
전 시간에 배운 의사결정나무 모델 이용한 방법인 랜덤포레스트에대해 배워보도록하겠습니다.
램덤포레스트(RandomForest)
램덤포레스트란 의사결정나무 모델 여러 개를 훈련시켜서 그 결과를 종합해 예측하는 앙상블 알고리즙입니다. 각 의사결정나무 모델을 배깅(Bagging)방식으로 훈련시킵니다.
배깅(Bagging)
1.전체 Train dataset에서 중복을 허용해 샘플링한 Dataset으로 개별 의사결정나무 모델을 훈력하는 방식
2.여러 모델을 통해 예측값의 평균을 취하여 최정적인 예측값을 구함
3.예측 모델의 일반화(generalization,안정성) 성능을 향상시킴
| 장점 | 단점 |
|---|---|
| 일반화 및 성능 우수 | 개별 트리 분석이 어렵고 트리가 복잡해짐 |
| 파라미터 조정 용이 | 차원이 크고 희소한 데이터는 성능 하락 |
| 데이터 scale변환 불필요 | 훈련시 메모리 소모가 큼 |
| overfitting이 잘 일어나지 않음 | Train data를 추가해도 성능 개선이 어려움 |
데이터셋 불러오기
input
from sklearn.datasets import make_moons
#랜덤 데이터셋
X,y=make_moons(n_samples=100, noise=0.25, random_state=3)초반 앞부분은 의사결정나무와 같습니다.
검증,연습 분류
input
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,stratify=y,random_state=42)모델학습
input
from sklearn.ensemble import RandomForestClassifier
# n_estimators 분류기 개수
forest=RandomForestClassifier(n_estimators=6, random_state=2, criterion='entropy')
forest.fit(X_train,y_train)output

랜덤포레스트를 이용하여 모델을 학습해줍니다. n_estimators는 분류를 뜻합니다.
불순도를 측정하는 criterion은 의사결정나무에서는 gini를 사용해보았으니 이번엔 entropy를 사용해 보겠습니다.
모델 평가
input
print(forest.score(X_train,y_train))
print(forest.score(X_test,y_test))output
0.96
0.92
트리 찾기
input
import numpy as np
idx=0
result=[]
# estimators_ 분류기 리스트
for f in forest.estimators_:
result.append(f.score(X_test,y_test))
idx+=1
print(result)
print(max(result))
print(np.argmax(result)) #최대값의 인덱스
# 6개의 트리 중 가장 정확도가 높은 트리 선택output
[0.84, 0.88, 0.8, 0.92, 0.88, 0.8]
0.92
3
가장 높은 점수가 나온 트리를 찾아보기 위한 방법입니다.
시각화
input
