Pytorch
Pytorych
What
Pytorch는 Opensource Machine Learning(ML) Framework로, Python 언어와 Torch Library를 기반으로 한다. Torch는 Opensource ML Library로, Deep learning을 이용하기 위해서 Lua Scripting으로 작성되었다. 현재, DL 연구를 위해서 가장 선호되는 플랫폼이다.
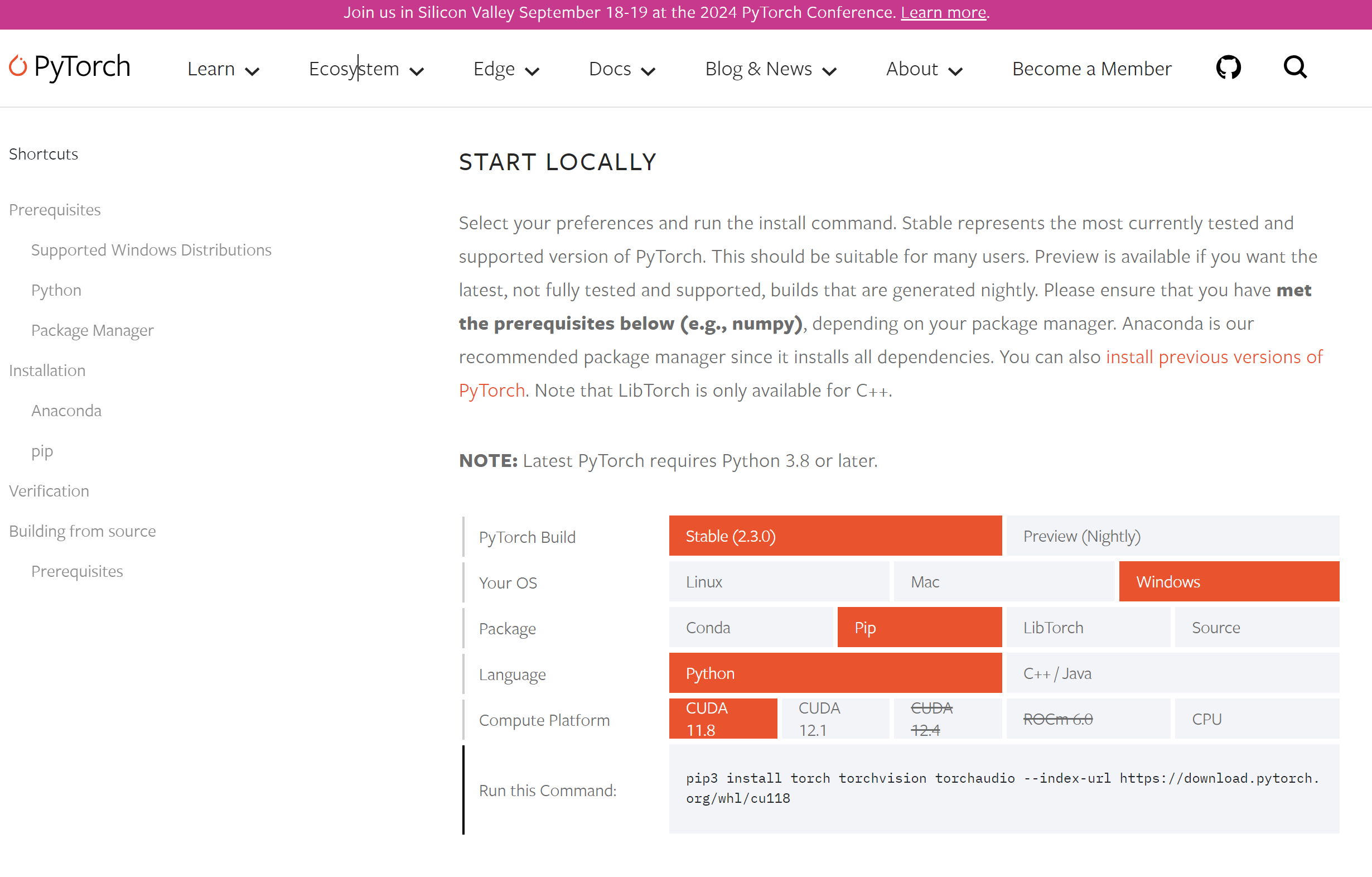
How to use?
