해당 논문을 요약하자면 32-bit가 아닌 16-bit로 표현하여 배치 사이즈를 늘리고, 그에 따라 학습 속도를 빠르게 할 수 있는 Mixed Precision Training이라는 기술을 다룹니다.
해당 과정에서 발생할 수 있는 문제를 Adaptive 방식으로 해결하는 과정과 나아가 Automatic Mixed Precision이하 AMP를 다루고 있습니다.
Mixed Precision
Single Precision(Floating Point32, FP32)가 딥러닝에서 가장 적합한 파라미터인가를 연구하다 Half Precision(Floating Point16, FP16)을 활용한다면 모델 성능을 비교 했을 때 크게 차이 나지 상태에서 모델 학습에 필요한 메모리를 줄이고, 연산 속도 또한 가속 시킬 수 있지 않을까라는 관점에서 생겨 났습니다.
모델 파라미터를 32-bit에서 16-bit로 줄인 것에 대한 장단점입니다.
Single Precision - 4bytes (32bits)
Double Precision - 8bytes (64bits)
FP32와 FP16의 차이점
- FP32는 23비트의 가수를 가지고 있어 높은 정밀도를 가지며, 작은 값의 변화까지도 정확하게 표현 할 수 있습니다.
- FP16은 10비트의 가수만을 가지므로, 큰 범위의 값만을 표현하기 적합하며 작은 값의 정밀도는 떨어질 수 있습니다.
- 두 이유로 인해 Gradient Vanishing 문제가 발생할 수 있으며, Mixed Precision Training이 이것을 해결하기 위해 사용 됩니다.
장점
- 같은 모델이라도 더욱 빠른 학습을 통해 빠르게 결과를 얻음
- 빠른 학습, 그에 따른 적은 GPU 사용량
- 모델 구조에 구애 받지 않고 모든 모델에 적용 가능 -> FP16연산은 GPU의 Tensor Core에서 최적화되어 제공되며, 대부ㅜㄴ의 딥러닝 모델 연산은 텐서 고셈(MatMul)을 포함하고 있어 이를 활용할 수 있음
2번과 3번은 현재 점점 커다란 AI모델들이 나오면서 더욱 이득을 볼 수 있는 장점이 되었습니다.
단점
NVIDIA Technical Blog에서 실험한 Object Detection에서 SSD(Single Shot Multibox Detector)모델의 파라미터가 가진 Gradient 분포 표입니다.
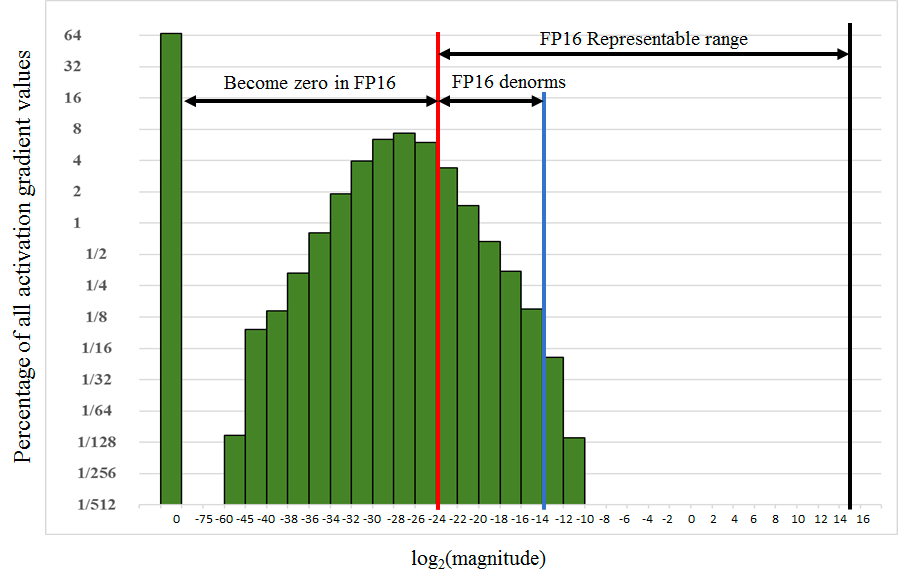
빨간선 기준으로 왼쪽은 FP16으로는 표현 할 수 없는 범위이고 오른쪽은 가능한 범위입니다. 절반 이상의 gradient가 FP16으로는 표현할 수 없기 때문에 FP16으로 학습을 한다면 많은 정보가 소실될 것으로 유추가 가능합니다.
