DeepSeek
1.DeepSeek V3 & R1

DeepSeek는 V3가 발표될 당시만 해도 회의적인 시각이 많았고, 아직 갈 길이 멀다는 평가가 있었습니다. 그러나 올해 1월 R1이 발표되면서 AI 업계뿐만 아니라 다양한 산업군에서 DeepSeek에 대한 관심이 급격히 높아졌습니다. DeepSeek의 기술 발전
2025년 2월 16일
2.DeepSeek-V3: MoE 기반 AI 모델
DeepSeek-V3는 총 671억 개의 매개변수를 가진 Mix-of-Experts(MoE) 기반의 대규모 Transformer 언어 모델입니다.이 모델은 DeepSeek-R1의 지식을 전수받아 질문 응답, 코드 생성, 수학 문제 해결 등 다양한 작업에 최적화될 수 있
2025년 3월 19일
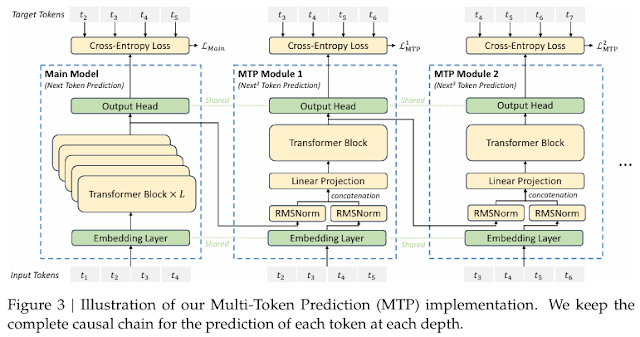
3.MoE와 다중 토큰 예측
이전 포스팅 글에서 DeepSeek에 대해 작성하며, MoE와 다중 토큰 예측을 다루어 좀 더 자세히 작성하기 위한 글입니다. MoE MoE (Mixture of Experts)란 MoE(Mixture of Experts)는 여러 개의 전문가(Experts) 모델을 두고, 입력에 따라 적절한 전문가를 선택해 학습과 예측을 수행하는 모델 구조입니다. -> ...
2025년 3월 19일
4.DeepSeek의 MLA (Multi-Head Latent Attention)
DeepSeek-V3에서 사용한 Multi-Head Latent Attention (MLA) 에서 Latent는 "잠재적인(hidden or latent) 변수"를 의미합니다. 여기서 잠재 변수(Latent Variable) 는 모델이 직접 관측할 수 없는 내재적인 정
2025년 3월 24일