Tools
Pytorch는 클라우드와 로컬, 두 가지 환경에서 활용할 수 있다.
-
In the cloud: Pytorch를 접근하기 가장 쉬운 방법으로, Microsoft를 통해서 접근하거나 Google Colab에서 실행해 볼 수 있다. 링크에만 접근한다면 Microsoft와 Colab에 작성된 Notebook에서 코드를 실행할 수 있다.
-
Locally: 로컬에서는 PyTorch and TorchVision 등을 우선 설치해야한다. 설치 가이드(installation instructions)를 따라서 설치할 수 있다. 다양한 버전이 홈페이지에 게재되어있다. Notebook을 활용하거나 IDE()에서 코드를 작성하여 실행하면 된다.
Pipieline
01 Prerequisites
Pytorch는 python 프로그래밍을 통해,딥러닝과 트랜스포머 개념을 구현해야한다.
02 Library installation
trl : Transformer language odel을 Reinforcement Leanring으로 학습하는데 사용한다.
peft : Prameter-effiecient Fine-tuning(PEFT)방법을 통해서 효율적으로 pre-treined model을 조정한다.
torrch : Opensource ML library
datasets : ML datasets을 로딩(loading) 또는 다운로딩(downloading)하기 위해 하용한다.
Trasformers : Hugging Face가 개발한 라이브러리로, 분류/요약/번역 등과 같은 다양한 텍스트를 위한 task를 수행하기 위해 수천 개의 PLM(pre-trained model)모델을 제공한다.
02-1 pip 를 통해서 pythong package 다운로드한다.
%%bash
pip -q install trl
pip -q install peft
pip -q install torch
pip -q install datasets
pip -q install transformers02-1 import 통해서 pythong package를 가져온다
import torch
from trl import SFTTrainer
from datasets import load_dataset
from peft import LoraConfig, get_peft_model, prepare_model_for_int8_training
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments03 Data Loading and Preparation
03-01 Data loading
허깅페이스의 공개 데이터셋을 로드한다.
load_dataset : 데이터 로드
dataset_name : 로드하기 위한 데이터셋 이름
split parameter를 "train"로 설정하여 학습(traing)데이터로만 설정된 데이터 로드
dataset_name="tatsu-lab/alpaca"
train_dataset = load_dataset(dataset_name, split="train")
print(train_dataset)03-02 Converting the dictionary into a pandas dataframe
로드한 데이터는 dictionary 타입으로, pandas의 dataframe으로 변환한다.
.to_pandas() : train_dataset을 pandas dataframe으로 변환
pandas_format = train_dataset.to_pandas()
display(pandas_format.head())04 Model Training
-
Pre-trained Model : Pretrained 모델
-
Tokenizer : 데이터의 토큰화(tokenization)를 위해 사용하며, PLM과 tokenizer를 가져옴
-
AutoModelForCausalLM:from_pretrained메서드로 PLM을 가져오기 위해 사용pretrained_model_name은 PLM 모델을 지정하며,data type은 모델의 tensor를torch.bfloat16로 설정
*AutoTokenizer:
from_pretrained: 가 PLM에 맞는 tokenizer를 가져오기 위해 사용하는 메서드pretrained_model_name과trust_remote_code를 true로 설정
pretrained_model_name = "Salesforce/xgen-7b-8k-base"
model = AutoModelForCausalLM.from_pretrained(pretrained_model_name, torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name, trust_remote_code=True)05 Training configuration
Training을 위해 training arguments(인수)와 training configurations(구성)이 필요하다. 이는 TrainingArguments로 구성하며, LoraConfig model과 SFTTrainer model의 인스턴스이다.
