
오늘은 의사결정나무(Decisiontree)에 대해서 공부해보도록 하겠습니다.
의사결정나무(Decisiontree)
의사결정나무란 if~else와 같이 특정 조건을 기준으로 참/거짓으로 나누어 분류/회귀를 진행하는 tree구조의 분류/회귀 데이터마이닝 기법입니다.
tree구조란 그래프의 일종으로, 한 노드(구역)에서 시작해서 다른 정점(구역)들을 순회하여 자기 자신에게 돌아오는 순환 없는 연결 그래프입니다.
tree구조는 코딩테스트에서 자주 나오는 기법중 하나로 백트레킹과 자주 나오기 때문에 예시로 보시면 잘 아실거라고 생각합니다.
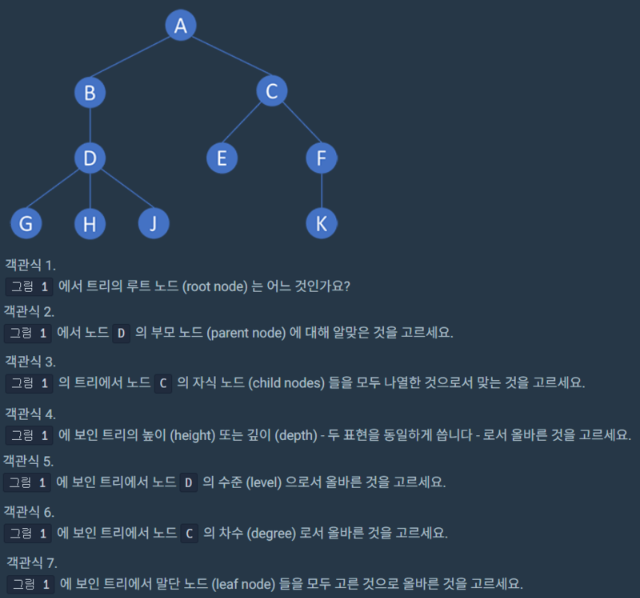
다음과 같은 이미지가 tree의 기본적인 구조입니다. 정답을 통해 tree를 가볍게 공부해 보겠습니다.
1. 루트 노드는 가장 위에 있는 노드를 뜻 합니다. 정답: 'A' 2. 노드 'D'의 부모 노드는 바로 상위 level 노드를 뜻 합니다. 정답: 'B' 3. 노드 'C'의 자식 노드는 바로 하위 level 노드를 뜻 합니다. 정답: 'E', 'F' 4. 트리의 높이는 root 노드부터 level을 하나씩 count 해주면 됩니다.이것을 depth(깊이)라고 합니다. 정답: '4' 5. 정답: 'level 2' 6. degree(차수)는 level + 1 입니다. 정답: '2' 7. 말단 노드는 자식이 없는 노드를 뜻합니다. 정답: 'E','G','H','J','K'
의사결정나무의 특징으로는
- 이해도가 높고 직관적이기 때문에 자주 사용됩니다.
- 종속변수의 형태에 따라 분류와 회귀로 나뉩니다.
- 종속변수가 범주형일 경우 DTC(DecisionTreeClassification)으로 분류합니다.
- 종속변수가 연속형일 경우 DTR(DecisionTreeRegression)으로 회귀합니다.
moons 데이터셋 불러오기
input
from sklearn.datasets import make_moons
X,y=make_moons(n_samples=100, noise=0.25, random_state=3)sklearn에서 지원해주는 moons 데이터셋을 이용하여 tree에 대해 배워보기위해 데이터셋을 불러옵니다.
test와 train 분류
input
from sklearn.model_selection import train_test_split
# 학습용:검증용 75:25
X_train,X_test,y_train,y_test=train_test_split(X,y,stratify=y,random_state=0)학습용과 검증용을 default값인 75:25 비율로 나누어 줍니다.
tree 모델 학습
input
from sklearn.tree import DecisionTreeClassifier
#의사결정나무모형
model=DecisionTreeClassifier(random_state=2, max_depth=3, criterion='gini')
model.fit(X_train,y_train)output
max_depth(최대깊이)는 트리를 얼마나 뻗을 건지 선택하는 것이고, gini는 알고리즘을 사용하여 경계선 선택, 속도는 느리지만 엔트로피 알고리즘이 더 정확합니다.
