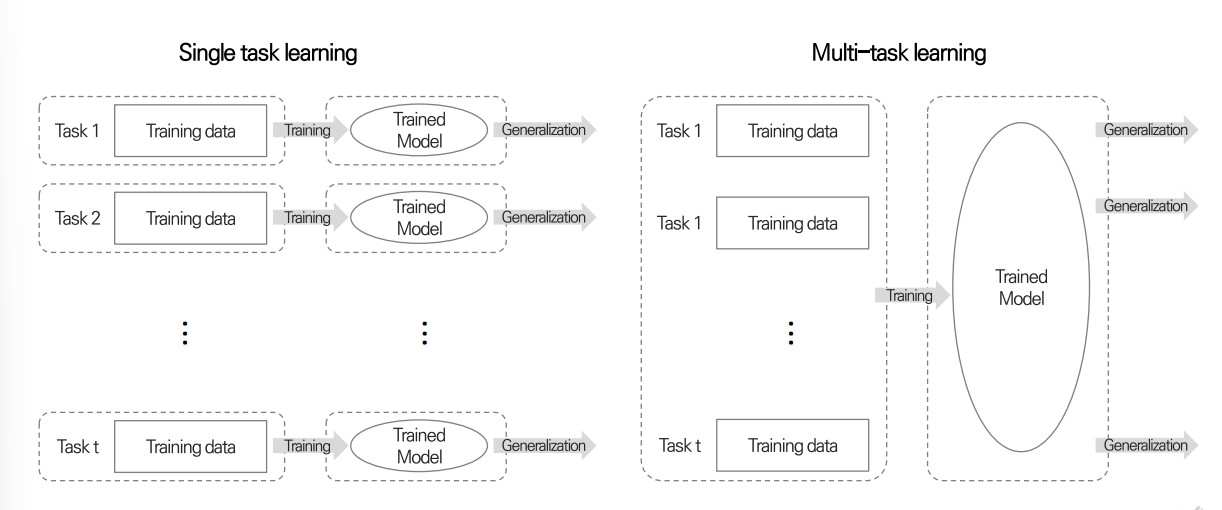
Multi-task Learning Model 이란?
- 다양한 task를 각기 다른 training 데이터를 이용해 동시에 학습하는 모델
- 다른 task를 하나의 training 데이터 셋을 이용하는 경우는 Multi-label Learning, Multi-output Regression 에 해당한다.
- 다양한 task 동시에 학습함으로써, 서로 다른 task 간에 유용한 특징과 패턴을 공유하며 학습할 수 있음. 특히 각 작업에 충분한 데이터가 부족하거나 각 작업이 상호보완적인 정보를 제공하는 경우에 효과적임
- 예) 대구 교통사고 예측 ECLO안의 각 변수를 모두 한 번에 예측하기
- 예) 건강검진 결과로 우울증을 예측하는 프로젝트에서 현재 유병 여부와 PHQ 설문 응답을 동시에 예측하기
Transfer Learning, Multi-task Learning, Multi-label Learning
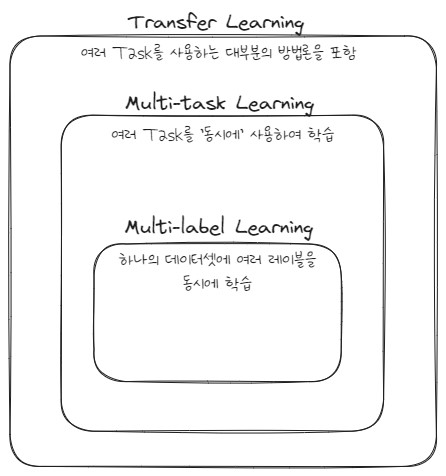
- Transfer Learning
- Target task와 source task로 구분됨
- Souce task에서 얻은 지식을 target task에서 활용해 target task를 잘하는 것이 목표
- Sequential Learning
- Multi-task Learning
- 모든 task들을 잘 하는 것이 목표임.
- 각 task에서 얻은 지식들을 공유하고(knowledge sharing), 각 task 활용함.
- Parallel Learning
- 여러 데이터셋으로 구성이 가능하고, 데이터 별로 다른 task 수행할 수도 있음
- 동시에 여러 데이터셋을 학습
- Multi-label Learning
- 하나의 데이터셋을 사용
- 각 데이터 샘플별로 m개의 label이 존재
- 동시에 여러 label들을 학습
Multi-task model for Multi-label dataset
하나의 데이터셋을 사용할 경우 (w/o sharing)
- 같은 데이터가 각각의 모델 입력 값으로 사용되며, 각 모델은 하나의 레이블을 예측하는 데에 최적화된다.
- task별로 사용되는 Loss가 다름
1) 파라미터를 공유하는 경우 (Soft parameter sharing) - 각 모델의 파라미터간 거리를 줄이는 제약식이 추가되며, 파라미터들이 비슷하게 학습되는 일반화(regularization)효과가 나타난다.
- Loss function에도 Knowledge sharing이 추가됨
2) 파라미터를 공유하는 경우 (Hard parameter sharing) - 일부 파라미터들을 완전히 공유하는 형태
- 하나의 모델로 여러 개의 레이블을 예측한다. (Multi-head)
3) Soft + Hard 둘다 사용하는 경우도 가능
Multi-task model for Multi dataset
여러 데이터셋을 학습시킬 경우
- 입력 데이터(X)와 레이블(y)이 task별로 다르다.
- One-hot vector와 같은 각 데이터셋별로 task 상태를 알려주는 정보가 필요함
Loss function
- Uniform weight: 각 태스크별 loss가 같은 비율로 더해지는 경우
- weighted sum: 각 태스크별 loss가 다른 비율로 더해지는 경우
- 태스크별 중요도/정확도에 따라 직접 설정할 수 있음. 어렵거나 중요한 태스크에 가중치를 높게 설정하는 것. 하지만 가중치에 따라 태스크별 성능 trade-off가 일어남.
- 모델 학습시 동시에 가중치 학습을 진행하는 등 다양한 방법이 있음.
Pros and Cons
장점
- 지식 공유 (Knowledge sharing): task 1을 학습하면서 얻은 정보가 다른 연관 task들에게 좋은 영향을 줄 수 있음.
- 과적합 방지: 같은 모델에 여러 task들의 데이터를 학습하기 때문에 효율적이고, 보다 일반화된 특징을 학습할 수 있음.
- 동시에 학습하기 때문에 계산 비용이 적고, 다양한 task들을 수행할 수 있기 때문에 현실적임.
단점
- Negative transfer: 연관성이 부족한 task들을 학습할 때 단일 모델보다 성능이 낮을 수 있음
- task 별 차이가 크면 학습이 어려움
관련 논문
- Gradient Surgery for Multi-Task Learning, 2020
- 자세한 리뷰는 reference의 pdf자료 참고
Reference

AI (ML/DL) 학습