
Prologue
💡 저번 강의 후기에 이어서 이어지는 글입니다. 후기를 어떻게 작성할까 고민하다가 강의내용을 정리하는 식으로 하게되었네요.. 저번에는 기초적인 수학이라면 이번에는 소개하고 싶은 AI 관련한 강의내용 위주로 작성하였습니다. 😀
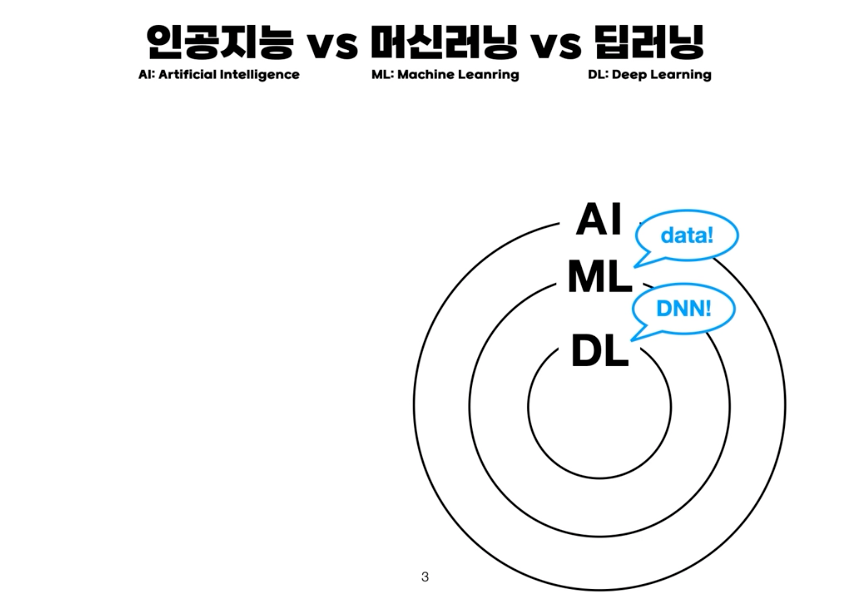
인공지능 vs 머신러닝 vs 딥러닝
많은 사람들이 가장 처음 인공지능을 공부하면서 알게 되는 것이 AI,ML,DL(딥러닝)의 차이입니다. 예전에 저도 이차이를 잘 몰랐는데 간단하게 정리해봅니다.
- AI : 인간의 지능을 인공적으로 만든 것 (인간의 사고방식 모방)
- ML : 데이터를 기반으로 학습
- DL : DNN(Deep Neural Network) 기반으로 학습
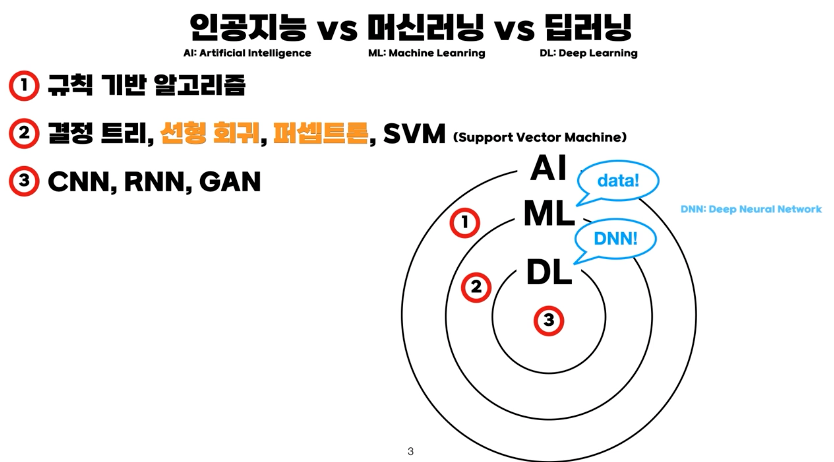
사진에 나와있는 선형회귀, 퍼셉트론, svm 등의 경우 데이터를 사용하지만, DNN을 사용하지는 않기에 ML이라 하는 것!
일반적으로 데이터가 많을수록 ML의 정확도가 높다. 데이터에 기반하지 않고 Rule-based로 진행하는 경우 1번 위치라 생각하면 되겠습니다.
ML의 분류
머신러닝은 크게 지도학습, 비지도 학습, 자기지도 학습, 강화학습이 있는데, 이들을 정리해보고자 합니다. (머신러닝이라 한 이유는 DNN을 쓰지 않는 학습이 있기 때문)
지도학습 supervised learing

- 💡 지도 학습은 정답 label을 알고 있을때 할 수 있는 학습입니다. 보통 사진으로 객체를 분류하는 문제에서, 고양이와 강아지로 분류하는 것을 예로 들 수 있겠습니다. 이때 각각 데이터(사진)에는 고양이면 고양이, 강아지면 강아지로 정답이 'labeling' 되어 있어야 합니다. segmentation의 경우 사진에서 객체단위로 픽셀을 분류하는 것입니다. instance seg의 경우 2개의 고양이를 각각 분류할 수 있습니다.(신기)
- 그 외에도 다양한 task에 응용가능
비지도 학습 unsupervised learning
- 정답을 모르는 경우 (데이터의 labeling이 안되거나 안할거거나)
- 군집화 (k-means, DBSCAN, ... )
- 차원 축소 (데이터 전처리: PCA(Principal component analysis), SVD(singular value decomposition)
- GAN (살짞 애매)
많은경우 실제 task에서 labeling이 되지 않은 경우가 많다. 그런 상황에서 사용하는 방법으로 데이터를 특정 기준으로 군집화(예를들어 좌표상에서 서로 가까운 k개의 군집으로 묶기등) 또는 데이터처리(중요변수로, 한축으로 분리)로 학습을 진행합니다.
