DeepSeek-V3
DeepSeek-V3는 총 671억 개의 매개변수를 가진 Mix-of-Experts(MoE) 기반의 대규모 Transformer 언어 모델입니다.
이 모델은 DeepSeek-R1의 지식을 전수받아 질문 응답, 코드 생성, 수학 문제 해결 등 다양한 작업에 최적화될 수 있도록 설계되었습니다.
아키텍처 개요 (Transformer with MHLA & MoE)
DeepSeek-V3는 기존 Transformer 구조를 기반으로 하지만, 보다 효율적인 추론 및 학습을 위해 새로운 기법을 도입했습니다.
- MHLA(Multi-Head Latent Attention): 기존 Self-Attention보다 계산량을 줄이고 강력한 문맥 이해를 가능하게 함
- DeepSeekMoE(Mixture of Experts): MoE를 개선하여 전문가의 부하 균형을 최적화하고 학습 효율성 증가
- 부하 균형 전략 (Load Balancing without Auxiliary Loss): 부하 불균형 문제를 해결하는 혁신적인 기법 적용
이러한 개선 덕분에 DeepSeek-V3는 더 빠른 연산 속도와 높은 학습 효율성을 갖추게 되었습니다.
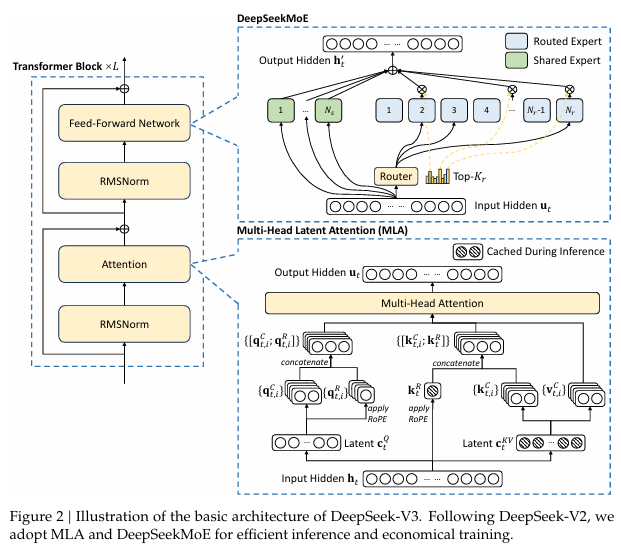
기존 Attention과 차이점 (MHLA 적용)
기존 Transformer는 Multi-Head Self-Attention(MHSA) 방식으로 토큰 간 관계를 직접 계산합니다. 하지만 이 방식은 계산량이 O(N²)으로 커지는 단점이 있습니다.
MHLA(Multi-Head Latent Attention) 는 이를 개선하여 잠재 공간(latent space)에서 추가적인 추론을 수행하는 방식으로 최적화되었습니다.
- O(N²) -> O(N log N) 수준으로 연산량 감소 -> 대용량 데이터에서도 안정적 학습 가능 -> 강력한 문맥 이해 및 추론 능력 확보
결과적으로, DeepSeek-V3는 기존 MHSA보다 빠르면서도 더 정교한 추론이 가능한 모델입니다.
기존 FFN과의 차이점: DeepSeekMoE(Mixture of Experts)
1) 기존 MoE 모델과의 차이점: DeepSeekMoE(Mixture of Experts)
FFN 블럭은 종래 MoE(Mixture of Experts)에서 개량된 DeepSeekMoE(Mixture of Experts) 아키텍처를 기반으로 작동합니다.
기존 MoE보다 더 정밀한 전문가(Finer-grained Experts) 를 사용하며, 일부 전문가를 공유(Shared Experts) 로 설정하여 일관된 성능을 유지합니다.
입력에 따른 전문가 선택 gating은 토큰과 전문가 간 연관도를 시그모이드 함수로 계산하고, 정규화를 적용하여 최적의 전문가를 선택합니다. 이러한 개선 덕분에 추론 및 학습 효율성이 증가하고, MoE 아키텍처의 단점(불균형 로드, 성능 저하)을 완화합니다.
MoE(Mixture of Experts)란
MoE는 필요한 전문가(Expert)만 선택해서 계산하는 방식입니다. 즉, 모든 계산을 한 번에 하지 않고, 가장 적절한 전문가들만 골라서 사용합니다.
기존 MoE는 전문가 간 부하 불균형 문제(일부 전문가가 너무 많이 사용됨)가 있었습니다.
DeepSeek-V3의 MoE 개선점
- 더 정교한 전문가(Finer-Grained Experts) 사용
- 일부 전문가를 공유(Shared Experts)해서 성능 유지
- 부하를 자동으로 조절하는 로드 밸런싱 기법 도입
- 토큰을 절대 버리지 않음 (No Token Dropping)
- 이런 개선 덕분에 학습 속도가 빠르면서도 성능이 뛰어난 모델
2) Auxiliary-Loss-Free Load Balancing (보조 손실 없는 부하 균형 조정)
- 기존 MoE 모델은 전문가 간 부하 불균형을 해결하기 위해 보조 손실(Auxiliary Loss)을 사용했지만, DeepSeek-V3는 보조 손실 없이도 부하를 동적으로 균형 맞추는 기법을 도입했습니다.
- 각 전문가에 편향 값을 추가하여 토큰-전문가 매칭을 조정하고, 과부하된 전문가의 편향을 줄이며 저부하 전문가의 편향을 증가시켜 자동으로 부하를 균형 있게 조정합니다.
3) Sequence-Wise Auxiliary Loss(시퀀스 단위 부하 균형)
- 부하 균형을 더욱 정교하게 유지하기 위해, 각 시퀀스 내에서 전문가 간의 부하가 특정 전문가에 집중되지 않도록 보완적인 부하 균형 손실을 적용했습니다.
