연구의 목적
기존 연구는 지도학습(SFT)에 의존해 대규모 언어 모델(LLMs)의 성능을 개선하였으나, 지도 학습 데이터는 수집과 라벨링에 많이 시간과 비용을 소요되어 이것을 개선하기 위해 연구
목표
- 지도학습 없이 강화학습(RL)만으로 LLM이 추론 능력을 학습하고 발전 할 수 있음을 입증
- 새로운 학습 파이프라인(Cold-Start 데이터 및 다단계 학습)을 통해 추론성능과 사용자 친화성을 강화
- 대형 모델에서 학습한 추론 능엵을 소형 모델로 지식 증류(Distillation)하여 성능과 효율성을 확보
주요 모델
DeepSeek-R1-Zero
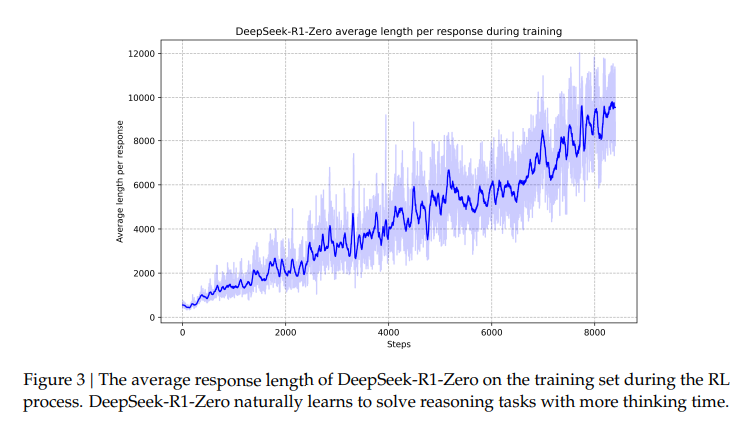
특징
- 지도학습 없이 순수 강화학습만으로 학습
- 모델이 강화학습 환경에서 스스로 진화(Self-Evolution)하여 복잡한 문제를 해결하기 위한 추론 능력을 개발
- GRPO(Group Relative Policy Optimization) 알고리즘을 사용하여 강화학습 비용을 절감
결과
- AIME 2024 벤치마크 Pass@1에서 점수 15.6% -> 71.0% 상승
- 다수결 투표(Majority Voting)로 성능 86.7%까지 향상(OpenAi o1-0912와 비슷)
- 모델은 자기 검증(Self-Verification), 자기 반성(Reflection), 긴 Chain-of-Thought(CoT)를 생성하는 능력 학습
한계점
- 생성된 응답에서 가독성(Readability)저하
- 언어 혼합(Language Mixing)문제 확인

AI (ML/DL) 학습