Reference: DSBA https://www.youtube.com/watch?v=0kgDve_vC1o&t=536s
VIT 학습입니다.
Inductive Bias
- training에서 보지 못한 데이터에 대해서도 적절한 귀납적 추론(개별 -> 보편)이 가능하도록 하기 위해 모델이 가지고 있는 가정들의 집합
- 모델의 일반화를 위함
- DNN의 기본적 요소들의 inductive bias는 다음과 같다
- Fully connected layer: 입력 및 출력 element가 모두 연결되어 있으므로 구조적으로 특별한 relational inductive bias를 가정하지 않음
- Convolutional lyaer: CNN은 작은 크기의 kernel로 이미지를 지역적으로 보며, 동일한 kernel로 이미지 전체를 본다는 점에서 locality, transitional invariance 특성을 가짐
- Recurrent layer: RNN은 입력한 데이터들이 시간적 특성을 가지고 있다고 가정하므로 sequentiality, temporal invariance 특성을 가지고 있음.
- 이와 같이, CNN, RNN은 inductive bias를 가지고 있지만, Transformer는 self-attention을 기반으로 하기 때문에 위 둘보다는 상대적으로 낮은 inductive bias를 가지고 가지고 있음.
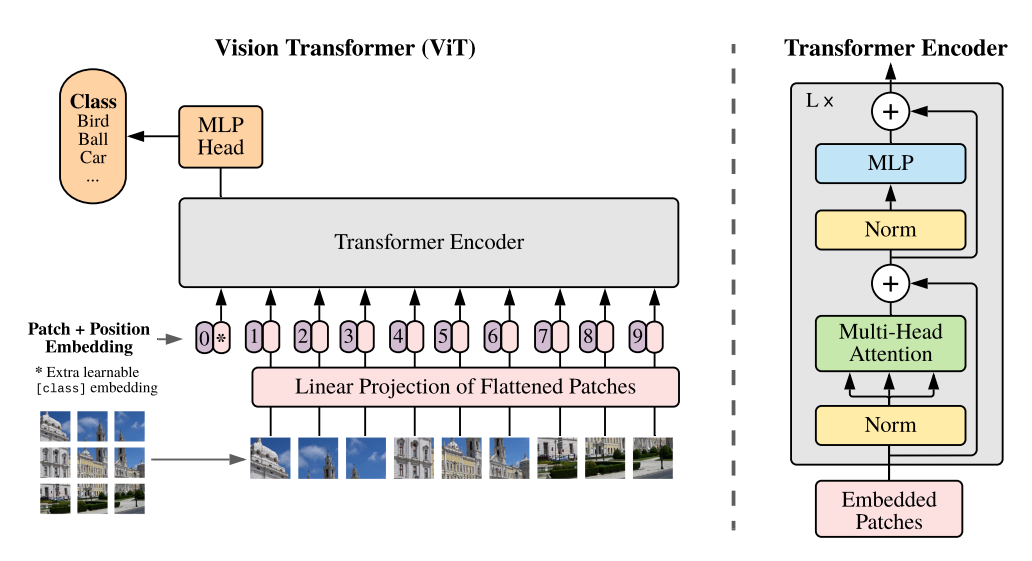
Vision Transformer(ViT)란?
- ViT는 이미지를 패치로 분할한 후, 이를 NLP의 단어처럼 취급해서 각 패치의 linear embedding을 순서대로 Transformer의 input으로 넣어서 이미지를 분류한다.
ViT 모델 구조
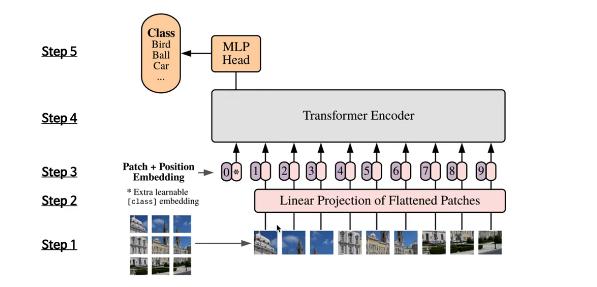
- Step 1: 이미지 가 있을 때, 이미지를 크기의 패치 개로 분할하여 패치 sequence 를 구축함.
- Step 2: 9개의 패치를 순서대로 받아서 Trainable linear projection을 통해 의 각 패치를 flatten한 백터를 D차원으로 변환하고, 이를 패치 임베딩으로 사용한다.
- Step 3: Learnable class 임베딩(0th vector *)과 패치 임베딩에 learnable position 임베딩을 더해준다. (0~9)
- Step 4: 임베딩을 vanila Transformer encoder에 인풋으로 넣어서, 마지막 layer에서 class embedding에 대한 아웃풋인 image representation을 도출한다.
- Step 5: MLP에 image representation을 인풋으로 넣어 이미지의 class를 분류한다.
Positional Embedding
- ViT에서는 No positional info, 1D positional embedding, 2D positional embedding, Relative positional embedding 이렇게 4개의 positional embedding 방식을 사용해본 뒤에, 가장 효과가 좋았던 1D positional embedding을 사용한다.
- 1D positional embedding 이란?