06 TrainingArguments
output_dir 학습 모델 저장 위치
per_device_train_batch_size 한 학습에 사용하기 위한 학습 샘플의 사이즈
optim 옵티마이저
logging_steps 로깅을 위한 빈도로, n번의 스텝마다 기록
learning_rate 옵티마이저의 learning rate 설정
warmup_ratio
lr_scheduler_type
num_train_epochs
save_strategy
model_training_args = TrainingArguments(
output_dir="xgen-7b-8k-base-fine-tuned",
per_device_train_batch_size=4,
optim="adamw_torch",
logging_steps=80,
learning_rate=2e-4,
warmup_ratio=0.1,
lr_scheduler_type="linear",
num_train_epochs=1,
save_strategy="epoch"
)07 LoRAConfig
LoRa(Low-Rank Adaptation)은 Hugging Face가 개발한 PEFT이다. peft 라이브러를 통해서 사용할 수 있다.
현재의 파이프라인에서는 하위 변환 행렬을 16으로 설정한다. LoRa의 매개변수의 스케일링 계수는 32로 서렁한다. 드롭아웃 비율은 0.05로 설정되었다.
CASULA_LM은 인과적 언어 모델(causual lanauge model)의 속성을 초기화한다.
08 SFTTrainer
training data, tokenizer, 모델의 추가 정보를 이용하여 학습한다.
아래는 로드한 텍스트 칼럼의 길이를 컬럼을 추가하여 저장하는 것이다. 이 데이터셋은 0~1000 크기의 텍스트 분포가 크다. (분포를 보여주는 표는 생략)
1024보다 큰 값의 비율을 구한다.
pandas_foramt은 특정 칼럼의 크기가 1024보다 큰것을 찾아 mask로 저장
percentage에 mask가 'texst_length'컬럼에서 차지하는 비율을 구함
pandas_format['text_length'] = pandas_format['text'].apply(len)
mask = pandas_format['text_length'] > 1024
percentage = (mask.sum() / pandas_format['text_length'].count()) * 100
print(f"The percentage of text documents with a length greater than 1024 is: {percentage}%")- 아래 코드는
SFTTrainer의 인스턴스를 만들고 있다.
model=modelPLM을 SFTTrainer에 전달
train_dataset=train_datasettrain dataset을 SFTTrainer에 전달
dataset_text_field="text"텍스트 데이터를 포함하는 dataset 필드 지정
max_seq_length=1024모델 력의 최대 시퀀스 길이를 설정
tokenizer=tokenizertokenizer를 SFTTrainer에 전달
args=model_training_args모델 트레이닝을 위한 인수를 SFTTrainer에 전달
packing=True효율적인 훈련을 위한 시퀀스 패킹 설정
peft_config=lora_peft_configPEFT에 loraConfig 설정
SFT_trainer = SFTTrainer(
model=model,
train_dataset=train_dataset,
dataset_text_field="text",
max_seq_length=1024,
tokenizer=tokenizer,
args=model_training_args,
packing=True,
peft_config=lora_peft_config,
)09 Training execution
tokenizer.pad_token =tokenizer.eos_token padding token을 eos_token으로 설정(eos, end of sequence)
model.resize_token_embeddings(len(tokenizer)) 모델의 토큰 임베딩 계층을 tokenizer 길이로 설정
model=prepare_model_for_int8_training(model)) 양자화처럼, INT8 정밀도로 트레이닝할 수 있도록 준비
model = get_peft_model (model, lora_peft_config) 주어진 모델을 PEFT 구성에 따따 조정
training_args = model_training_args training_args에 미리 정의된 training 인수를 할당
trainer =SFT_Trainer SFTTrainer 인스턴스를 trainer에 저장
trainer.train() (위의) 설정에 따라 모델을 학습
tokenizer.pad_token = tokenizer.eos_token
model.resize_token_embeddings(len(tokenizer))
model = prepare_model_for_int8_training(model)
model = get_peft_model(model, lora_peft_config)
training_args = model_training_args
trainer = SFT_trainer
trainer.train()Reference
[1] https://pytorch.org/tutorials/beginner/basics/intro.html
[2] https://www.datacamp.com/tutorial/how-to-train-a-llm-with-pytorch
[3] https://github.com/keitazoumana/Medium-Articles-Notebooks/blob/main/Train_your_LLM.ipynb
