[Garbage collection] ⑤ 멀티스레드 환경에서의 스레드 동기화 (concurrent marking)
지난 시간에는 young 객체를 수거하는 minor GC를 멀티스레딩 환경에서 진행할 때 스레드 동기화 방법에 대해 다루어보았다. 이번 시간에는 멀티스레딩 환경에서 major GC를 할 때 스레드 동기화가 어떻게 이루어지는지에 대해 조사한 바에 대해 정리해보려 한다.
incremental marking에 대해 소개한 적이 있다.
스레드가 GC를 JS와 시간 텀을 두고 번갈아가면서 실행하는 것이다. 싱글 스레드 환경에서 점진 마킹은 화면 끊김을 개선해주는 효과가 있음을 포스팅했다. 그런데 incremental marking을 할 때 JS는 Garbage collector에게 '내가 중간중간 JS 실행하는 텀 동안 객체 그래프 이렇게 바뀌었으니 그렇게 알아~ 알아서 수거하던지 말던지~'하고 알려줘야 한다. 알려주기 위해 write barrier라는 코드를 사용한다. C++로 구현된 코드로, 내용은 아래와 같다.
// Called after `object.field = value`.
write_barrier(object, field_offset, value) {
if (color(object) == black && color(value) == white) {
set_color(value, grey);
marking_worklist.push(value);
}
}쓰기 연산 수행 후, 현재 객체(object)가 검정색으로 이미 마킹이 끝났는데 인접노드(value)가 흰색이라면, 회색으로 마킹하라는 뜻이다. 즉, 원래 있던 객체에 새로운 객체가 key로 추가된 경우로 볼 수 있다. 그리고 marking_worklist는 탐색 알고리즘의 stack의 개념으로 볼 수 있다.
그런데 이렇게 incremental marking을 하면 write barrier를 굳이굳이 써야 한다. (docs에서는 'incremental marking does not come for free'라는 표현을 쓴다.) 만약 멀티스레드 환경이라면 스레드 별로 나누어서 작업할 수 있으니 각 스레드가 써야 하는 write barrier 개수도 줄어든다는 이점이 있다. 하지만 문제되는 것은..! 이번에도 스레드 동기화이다.
위의 write barrier를 멀티스레드 환경에서 실행할 때 생각해볼 수 있는 race condition 시나리오는 아래와 같다.
스레드 A가 어떤 객체가 흰색임을 확인하고 (동적으로 새로 추가되었음을 확인하고) 회색으로 변경(마킹)하려고 하고 있다. 그런데 마킹하려던 찰나..! 스레드 B도 같은 객체에 접근해서 회색으로 변경하고 markinglist에 push까지 하고 pop까지 해서 검정색으로 변해버렸다면? 스레드A는 이미 검정색이 되어버린 객체를 회색으로 변경하는 일이 생겨버릴 수도 있다. 이는 쓸데없이 일을 중복으로 하기에 성능 저하 이슈도 있으며, 데이터 무결성 저하의 원인이 되는 시나리오이다.
따라서 멀티스레딩 환경에서는 atomic_color_transition을 사용한다.
atomic_color_transition
// Called after atomic_relaxed_write(&object.field, value);
write_barrier(object, field_offset, value) {
if (color(value) == white && atomic_color_transition(value, white, grey)) {
marking_worklist.push(value);
}
}지난 시간에 atomic 연산에 대해 잠깐 다루었다. atomic 연산은 CAS(compare and swap) 알고리즘을 기반으로 한다.
int compare and swap(int *value, int expected, int new value) { int temp = *value;
if (*value == expected) *value = new value;
return temp;
}CAS 알고리즘은 실제 value가 기대한 값과 동일할 때만 새로운 값으로 변경하게 하는 것이다. 만약 흰색 객체에 2개 이상의 스레드가 접근했는데, 이미 하나의 스레드가 회색으로 변경했다면? 나머지 스레드들은 기대했던 흰색과 실제 색깔이 다르니 물러나는 것이다. (흰색 객체 발견 + 회색으로 색상 변경)까지 atomic하게 처리할 수 있게 되는 것이다.
멀티스레딩 환경에서 marking worklist
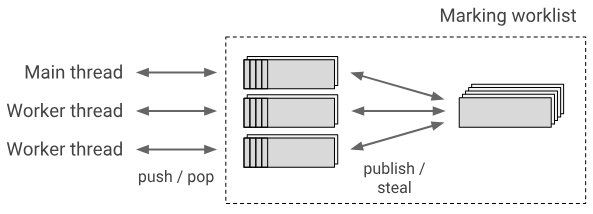
싱글 스레드 환경에서 marking worklist는 그냥 탐색에서 stack의 역할에 지나지 않는다. 하지만, 멀티스레딩 환경에서는 스레드간 협업의 중심지 같은 개념이다. 스레드들은 각자의 local segment를 가지고 있다. 마킹한 객체를 각각 local segment에 push하지만, local segment가 꽉찰 경우에는 global한 marking worklist에 push한다. 이를 publish한다고 표현한다. 이 때 바쁜 스레드는 자신의 local segment에 있는 객체를 pop해와서 검정색으로 마킹하기 바쁘겠지만, 좀 한가한 스레드는 marking worklist에서 pop해오는데 이를 work stealing한다고 표현한다.
각각의 스레드가 자신의 작업 영역을 확실하게 구분하여 가지고 있으니, race condition을 막을대로 막아볼 수 있지만, global한 영역에서 작업을 공유하여 효율성까지 챙긴 것이다.
참고:
v8 docs
Concurrent marking in V8
https://v8.dev/blog/concurrent-marking
OperatingSystem Concepts