import matplotlib.pyplot as plt
from sklearn import tree
plt.figure(figsize=(10,7))
tree.plot_tree(forest.estimators_[3]) #가장 정확도가 높은 트리
plt.show()output
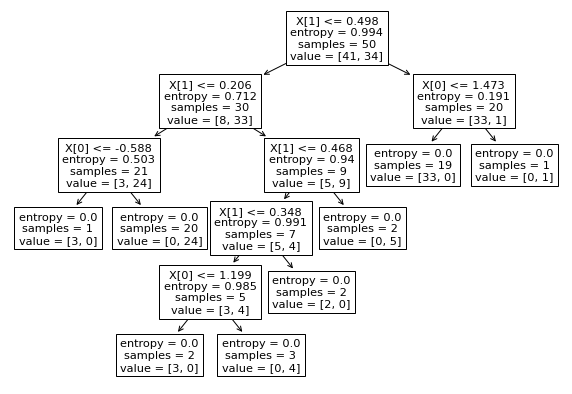
graphviz 시각화
input
from sklearn.tree import export_graphviz
import pydotplus
import graphviz
from IPython.display import Image
dot_data=export_graphviz(forest.estimators_[3], out_file=None, feature_names=[0,1], class_names=['0','1'], filled=True, rounded=True, special_characters=True)
graph=pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())output
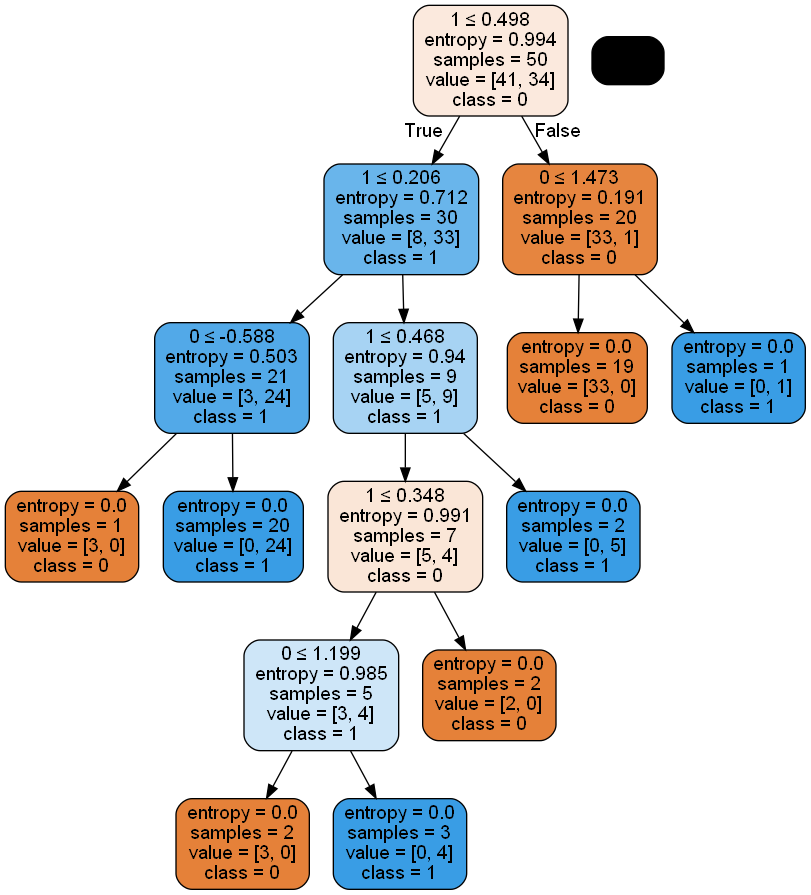
배열전환
input
print(np.arange(12))
x=np.arange(12).reshape(3,4) # 1차원 배열을 3행 4열의 2차원 배열로 변환
print(x)
print(np.ravel(x)) # 다차원 배열을 1차원 배열로 변환output
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
x값은 2차원 배열로 변환한 것을 저장하였기 때문에 이후 진행은 2차원 배열로 진행됩니다.
np.ravel은 바꾸는 방법을 보여드리기위해 작성한 것입니다.
3트리 산점도 시각화
input
import mglearn
mglearn.plots.plot_2d_separator(forest.estimators_[3], X, fill=True, alpha=0.4)
plt.title('random forest')
mglearn.discrete_scatter(X[:,0],X[:,1],y)output
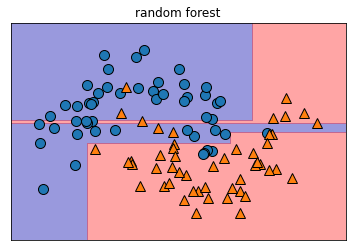
모든 트리 시각화
input
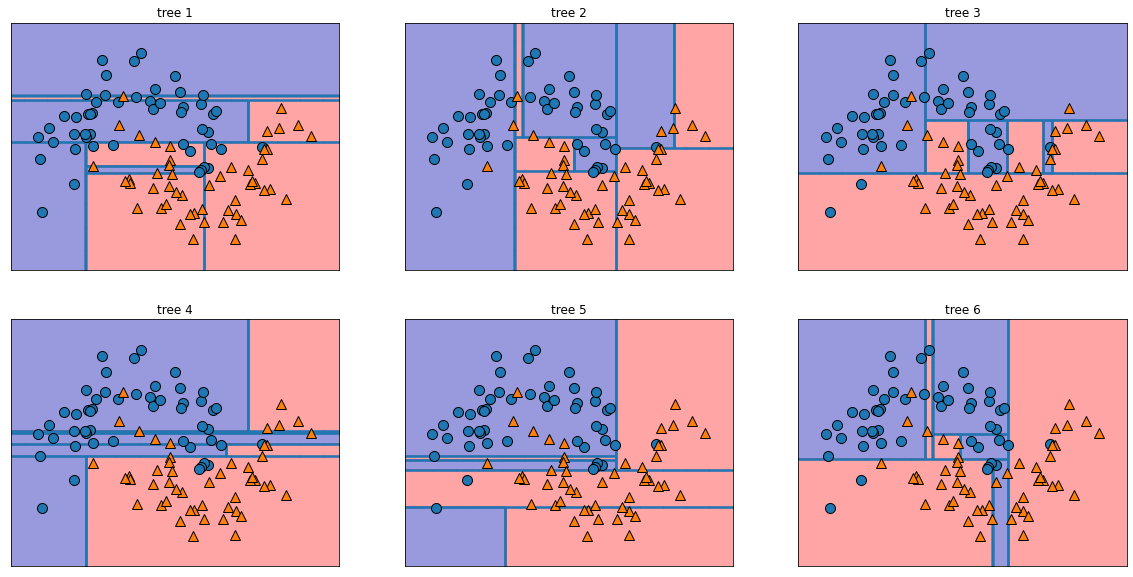
fig,axes=plt.subplots(2,3,figsize=(20,10))
for i, (ax,tree) in enumerate(zip(axes.ravel(), forest.estimators_)):
ax.set_title(f'tree {i+1}')
mglearn.plots.plot_tree_partition(X,y,tree,ax=ax)output
오늘은 의사결정나무를 활용한 랜덤포레스트에대해 배워보았습니다. 각 방법마다 특징, 장단점이 다르기 떄문에 적용하는 방법도 조금씩 차이가 있습니다만, 데이터셋 -> 전처리 -> 학습 -> 출력의 틀은 비슷하다고 생각합니다.
😁 power through to the end 😁
