[Garbage collection] ④ 멀티스레드 환경에서의 스레드 동기화 (parallel scavenging)
지난 시간에는 idle time 최적화와 incremental marking에 대해 살펴보았다. 점차 멀티코어 프로세스가 보급되면서 GC도 싱글 스레드 환경이 아닌 멀티스레딩 환경을 적극적으로 이용하고 새롭게 최적화할 필요가 생겼다. 그리고 v8팀은 Orinoco라는 프로젝트를 시작했다. 마치 메인스레드 해방 운동 같다. 동시성을 활용하여 병렬 스레드들이 메인 스레드와 함께 작업하도록 하는 데에 집중하며 다양한 최적화를 진행했던 다년간에 걸친 연구였다.

무엇보다도 여러 스레드에서 GC를 실행하면서 해결해야할 중요한 과제가 생겼다. 바로 스레드 간의 동기화이다. 그래서 이번 포스팅에서는 특히 young 객체를 수거하는 scavenging이 멀티스레딩 환경으로 넘어오면서 어떤 방식으로 변경되었는지, 그리고 스레드 간의 경쟁 조건을 Orinoco project에서 어떻게 해결해왔는지에 대해 설명해보려고 한다.
parallel scavenging
생존 객체를 복사하고, 포인터를 업데이트하는 작업은 싱글스레드 환경에서와 마찬가지로 발생하지만, 메인스레드와 병렬 스레드에서 동시에 진행되는 것이다. 이것을 parallel scavenging이라고 한다.
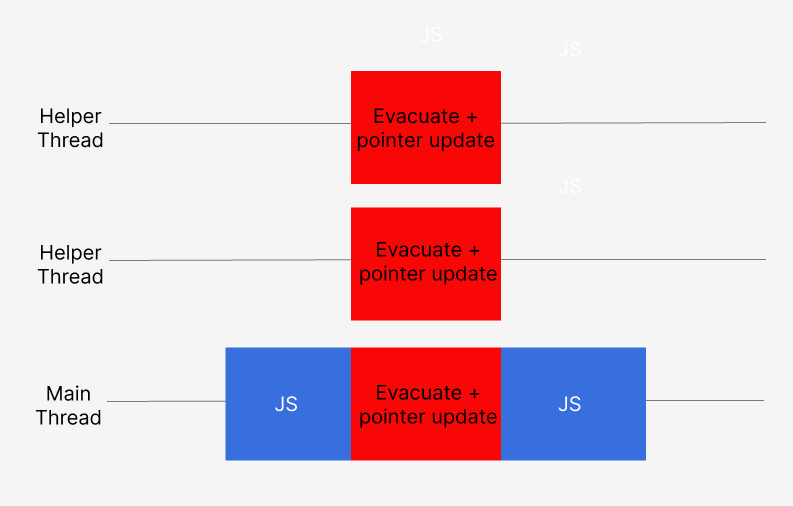
그런데 만약 스레드 하나가 어떤 객체 하나를 to-space로 대피시키고 나서 pointer update를 하려고 하는데, 다른 스레드가 update가 되지 않은 객체인줄 알고 pointer update을 시도할 수도 있다.
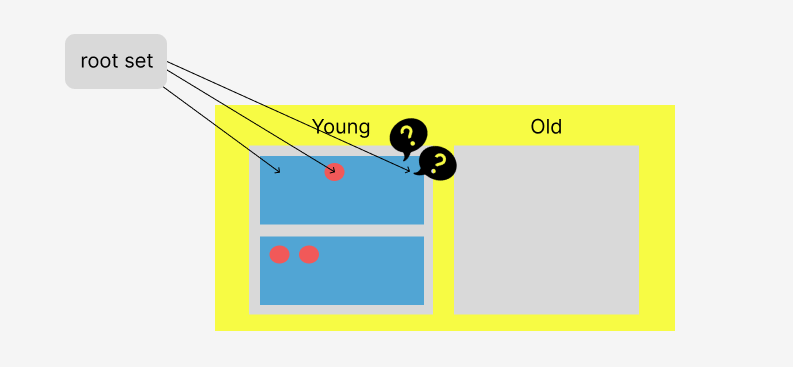
이렇게 여러 스레드가 동시에 하나의 포인터에 업데이트하겠다고 달려들면 중복으로 update되기 때문에 race condition이 발생한다. 스레드 간에 동기화가 필요한 것이다.