표현이 불가능한 이유는 bit수에 따라 표현 숫자가 크게 차이가 나기 때문인데,
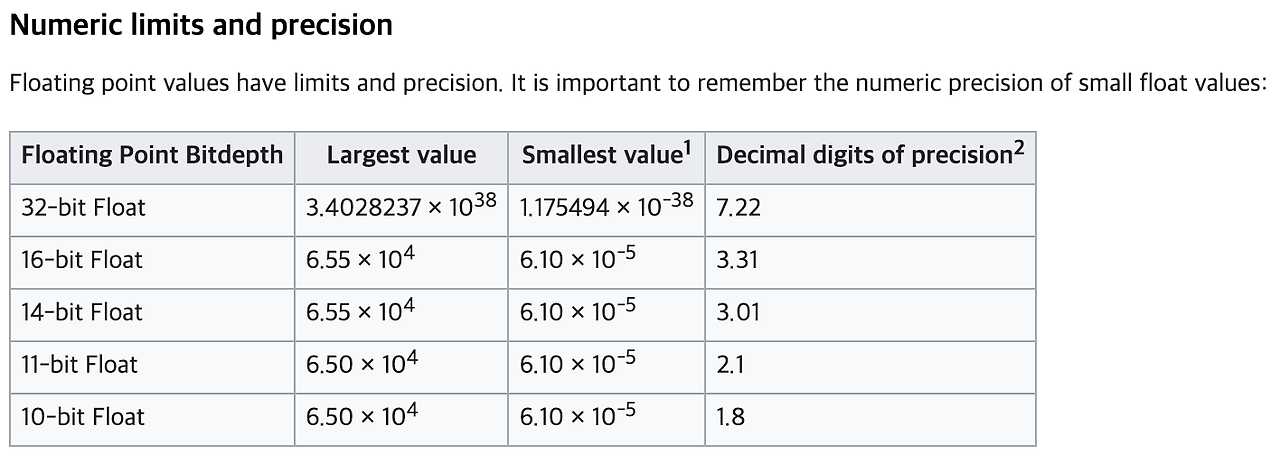
위의 FP의 bit수(bit Depth)에 따른 표현 값의 최대 - 최소 정밀도 표를 확인하면
32-bit와 16-bit의 표현 할 수 있는 범위의 차이가 크다는 것을 알 수 있습니다.
그렇기 때문에 8-bit와 4-bit를 활용 하는 방식은 장점에 비해 단점이 커 사용하지 않는 것을 추천합니다.
FP16을 활용해서 메모리와 속도의 이점을 가져가고 싶지만, Fully Designed to FP16모델은 위와 같은 문제가 있고, 해당 문제를 통한 성능 저하를 막기 위해 나온 방식이 Mixed Precision입니다.
- 주의 : FP16은 C에서 지원하지 않기 때문에 CPython 기반인 Numpy를 활용해도 16-bit 와 32-bit 속도 차이는 없다는 내용의 보고가 많습니다.