- considering the inputs as a sequence of patches in the raster order
- 즉, 패치의 순서를 왼쪽 위부터 오른쪽 아래까지 순서대로 위치를 보는 것(raster order)

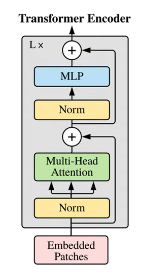
Transformer Encoder
- ViT는 Multi-head Self Attention(MSA)와 MLP block으로 구성되어 있음
- MLP는 2개의 layer를 가지며, GELU activation function을 사용함.
- Attention is all you need의 Transformer Encoder와 다른 점?
- MSA와 MLP 뒷단에 LN과 residual connection layer가 적용되어있었는데, ViT는 각 block의 앞에 LN을 적용하고, 각 block의 뒤에는 residual connection(=skip connection)을 적용함.
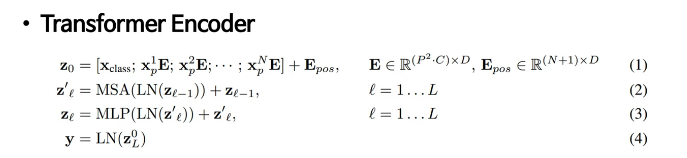
Hybrid Architecture
- ViT는 raw이미지를 패치로 나누어서 인풋으로 받고 있는데, 이걸 raw 이미지가 아닌, CNN으로 추출한 raw이미지의 feature map을 인풋으로 이용하는 hybrid architecture로도 사용할 수 있음.
- feature map은 이미 raw 이미지의 공간적 정보를 포함하고 있으므로 hybrid architecture로 쓰는 경우에는 패치 크기를 1x1으로 설정해도 된다. 이 경우에는 feature map의 공간 차원을 flatten하여 각 베터에 linear projection을 하면 됨
Fine-tuning and Higher Resolution
- raw이미지를 패치로 나누어서 사용하는 방법 2) CNN을 이용해서 추출한 feature map을 사용하는 방법 -> 이 2가지 방법으로 ViT를 pre-training한 후에, 해당 모델을 궁극적으로 주 목적이 되는 (예) image recognition) downstream task에 fine-tuning에서 사용할 수 있음.
- ViT fine-tuning할 때에는?
- ViT의 pre-trained prediction head를 zero-initialized feedforward layer로 대체한다. ViT의 패치에서 정보를 추출하는 transformer encoder는 그대로 사용하되 뒷단의 MLP의 헤드(아웃풋 내보내는)는 풀고자하는 downstream task목적에 맞도록 다시 학습을 하기 위해 zero-initialized feedforward layer로 대체
- 이렇게 대체한 후, fine-tuning을 하면 transformer encoder자체도 다시 fine-tuning하거나, 아니면 이 부분은 freeze하고 새로 추가한 MLP의 헤드쪽만 다시 fine-tuning할 수도 있음.
- 보통 MLP의 헤드만 변경을 해서 모델을 구축한다고 볼 수 있음.
- ViT는 pre-trained와 동일한 패치 크기를 사용하기 때문에, 고해상도 이미지를 사용할때에는 동일한 패치 크기로 이미지를 나누다 보면, 패치의 개수가 결국 더 많아짐. ViT는 가변적 길이의 패치를 처리할 수는 있지만, pre-trained position embedding은 패치의 개수가 많아질수록 의미가 사라지기때문에 이를 방지하기 위해 resolution adjustment를 positional embedding부분에서 진행하는 것.
- resolution adjustment 장치: pre-trained position embedding을 원본 이미지의 위치에 따라 2D interpolation하여 사용한다.
Experimental Settings
- Pre-training: class와 이미지 개수가 다른 3개의 데이터셋을 가지고 pre-train 진행 (ImageNet-1k, ImageNet-21k, JFT)
- Benchmark: Real labels, CIFAT-10/100, Oxford-IIIT Pets, Oxford Flowers-102, 19-task VTAB classification suite 를 downstream task로 해서 pre-trained ViT의 대표 성능을 검증함
- Model Variants: 아래 표와 같은 총 3개의 volume에 대해서 실험을 진행하고, 다양한 패치 크기에 대해 실험을 진행함.
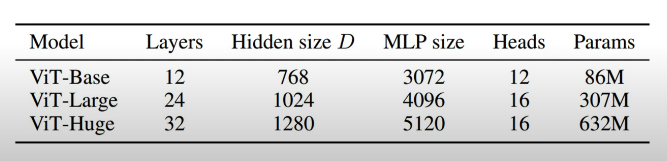
- Baseline CNN(비교용): transfer learning에 적합한 Big Transformer(BiT) 구조의 ResNet을 사용함
- batch noramlization layer를 group normalization으로 변경하고, standardized convolutional layer를 사용- 실험 결과
- ViT-Huge, 14x14 패치 크기가 16x16 패치 크기보다 더 좋았음
- pre-trained 데이터가 클수록 ViT가 BiT보다 성능이 좋고, 크기가 큰 ViT모델이 효과가 있음. 또한, 데이터가 커질수록 baseline인 CNN 보다 성능이 좋았음.
- 작은 데이터셋에서는 CNN이 inductive bias 덕분에 좋은 성능을 보여주지만 데이터가 커지면 데이터로부터 패턴을 학습하는 것만으로 충분해 ViT가 좋은 성능을 보여줌


AI (ML/DL) 학습