자기지도 학습 self-supervised learning
정답을 아는 데이터가 가장 좋지만, 부족한 경우가 많습니다. 정답을 아는 데이터가 적을때 사용하기 좋다. 사전에 적은 데이터로 진짜 task와 유사한 가짜 task에 대해서 학습 후(이때 context정보를 학습) 진짜 task에 대해서 전이 학습 및 fine tuning을 진행하는 것입니다.
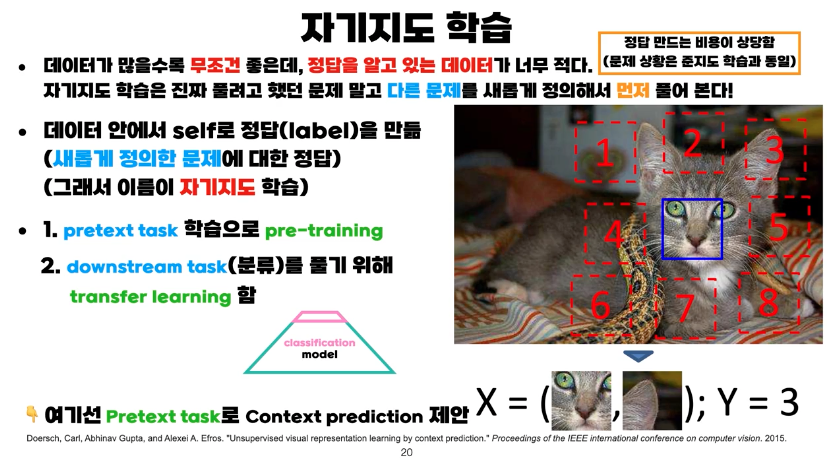
- 강의 자료 중 출처인 "Unsupervised visual representation learning by context prediection" 논문을 한번 읽어보는 것도 좋아 보입니다
강화 학습 reinforcement learning
- Agent, Reward, Environment, Action, State, Q-function, Episode 용어 참고
- Agent가 reward를 얻기 위해 environment 와 state를 보고 action을 정한다. episode가 지나면서 더좋은 (최적화) q-function을 학습하게 된다.
- 간단하게 말을 당근과 채찍으로 원하는 바를 학습시키는 것과 유사한것 같다.
📌 Training Test Validation
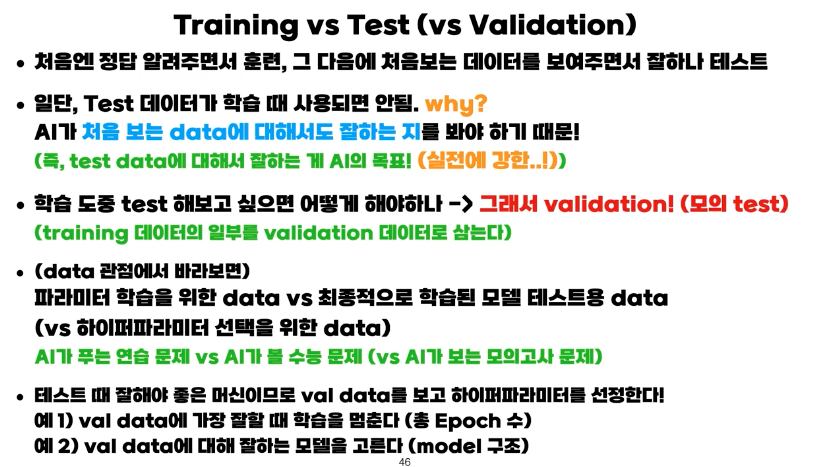
인공지능 신경망을 학습할때 수집한 데이터를 크게 3가지로 분류합니다. train, validation, test dataset. 각자 중요한 의미가 있기에 정리해봅니다.
- Train : Train data를 사용하여 신경망을 학습시킵니다.
- Validation : Validation data는 train에 없던 data로 이 신경망이 얼마나 data를 잘 generalization하는지 확인합니다.(혹 overfitting은 일어나지 않는지) 학습완료후, epoch별 가장 좋은 모델을 뽑는데도 사용될 수 있습니다.
- Test : test data로는 이 모델의 성능을 파악하는 것입니다. 중요한 것은 test역시 train에 포함되지 않아야 합니다.
인공지능 신경망의 성능은 결국 unseen data set에 대해서 얼마나 잘 generalization할 수 있냐를 보는 것이기에 이렇게 학습이 진행됩니다.
참고
본 게시글은 패스트캠퍼스 [ 혁펜하임의 AI DEEP DIVE] 체험단 활동을 위해 작성되었습니다.
강의 링크 : https://bit.ly/3GV73FN
#패스트캠퍼스혁펜하임 #혁펜하임 #혁펜하임AI #AIDEEPDIVE #패스트캠퍼스 #AI강의 #혁펜하임강의 #혁펜하임강의후기
