Inference Serving Architecture
요구사항
- Client Request 비동기 처리
- 추론 성능 개선 (속도)
- 모델 배포 / 자원 할당 자동화 (자원 관리 / 에러 처리(GPU 메모리 full에 대한 처리 등))
- 추론 결과 저장 및 신뢰성 확보
참고 자료
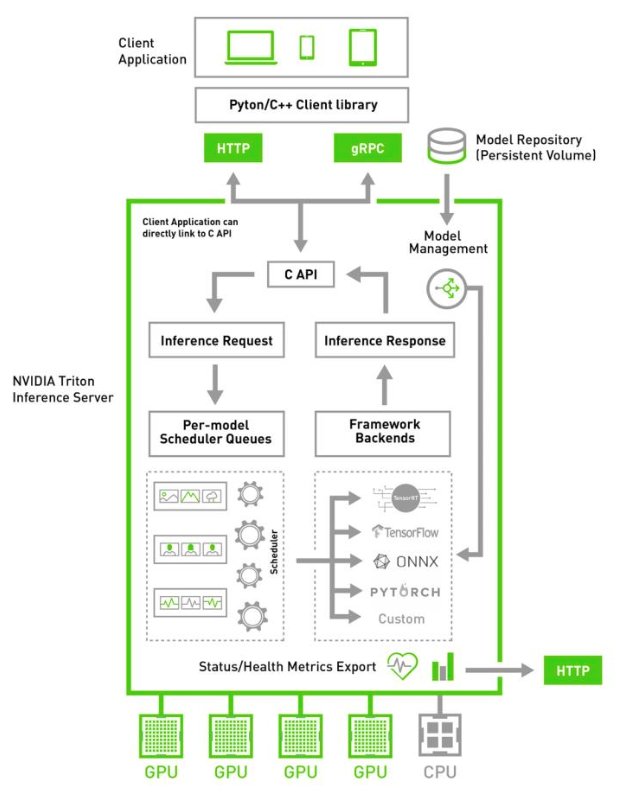
1) NVIDIA Triton Inference Server
Triton Server 소개자료
-
NVIDIA TensorRT Inference Server => Triton Server로 이름 변경
-
오픈 소스
-
TensorFlow, TensorRT, PyTorch, ONNX 또는 커스텀 프레임워크 기반 모델 서비스 가능
-
request serialization <-> server side de-serialization (질문 : 현재는?)
-
CLIENT SDK
- TRT Inference Server를 위한 C++ / Python Client Libraries: HTTP / gRPC
- Client sample code 제공: image_client, perf_client
- 브랜치 버전은 TRT Inference Server와 동일
-
per-model scheduler :
- 들어온 request를 적절한 모델로 routing 해줌
- 배치 : 모델 by 모델 배치 처리 지원
-
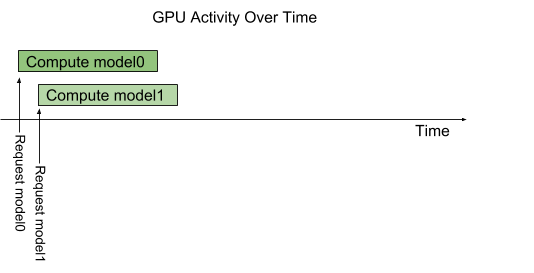
최초 요청 -> GPU scheduler가 GPU 자원 할당
-
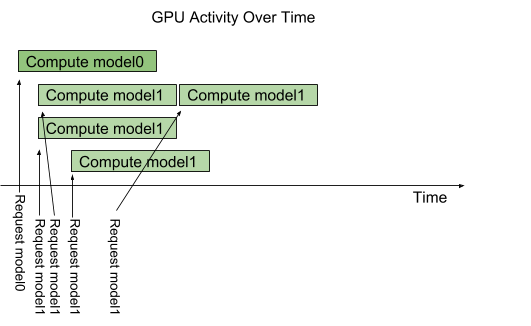
instance-group 지원 : 1 모델에 대한 병렬 실행 정도를 결정할 수 있음
- default : 1 모델 - 1 execution instance
- 허용한 객체 수 만큼 GPU 할당 -> 해당 만큼 병렬 실행 / 그 이후의 요청은 대기 후 처리

-
CUDA streams :
- Triton Server가 GPU 할당 및 사용에 이용됨
- CUDA streams allow Triton to communicate independent sequences of memory-copy and kernel executions to the GPU. The hardware scheduler in the GPU takes advantage of the independent execution streams to fill the GPU with independent memory-copy and kernel executions. For example, using streams allows the GPU to execute a memory-copy for one model, a kernel for another model, and a different kernel for yet another model at the same time.
- 추가 조사 필요 (모델별 자원 할당에 필요할 수 있음)
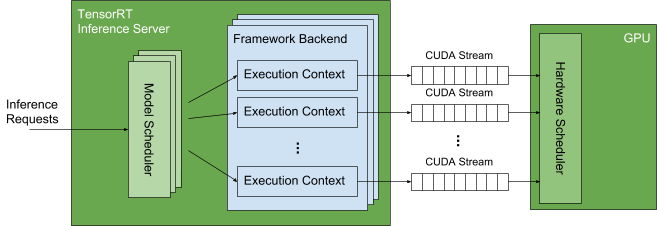
- 서버에서 각 프레임워크 (tensorflow, pytorch, etc.)가 생성한 execution context가 CUDA Stream을 통해 GPU를 사용함
- request -> Model Scheduler (== ingress controller)에 큐잉됨 -> 해당 요청에 맞는 모델과 연관된 Execution Context에 전달 -> 이와 연관된 CUDA stream으로 모델 실행에 필요한 memory-copy와 kernel execution 전달 (CUDA stream은 독립적)-> GPU 하드웨어 스케줄러가 이를 받아서 수행
-
Model Repository 내의 모델은 반드시 Model Config를 명시해야 하나, Triton server가 이를 자동 생성해주기도 함 / --strict-model-config=false option
(이름, 플랫폼 (Tensorflow, PyTorch..), 배치사이즈, input, output 필수 명시)
--> 회의 때의 '모델 배포 시 엔진 등에 대한 사용자 정의 및 내부 Config 정의'하는 개념과 동일
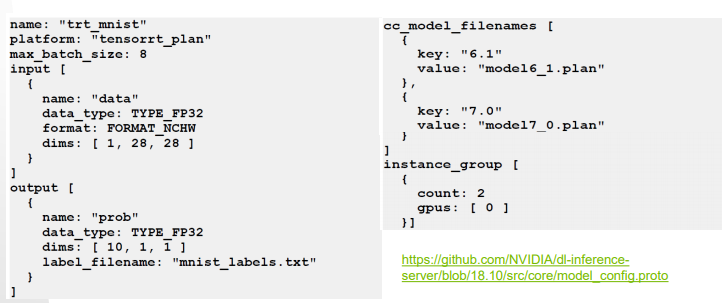

:-)