해당 내용은 High-Resolution Image Synthesis with Latent Diffusion Models
관련 리뷰입니다.
Experiments
학습 및 inference 모두에서 픽셀 기반 diffusion model과 비교 및 장점 분석입니다.
VQ-regularized latent space에서 학습된 LDM이 때때로 더 나은 샘플 품질을 생성합니다.
LDM 학습에 대한 정규화 체계의 효과와 보다 큰 해상도에 대한 재구성 능력 사이의 시작적 비교 결과물 입니다.

On Perceptual ession Tradeoffs
해당 논문에서 데이터 압축은 단순히 수학적 재구성 오류를 최소화하는 문제를 넘어, 인간의 지각(Perception)과의 관계를 고려해야 한다고 합니다. 해당 섹션에서는 압축 알고리즘 설계와 평가에서 지각적 품질과 비 지각적 품질 간의 균형점을 다룹니다.
1. 압축과 지각적 품질의 관계
- 데이터 압축은 손실 압축(Lossy Compression)과정에서 데이터를 축소하면서 필연적으로 정보를 버립니다.
- 기존 압축 기술은 주로 수학적 오차(e.g. MSE, PSNR)를 최소화하는 것에 중점을 두지만, 해당 지표들은 항상 인간의 지각 품질과는 일치하지는 않습니다.
- 지각적으로 좋은 압축은 인간이 실제로 이미지나 동영상을 볼 때 품질이 좋게 느껴지는 방향으로 설계 됩니다.
2. 지각적 품질(Perceptual Quality)과 비지각적 품질(Distortion)의 Tradeoffs
- 지각적 품질을 개선하려면, 왜곡(Distortion)을 일부 허용해야 하는 경우가 많습니다.
- 이는 비지각적 오류(e.g. 픽셀 기반 손실)가 높아지더라도, 결과물이 인간 관점에서 더 자연스로운것으로 보일 수 있음을 말합니다.
- 해당 논문에서는 이러한 트레이드오프를 정량화하고 모델링하는 방법을 연구합니다.
3. Rate-Distortion-Perception (RDP) 이론
- 해당 논문은 압축 효율성(Rate), 왜곡(Distortion), 지각적 품질(Perception) 사이의 관계를 RDP 트레이드 오프로 설명합니다.