정확도 평가
input
print(model.score(X_train,y_train))
print(model.score(X_test,y_test))output
0.9066666666666666
0.92
tree 구조 확인
input
from sklearn import tree
import matplotlib.pyplot as plt
plt.figure(figsize=(20,15))
tree.plot_tree(model)
plt.show()output
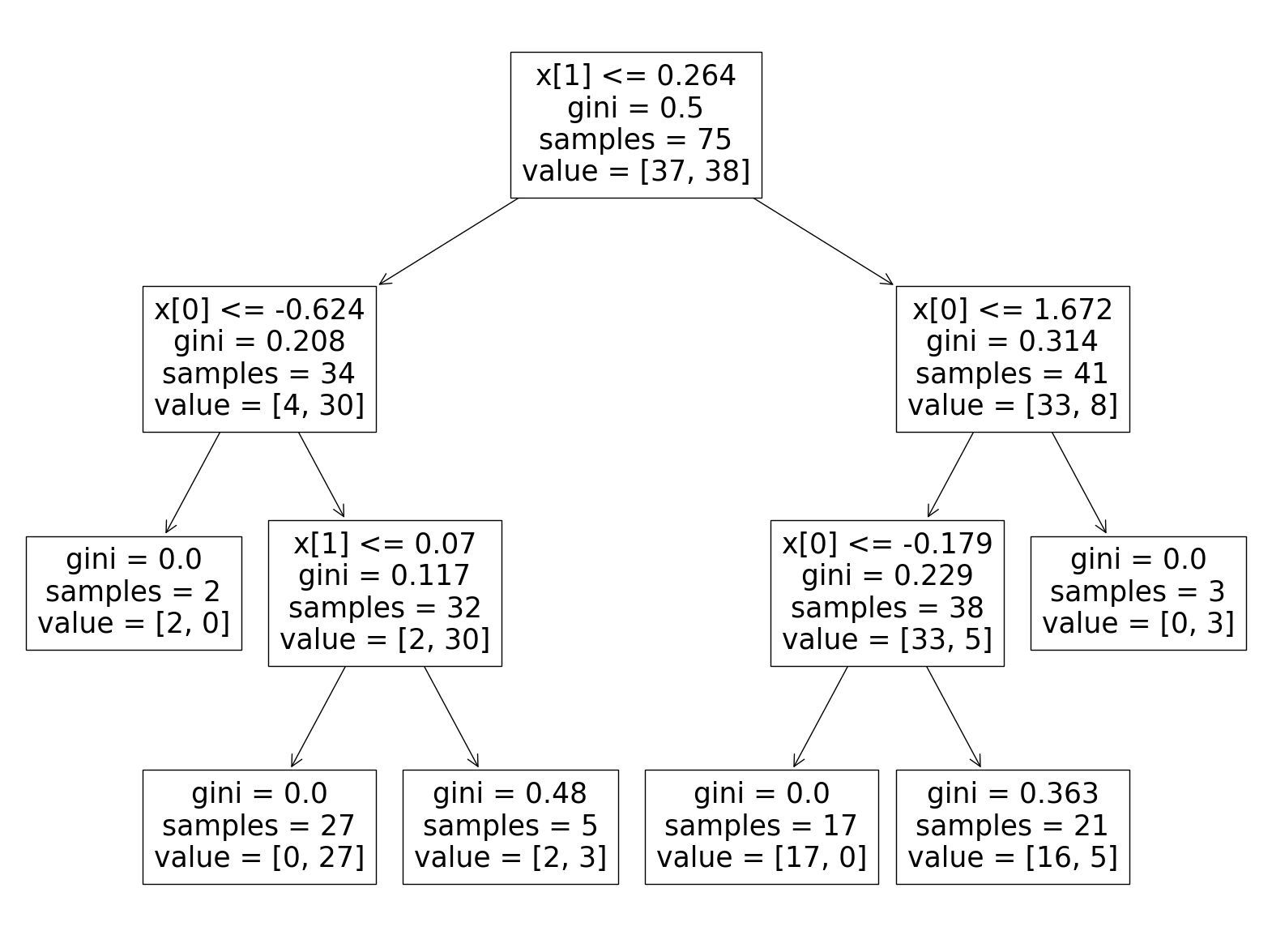
최대 3의 깊이를 가진 tree가 만들어 졌습니다.
graphviz 시각화
input
# pip install pydotplus
# pip install graphviz
from sklearn.tree import export_graphviz
import pydotplus
from IPython.display import Image
dot_data=export_graphviz(model, out_file=None, feature_names=[0,1], class_names=['0','1'],filled=True,rounded=True,special_characters=True)
graph=pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())output
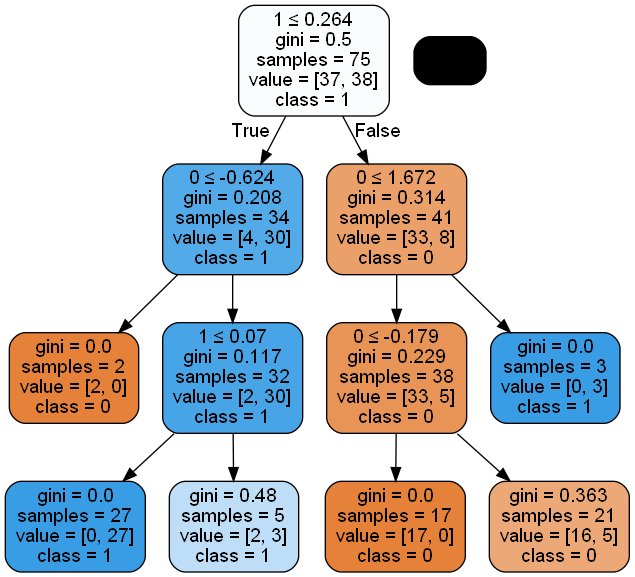
graphviz를 이용하면 좀 더 직관적으로 데이터를 시각화 할 수 있습니다.
산점도 확인
input
import mglearn
plt.title('Tree')
mglearn.plots.plot_2d_separator(model, X, fill=True, alpha=0.4) #분류 면
mglearn.discrete_scatter(X[:,0], X[:,1], y) # 산점도
plt.show()output
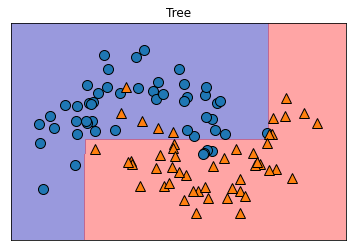
데이터 값이 어떤식으로 분포 되었고 분류를 하였는지 알 수 있습니다.
오늘은 분석의 여러가지 방법 중 tree에 대해서 배워 보았습니다. Knn,Ann,svm,..등등 많은 분석 방법 중 tree의 장점은 중요도등을 확인하기도 간편하여서 굉장히 좋은 방법중 하나라고 생각합니다.
😁 power through to the end 😁