- 기존 Auxiliary Loss처럼 성능을 저하시키지 않으면서도, 필요한 범위 내에서 최소한의 손실만 추가하여 균형을 조절합니다.
4) 노드 제한 라우팅 (Node-Limited Routing)
- 토큰이 특정 전문가에게 과도하게 몰리는 것을 방지하고, 통신 비용을 줄이기 위해 토큰을 제한된 개수의 노드에만 할당하는 기법을 도입했습니다.
- 이를 통해 연산-통신 병목을 최소화하여 모델 학습 속도를 최적화할 수 있습니다.
5) 토큰 드롭 방지 (No Token-Dropping)
- 기존 MoE 모델에서는 부하 불균형 문제로 인해 일부 토큰이 학습 과정에서 제거되었지만, DeepSeek-V3는 모든 토큰을 유지하여 정보 손실 없이 안정적인 학습이 가능하도록 설계되었습니다.
- 추론(Inference) 과정에서도 토큰 드롭 없이 균형을 유지하는 배포 전략을 적용하여 성능 저하를 방지합니다.
요약
1) DeepSeekMoE: FFN을 대체하는 새로운 MoE 구조
MoE(Mixture of Experts)는 FFN(Feed Forward Network)을 여러 개의 전문가(Experts)로 대체하는 방식입니다. 하지만 기존 MoE에는 부하 불균형 문제 및 성능 저하라는 단점이 있었습니다.
DeepSeekMoE 개선 사항
1-1) Finer-Grained Experts → 더 정밀한 전문가 사용으로 모델 성능 향상
1-2) Shared Experts 도입 → 일부 전문가를 공유하여 일관된 성능 유지
1-3) Sigmoid 기반 Gating → 토큰과 전문가의 연관도를 정규화하여 최적의 전문가 선택
이러한 개선을 통해 MoE의 단점을 보완하면서도 학습 및 추론 효율성을 높였습니다.
2) 부하 균형 (Load Balancing without Auxiliary Loss)
기존 MoE 모델에서는 전문가 간 부하 불균형을 해결하기 위해 Auxiliary Loss를 사용했습니다. 하지만 DeepSeek-V3는 보조 손실 없이도 부하를 자동으로 균형 조정하는 기법을 도입했습니다.
- Bias 값 추가 → 토큰-전문가 매칭을 조정하여 균형 유지
- Sequence-Wise Auxiliary Loss → 시퀀스 내에서 전문가 부하를 분산
- Node-Limited Routing → 특정 전문가에 토큰이 몰리는 현상을 방지
- No Token-Dropping → 정보 손실 없이 모든 토큰을 유지하며 안정적인 학습 가능
이러한 전략 덕분에 부하 균형을 유지하면서도 성능 저하 없이 MoE를 효과적으로 활용할 수 있습니다.
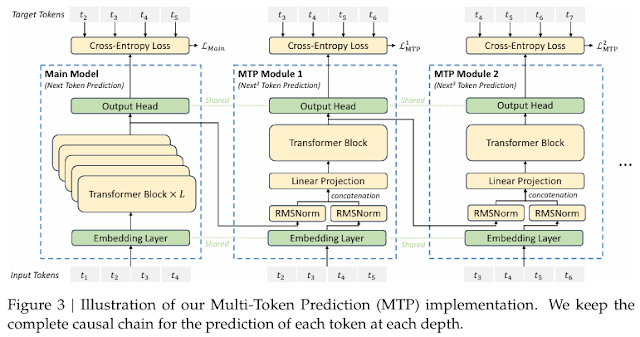
다중 토큰 예측 (Multi-Token Prediction, MTP)
DeepSeek-V3는 기존의 단일 토큰 예측 방식을 확장하여 여러 개의 토큰을 동시에 예측하는 Multi-Token Prediction(MTP) 기법을 도입했습니다.
- 학습 신호 밀도 증가 -> 데이터 효율성 극대화
- Transformer 블록 공유 -> 추가적인 학습 비용 없이 성능 향상
- Causal Chain 유지 -> 논리적인 문맥 이해 강화
MTP는 교차 엔트로피 손실(Cross-Entropy Loss)과 결합하여 최적화되며, 추론 과정에서는 Speculative Decoding을 활용해 생성 속도를 최적화할 수 있습니다.
결과적으로, 더 빠르고 정교한 예측이 가능해졌습니다.
다중 토큰 예측 (Multi-Token Prediction, MTP)란
일반적인 AI 모델은 한 번에 하나의 단어(토큰)만 예측합니다. 반면 DeepSeek-V3는 한 번에 여러 개의 단어를 동시에 예측하는 Multi-Token Prediction (MTP) 기술을 사용합니다.
MTP의 장점
- 한 번에 여러 단어를 예측하니 학습 속도가 빠름
- 문맥을 더 잘 이해해서 더 자연스러운 문장을 생성할 수 있음
- Speculative Decoding 기법을 사용해 추론 속도도 최적화
결론
DeepSeek-V3는 기존 Transformer 기반 모델의 한계를 극복하기 위해 MHLA, DeepSeekMoE, 부하 균형 전략, MTP 기법 등을 적용하여 더 강력하고 효율적인 AI 모델로 발전하였습니다.
- 기존 Attention보다 효율적인 MHLA 적용
- MoE의 단점을 개선한 DeepSeekMoE 구조
- 부하 균형 최적화를 통한 안정적인 전문가 선택
- MTP 기법을 활용한 빠르고 정교한 예측 능력
이러한 특징 덕분에 DeepSeek-V3는 자연어 처리(NLP), 코드 생성, 문제 해결 등 다양한 AI 작업에서 최적의 성능을 발휘할 것으로 기대됩니다.