Gradient Clipping의 이유 : FP16의 표현 범위를 벗어난 Gradient는 소실되거나 왜곡되며, 학스 ㅂ과정에서 잘못된 업데이트가 생길 수 있음
Adaptive Scaliiung Factor를 통해 이러한 문제를 완화하며, PyTorch의 AMP는 이를 자동으로 처리함
방법
Mixed라는 이름철럼 파라미터를 FP32와 FP16을 적절히 섞어 학습하는 것이며,
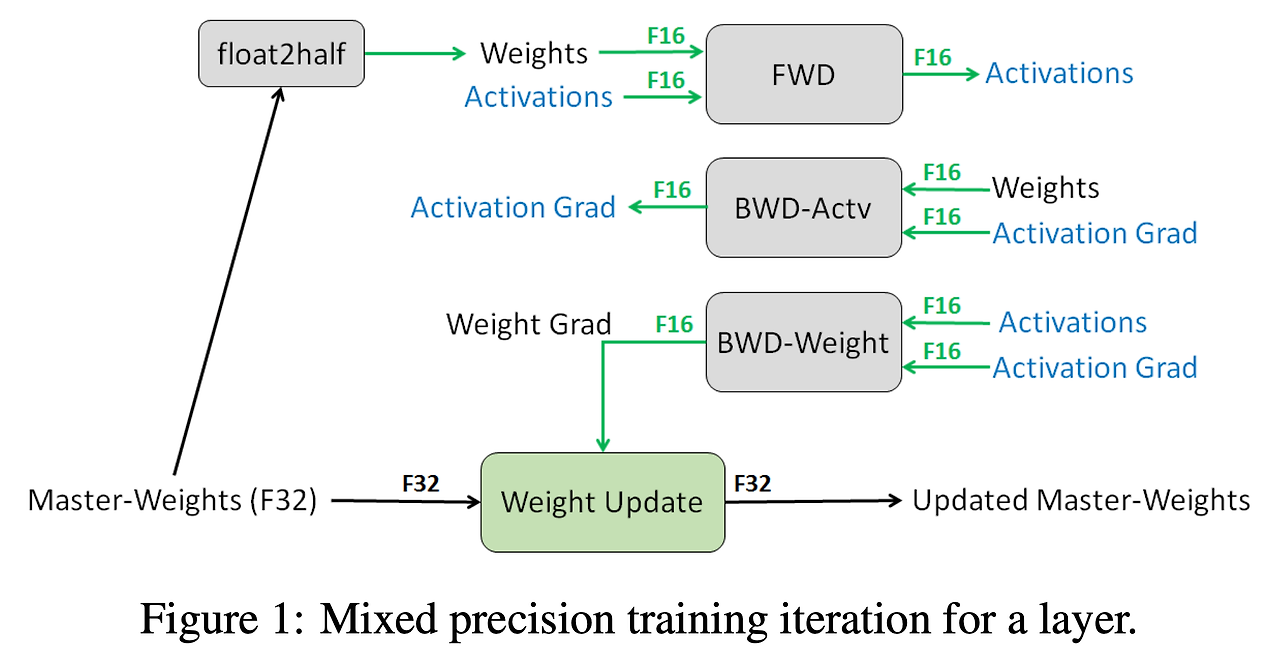
Mixed-Precision Training Iteration Version1
- FP32로 표현된 FP32 Master weights를 복사하여 FP16 weights를 만듭니다.
- FP16으로 Forward Propagation 진행합니다 (주의 : gradient는 FP16일 것)
- Loss 값을 Scale factor S로 곱합니다.
- 얻은 FP16 gradient를 Backpropagtion 합니다.
- 3번에서 S를 곱하였기 때문에, BackProp해서 얻은 weight gradient에 S를 나누어 줍니다.
- Gradient Clipping, wieght decay등을 적용합니다.
- FP32 Master weights를 업데이트합니다.
해당 방법은 문제는 Scaling factor S가 너무 크거나 작으면 곱하고 나누는 과정에서 Inf 도는 NaN이 발생할 수 있습니다. 방지는 방법으로는 gradient의 최댓값이 65,504(FP16 Max값)을 넘지 않도록 설계하는 방법이 있습니다. 초기 S를 크게 설정하되 iteration이 지나서 학습에 문제가 발생하면 S를 키우거나 줄이는 방법인 Adaptive를 사용합니다.
