
Prologue
계속해서 이어서 작성하는 강의 후기~ 😀
강의 내용 정리
DNN의 문제점 ~ 및 해결방안
다양한 문제가 있지만 크게 vanishing gradient, overfitting, loss landscape가 매끄럽지 못한문제가 있다.
- +@ 그외에도 자잘한 문제들이 있다.

Vanishing gradient 문제
- sigmoid 활성화 함수의 경우, 함수 양끝단으로 갈수록 기울기가 0으로 수렴하여, 학습시 체인룰에 의해서 곱해지는 갑이 0 가까워져 결국 weight 학습이 이루어지지 않는 문제 입니다.(특히 입력층에 가까운 경우)
- 결국 학습이 제대로 이루어지지않아 underfitting이 일어난다고 합니다.
해결방법 1. ReLU(Rectified Linear Unit)
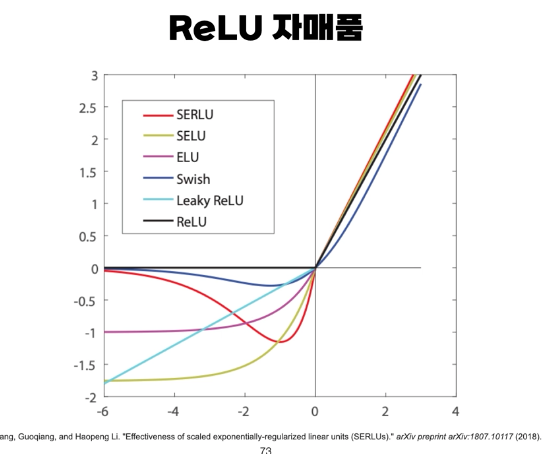
활성화함수를 ReLU(또는 ReLU 유사함수)를 사용하면 됩니다. ReLU를 사용하면 비선형성을 유지하면서, vanishing graident 문제를 해결할 수 있습니다. (다른 논문에 따르면 실제 계산 속도 또한 더 빨라진다고 합니다.)
해결방법 2. Batch Normalization
(epoch는 반복횟수, batch는 한꺼번에 계산되는 단위이다.)
어떤 한 input node에 대해서 한 배치의 값들이 ReLU를 지나간다고 생각해보자, 값들이 모두 0이상이면, 비선형성이 떨어지고, 모두 0이하면, vanishing graident 문제를 해결하지 못한다.
-> 그러므로 이 값들을 normalization 시켬으로써 기능을 향상킨다.
-> 평균이 몇, 분산이 몇으로 할지 애매하기에 학습 파라미터로 추가하여 학습시킴
💡 (미분가능하면 역전파로 학습이 가능하다!)
(최근 batch normalization에 대해서 관점이 조금다른 논문이 발표됬다는것들은 기억이 있다. 그 논문도 참고하면 좋을것 같다.)
Loss landscape이 매끄럽지 않은 문제
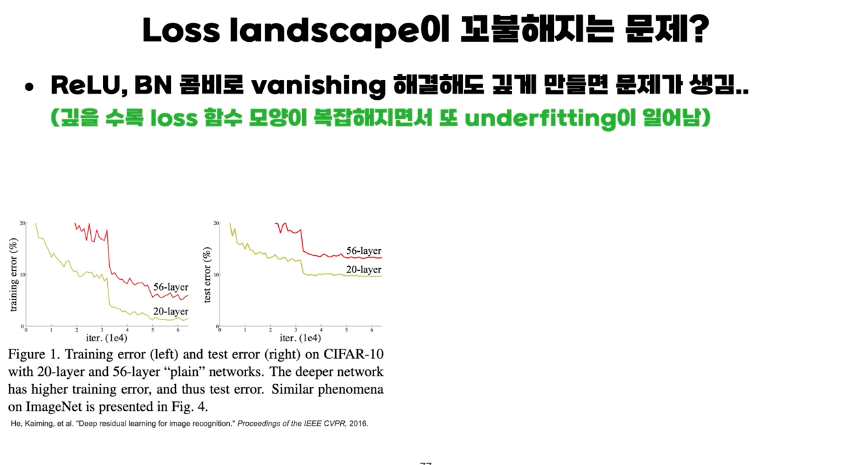
- 실제 ReLU, Batch normalization 으로 vanishing graident 문제를 해결하고 깊게 만들면 기대했던것과 달리 학습이 잘 이루어지지 않음.
- Resnet 논문에서 따르면, layer 깊게 쌓는다고 항상 성능이 좋아지는 것이 아님.
- resnet은 문제를 해결하기 위해 skip-connection을 제시함.- skip connection : 이전의 입력값을 받아서 전달함.
Overfitting 과 해결방법
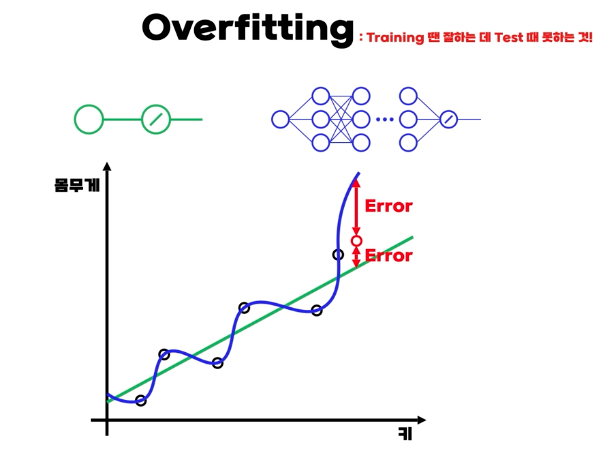
- 핵심은 인공신경망 모델이 trian에서 과정에서 잘하지만 test에서 잘하지 못하는 경우이다.
