fetch-decode-execute,,,,즉, 명령어 하나를 수행하는 데 3개의 클럭 사이클이 필요하다는 것이다.
그런데 각 단계는 CPU의 서로 다른 부분을 사용하기 때문에 병렬 처리할 수 있는 기회가 있다.
명령어 1개가 execute되는 동안 다음 명령어를 decode하고 그 다음 명령어를 메모리에서 fetch할 수 있다는 것이다.
이렇게 분리된 과정들은 겹쳐져서 진행될 수 있어서, 언제나 CPU의 모든 부분이 동작할 수 있다.
fetch-decode-execute
fetch-decode-execute
fetch-decode-execute,,,,이런 파이프라인 형태에서, 명령어는 매 클럭 사이클마다 실행되어 처리 속도가 3배가 된다.
그런데 문제가 있다면 명령어 간의 데이터 의존성이 있는 경우이다.
데이터 의존성 참고:
https://velog.io/@jinh2352/%EC%BB%A8%ED%8A%B8%EB%A1%A4-%EC%9D%98%EC%A1%B4%EC%84%B1Dependency
이 문제를 보완하기 위해 파이프라인 형태의 프로세서는 데이터 의존성을 미리 내다볼 수 있어야 하고,
필요하다면 문제가 발생하지 않도록 파이프라인을 지연시킬 수 있어야 한다.
노트북과 스마트폰에 사용되는 고사양 프로세서들은 한 단계 더 나아가서, 파이프라인이 지연되는 것을 최소화하고 이동을 유지하기 위해 상호 연관성이 있는 명령어들의 순서를 동적으로 바꿀 수 있다. 이를 비순차적(out-of-order) 실행이라고 한다.
이런 모든 일을 수행하는 회로는 엄청나게 복잡하다.
그럼에도 불구하고 파이프라인은 효과적이어서 오늘날 거의 모든 프로세서는 파이프라인으로 구현된다.
또 다른 위험은 조건부 점프 명령어이다. 지난 강의에서 배운 JUMP_NEGATIVE 같은 것이다.
이런 명령어는 상태에 따라서 프로그램의 실행 흐름을 바꿀 수 있다.
단순한 파이프라인 프로세서는 점프 명령어를 만나면 오래 지연될 수 있다.
상태 값의 결정이 완료될 때까지 기다려야 하기 때문이다.
점프의 결과를 알아야지만 프로세서는 파이프라인을 다시 채우기 시작한다.
하지만 이런 상황은 긴 딜레이를 만들기 때문에 고사양 프로세서들은 이 문제들도 해결할 수 있는 몇 가지 트릭을 가지고 있다.
점프 명령어를 갈림길이라고 생각해보자.

고급 CPU는 예측 실행(speculative execution)이라는 기술로 어느 길로 갈지를 추측하고,
이 추측을 바탕으로 파이프라인에 명령어들을 채우기 시작한다.
만약 점프 명령어 실행이 완료되었을 때, CPU가 맞게 추측했다면 지연없이 진행할 수 있다.
올바른 명령어들이 파이프라인에 이미 채워져 있기 때문이다.
하지만 CPU가 추측한 것이 틀렸다면, 예상했던 결과들을 전부 버리고 pipeline flush라는 파이프라인을 싹 비우는 일을 한다. 마치 교차로에서 길을 놓쳐서 왔던 길을 유턴해서 되돌아가야 하는 상황이다.

이런 플러쉬에 의한 영향을 최소화하기 위해 CPU 제조사들은 분기 예측(branch prediction)이라는 어느 갈림길로 갈지 정교하게 추측하는 방법을 개발해왔다.
요즘 프로세서들은 50대 50 확률이 아니라 90% 이상의 정확도로 예측할 수 있다.
이상적인 케이스의 파이프라인은 매 클럭 사이클마다 하나의 명령어 실행을 완료할 수 있다.
하지만 매 클럭마다 한 개 이상의 명령어를 실행할 수 있는 슈퍼스칼라(super scalar) 프로세서가 등장했다.
superscalar : CPU 내에 파이프라인을 여러 개 두어 명령어를 동시에 실행하는 기술.
참고:
https://ko.wikipedia.org/wiki/%EC%8A%88%ED%8D%BC%EC%8A%A4%EC%B9%BC%EB%9D%BC
파이프라인 디자인에서도 execute 단계에서 프로세서 전체가 아무 일도 하지 않을 수 있다.
예를 들어 메모리에서 값을 fetch해야 하는 명령어를 실행하는 동안, ALU는 아무 것도 하는 일 없이 그대로 앉아 있어야 한다.

명령어 여러개를 한 번에 fetch하고 decode해 놓고, 가능한 시점에 CPU의 서로 다른 부분을 필요로 하는 명령어들을 동시에 실행한다면 어떨까?
많은 프로세서들은 4개, 8개 또는 더 많은 동일한 ALU를 사용해서 수학 연산을 병렬로 수행할 수 있다.
fetch-decode-execute
fetch-decode-execute
fetch-decode-execute
fetch-decode-execute
fetch-decode-execute
fetch-decode-execute...지금까지 하나의 명령어 흐름(stream)을 처리하는 속도를 최적화하는 기술들을 알아봤다.
성능을 높이는 또 다른 방법으로 멀티 코어 프로세서(Multi-core processors)를 가지고 여러개의 명령어 흐름들을 동시에 처리하는 것을 들 수 있다.
fetch-decode-execute fetch-decode-execute
fetch-decode-execute fetch-decode-execute
fetch-decode-execute fetch-decode-execute
fetch-decode-execute fetch-decode-execute
fetch-decode-execute fetch-decode-execute
fetch-decode-execute fetch-decode-execute...멀티 코어 프로세서: 하나의 chip 안에 여러개의 독립적인 프로세싱 유닛이 들어가 있는 것이다.
다수의 독립된 CPU를 갖고 있는 것과 비슷해보이기는 한다.
하지만 멀티코어는 한 칩에 직접되어 있기 때문에 캐쉬와 같은 자원을 공유할 수 있고,
코어들이 공통의 계산을 같이 처리하는 것도 가능하다.
멀티코어로도 부족하다? 그럼 컴퓨터에 여러개의 독립된 CPU를 가지고 조립할 수 있다.
유튜브 데이터 센터에서 비디오를 스트리밍하는 서버와 같이 고사양 컴퓨터들은 수백명의 사람들이 동시에 시청하더라도 비디오가 부드럽고 매끄럽게 유지되도록 특별한 능력이 필요하다.
요즘은 2개, 4개 프로세서 구성이 가장 일반적이지만, 이 정도로 충분하지 않을 때도 있다.
그래서 슈퍼컴퓨터 등장!
2017년 당시 세계에서 가장 빠른 컴퓨터는 중국 우시에 있는 National Supercomputing Center에 있었다.
(2022년에는 미 에너지부 오크리지국립연구소의 슈퍼컴 프런티어(Frontier))
출처:
https://www.hani.co.kr/arti/science/technology/1045606.html
Sunway Taihulight는 40960개의 CPU를 가지고 있고, 각 CPU는 256개 core를 포함한다.
즉, 총 천만개 이상의 코어가 있고 각 코어는 1.45GHz로 동작한다.
93 quadrillion FLOPS 부동소수점 연산을 할 수 있다. (quadrillion = 10의 15제곱)
(FLOP(floating-point operations per second) : 초당 처리 가능한 부동 소수점 연산 개수.)