- 최적의 압축은 세 가지 요소 사이에서 균형을 찾아야 합니다.
- Rate: 데이터 전송률 또는 저장 공간
- Distorition: 압축된 데이터와 원본 데이터 간의 차이
- Perception: 인간이 지각하는 데이터 품질
4. 요약 및 분석
- 지각적 품질과 왜곡의 상호작용을 수학적 분석
- 최적의 압축 설계는 지각적 품질과 왜곡의 상반된 목표를 가지는 경우에도, 특정 목표에 따라 압축 방식의 우선순위를 조정할 수 있어야 함
- 기술적 지표(e.g. MSE, PSNR)의 기존 방식에서 새로운 지표를 제시
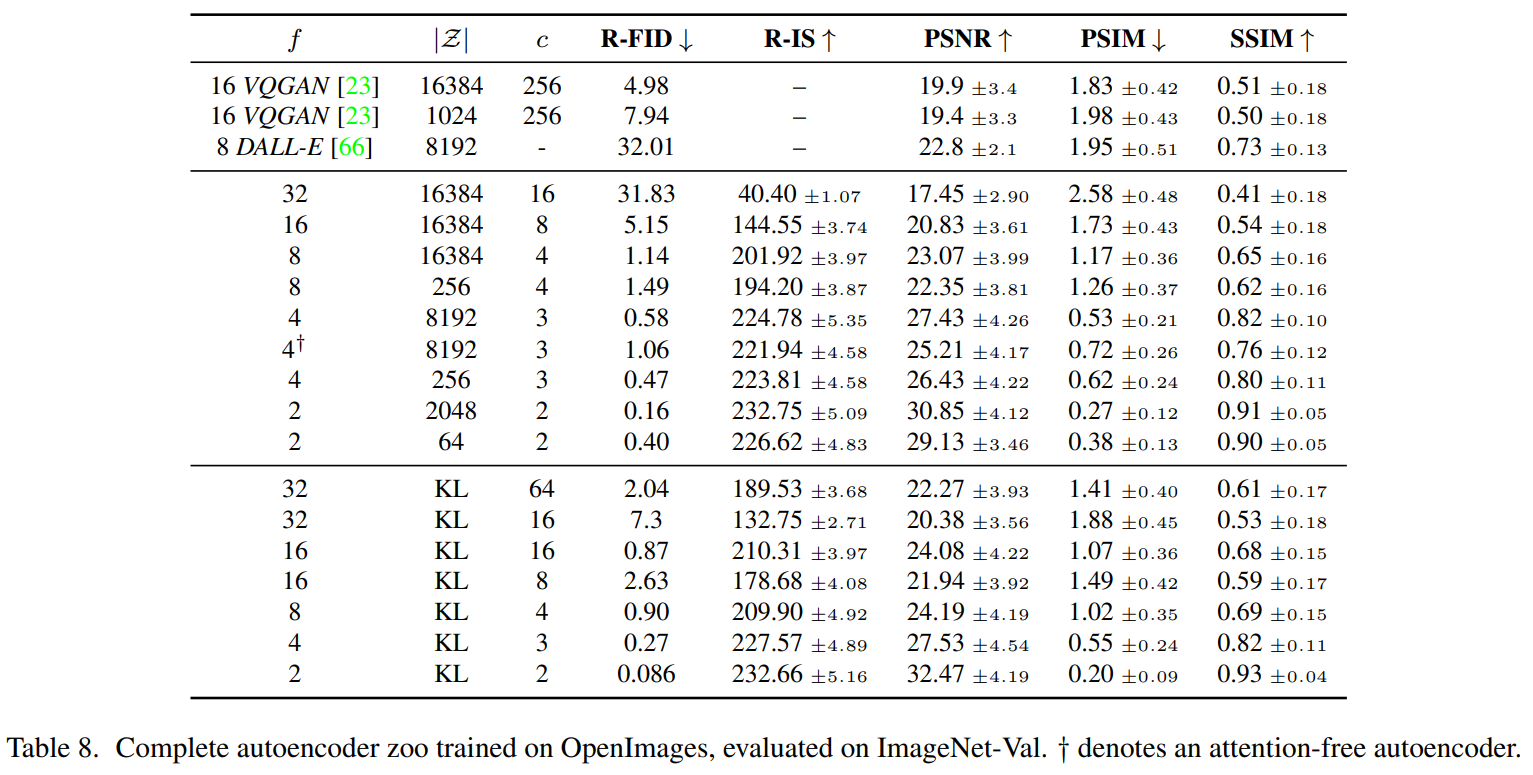
해당 표는 이 섹션에서 비교한 LDM에 사용된 First stage model의 hyper-parmaeter 및 재구성 성능 표입니다.
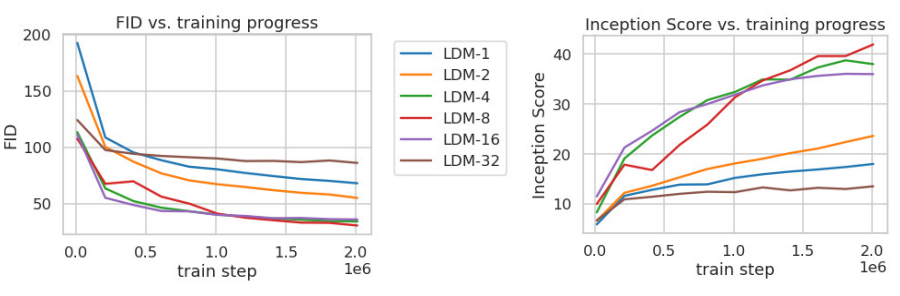
해당 그래프는 ImageNet으로 클래스 조건부 모델을 200만 Step 학습할 때 Step에 대한 샘플 품질 (FID,IS)를 보여줍니다.
해당 결과를 통해 2가지를 확인 할 수 있는데,
1. 작은 Downsampling factor는 학습을 느리게 합니다.(LDM-1, LDM-2)
2. 지나치게 큰 f 값은 비교적 적은 Step에서 샘플 품질의 정체를 유발합니다.(LDM-32)
LDM-4부터 LDM-16까지는 효율성과 Perceptual하게 적절한 균형을 유지합니다.
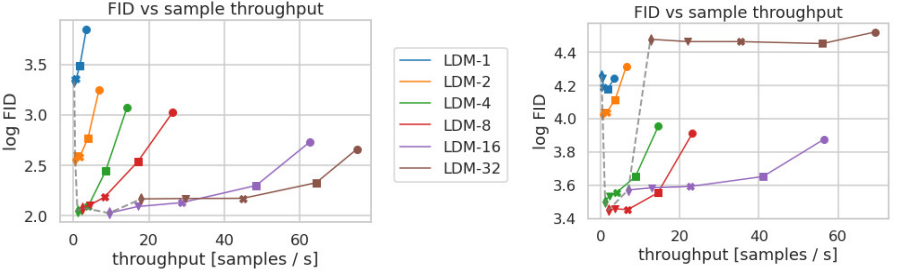
해당 그래프는 CelebA-HQ와 ImageNet으로 학습한 LDM의 샘플링 속도와 FID를 비교한 결과입니다. CelebA-HQ는 50만 step, ImageNet은 200만 step동안 학습되었으며 각 마커는 10, 20, 50, 100, 200 DDIM step으로 샘플링하였습니다.
결과적으로 LDM-4와 LDM-8의 성능이 제일 좋다는 것을 확인 할 수 있습니다.