Mixed-Precision Training Iteration Version2
- FP32로 표현된 FP32 Master weights를 저장합니다.
- S의 초기값을 큰 수로 설정합니다.
- 매 iteration마다 아래 방법을 수행합니다.
A. FP16으로 Forward Propagation 진행합니다 (주의 : gradient는 FP16일 것)
B. Loss 값을 Scale factor S로 곱합니다.
C. 얻은 FP16 gradient를 Backpropagtion 합니다.
D. 만약 모델 전체 weight의 gradient 중에서 하나라도 inf 또는 NaN이 발생한다면
- S값을 줄인다.
- wieght update를 하지 않고 다음 iteration로 넘어값니다. (f,g,h 건너뜀)
E. BackProp해서 얻은 weight gradient에 S를 나누어 줍니다.
F. Gradient Clipping, wieght decay등을 적용합니다.
G. FP32 Master weights를 업데이트합니다.
S값을 키우는 이유
S를 곱한다는 의미는 위의
해당 그림에 있는 모든 막대기를 오른쪽으로 이동시킨다는 의미입니다. 빨간색 선 오른쪽으로는 16-bit로 표현할 수 있는 범위라고 했으므로, 최대한 많은 파라미터를 빨간색 오른쪽으로 이동시키는 것이 이 방법의 학심입니다.
참고로 PyTorch에서는 GradScaler S의 초기값이 65536.0으로 설정
NaN/Inf 추가 설명
NaN 또는 Inf 문제에서 Scaling Factor S를 조정하는 이유
- S가 너무 크면 Loss를 곱할 때 FP16의 표현 범위를 넘어 NaN/Inf가 발생, S가 너무 작으면 Gradient가 소수점 아래로 줄어들어 Vanishing(소실)될 가능성이 높음
요약하자면 Mixed Precision을 이용해서 학습할 경우 성능의 저하는 적고, throughput은 1~5배 증가한 것을 표에서 확인 할 수 있습니다.
주의
AllowList, DenyList, InterList
DenyList를 두 분류로 나눠보면
- Linear operation: Large reductions, L1 Loss
- Non-linear operation: Cross entropy loss, Exponential
Non-linear는 log 또는 e등의 지수연산이 들어가기 때문에 쉽게 FP16의 표현 범위가 넘어갈 것으로 예상되어, Mixed Precision적용 시 형변환을 하면서 성능 저하가 발생할 것을 알 수 있습니다.
Linear 또한 단순 사칙연산이라 괜찮을 수 있지만 L1 Loss는 mean 또는 sum연산이 옵션으로 존재하여, Large mini-batch를 가정했을 때 성능 저하를 일으킬 수 있습니다.
[AMP]Automatic Mixed Precision
What is Automatic Mixed Precision AMP and how can it help with training my model?
- Automatic Mixed Precision AMP makes all the required adjustments to train models using mixed precision, providing two benefits over manual operations:
- Developers need not modify network model code, reducing development and maintenance effort.
- Using AMP maintains forward and backward compatibility with all the APIs for defining and running models.
요약하자면 Mixed Precision을 쉽게 적용할 수 있게 프레임워크 차원에서 제공하는 것을 의미합니다.
사용방법 예시
scaler = torch.cuda.amp.GradScaler()
for inputs, labels in data_loader:
with torch.cuda.amp.autocast():
outputs = model(inputs)
loss = loss_fn(outputs, labels)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()주의 사항
- 모든 연산이 FP16에 적합하지 않으므로 프레임워크가 AllowList, DenyList를 사용해 연산 타입을 관리
- 모델의 특정 연산이 AllowList/DenyList에 적합하지 않을 경우 성능 최적화 제한
- 초대형 모델에서는 여전히 메모리 부족 문제 발생