- 디테일 하게는 학습 데이터를 과도하게 학습한 경우로, unseen data에 대해서 generalization을 잘 하지 못하는 것이다.
해결 방법
-
모델 경량화
- 모델의 layer 수, 파라미터 수, 등을 줄입으로써 모델을 단순하게 만든다.
- 보통 모델이 학습데이터에 비해서 크고 복잡할수록 overfitting이 발생한다.
-
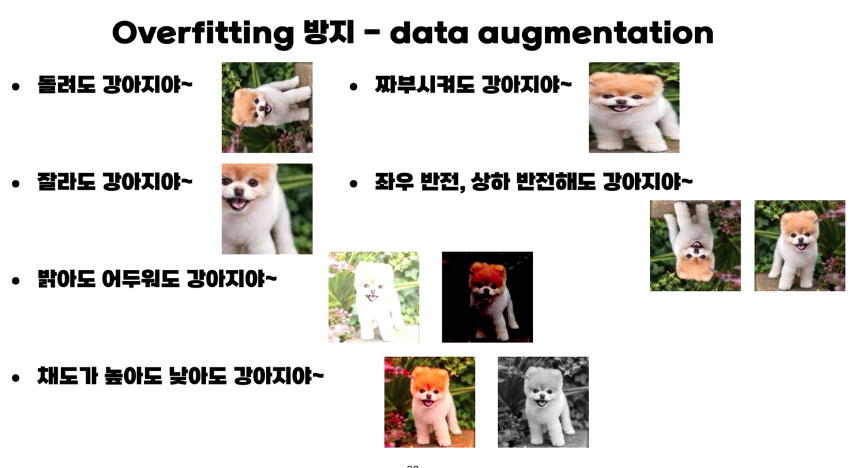
Data augmentation
- 학습 데이터를 변형시키는 방법이다. 예를 들어 강아지를 학습시키는 경우에, 좌우상하반전이 되어있어도 사진은 강아지 사진이므로, 이를 이용하여 학습데이터를 증강 시킬 수 있다.
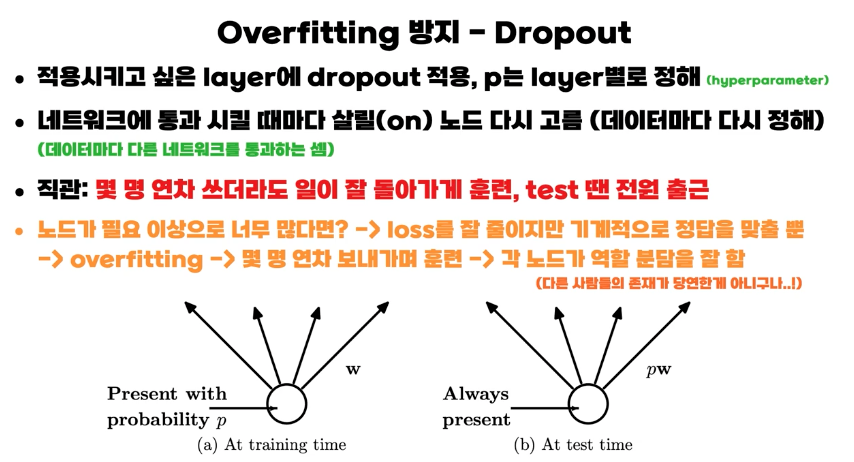
- Dropout
- Dropout은 학습시 신경망에서 특정 노드들을 확률p 만큼 꺼졌다고 하고 진행하는 것이다. 실제 해당 노드의 결과값은 0으로 처리되며 학습이 이루어 지지않는다. 하지만 이로 인해서 남아있는 노드들이 잘 학습하게되 overfitting을 방지할 수 있다.
- 테스트시 에는 당연히 모든 노드에서 계산된다.
- 유사하게 노드가 아니라 노드간의 connection의 결과를 0으로하는 drop connect가 있다.
- Regularization
- 기존의 loss 함수에 weight 값들 고려한다는 개념. (weight의 L1,L2 norm)
- 특정 weight 값들이 너무 커지지 않도록 한다. weight가 편향되지 않게 함.
- 수학적으로 MAP(Maximum A Posteriori)로 해석, weight norm 을 prior distribution에서 생긴값으로 가정

전체적인 강의 후기.
전체적인 후기로는 어려운 개념을 예시를 통해 잘 설명해 주셔서 이해가 잘되었다. 하지만 말그대로 기초 강의라 아쉬운 부분이 조금 있었는데, 논문이나 어려운 개념에대해서 한발걸음 더 나아가도 괜찮지 않을까 싶었다.
인공지능에 대해서 처음 배울때 방향성이 중요하다고 생각하는데, 그러한 개념을 잘 알려주는 강의라고 생각합니다.
😃
추가적으로 제 블로그에는 올리지 않았지만 실습코드(제공해줌)을 통해서 개념을 설명해주기에 좋았던것같습니다.
참고
본 게시글은 패스트캠퍼스 [ 혁펜하임의 AI DEEP DIVE] 체험단 활동을 위해 작성되었습니다.
강의 링크 : https://bit.ly/3GV73FN
#패스트캠퍼스혁펜하임 #혁펜하임 #혁펜하임AI #AIDEEPDIVE #패스트캠퍼스 #AI강의 #혁펜하임강의 #혁펜하임강의후기