스레드 간의 동기화 방법
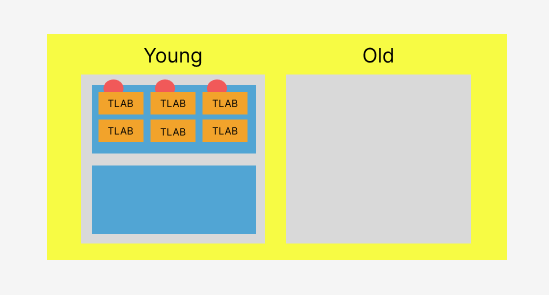
TLABs(Thread Local Allocation Buffers)
parallel scavenger에서는 이러한 race condition을 해결하기 위해 각 스레드가 GC를 하면서 독립적으로 객체를 할당할 수 있는 공간을 제공해준다. thread-LABS, 스레드 로컬 할당 버퍼라고 부른다. 메모리 할당의 효율성을 높이고, 스레드 간의 경쟁을 줄이는데 도움을 준다. 이렇게 각자의 스레드는 자신이 사용할 로컬 할당 버퍼와 객체를 수집해나갈 포인터들을 할당 받고 자신의 영역을 위주로 객체들을 대피시킨다.
atomic 연산
그리고 동기화를 하드웨어적으로 달성하는 방법 중에 atomic 연산이라는 개념이 있다.
프로세스나 스레드를 동기화하는 방법으로는 소프트웨어적인 방법과 하드웨어적인 방법이 있다. 그중에서도 atomic 연산은 하드웨어적인 방법이다. atomic 연산은 major GC에서 또 등장할 예정이기 때문에 중요한 개념이다.
atomic 연산
경쟁 조건을 해결할 수 있는 하드웨어적인 방법 중 하나이다. 하나의 스레드가 2개 이상의 연산을 하나의 원자적인 연산으로 처리하는 동안, 다른 스레드가 개입하지 못하도록 하는 것이다.
atomic 연산의 경우 CAS(compare & swap) 알고리즘을 기반으로 하는데, 이는 major GC에서 더 자세히 살펴보자.
위에서 본 예시를 다시 떠올려보자.
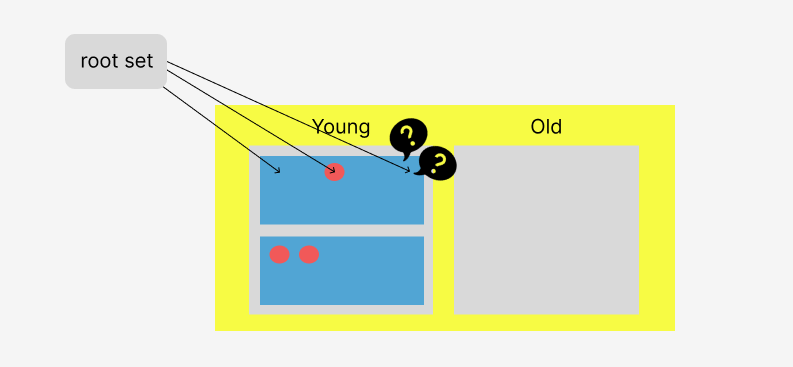
스레드 하나가 객체를 대피시켰는데 pointer를 update하려고 보니 다른 객체가 접근할 수 있는 이유는 바로,
(1) 대피시키는 명령과
(2) update하는 명령이
분리되어 있기 때문이다.
대피시키는 명령과 update하는 2가지의 명령을 atomic하게, 즉 분할 불가능하게 묶으면, (대피 + 업데이트)되는 동안 다른 스레드가 개입할 수 없게 된다. 한 번 대피시켰으면 업데이트까지 할 수 있기에 경쟁 조건을 해결할 수 있는 것이다.
이번 포스팅에서는 멀티 스레드 환경에서의 minor GC 최적화인 parallel scavenger를 살펴보았다. 다음 포스팅에서는 멀티 스레드 환경에서의 major GC 최적화인 concurrent marking에 대해 알아보자.
참고:
v8 docs
Jank Busters Part Two: Orinoco
https://v8.dev/blog/orinoco
Trash talk: the Orinoco garbage collector
https://v8.dev/blog/trash-talk
OperatingSystem Concepts
