BERT 모델에 대한 이해
BERT(Bidirectional Encoder Representations from Transformers)는 문서 분류, 질의응답, 번역 등 다양한 NLP 작업에서 최고 성능을 내면서 널리 활용되고 있음. 이번 글에서는 BERT 모델의 특징, 구조, 그리고 작동 방식을 설명해 보겠음.
1. BERT의 특징
1.1 전이 학습(Transfer Learning) 기반 모델
- 구글의 Devlin(2018)이 제안한 BERT는 사전 학습된 비지도 학습 데이터를 기반으로 언어 모델을 학습하고, 이를 바탕으로 특정 작업(문서 분류, 질의응답 등)에 맞게 Fine-tuning을 통해 성능을 최적화하는 방식임.
- 대규모 데이터를 학습할 필요 없이 사전 학습된 모델을 활용해 빠르고 효율적으로 다양한 NLP 작업을 수행할 수 있음.
1.2 사전 학습된 모델의 장점
- 기존에는 Word2Vec, GloVe, FastText 같은 단어 임베딩 기법이 사용됐는데, BERT는 자연어 처리 분야의 다양한 실험에서 최고 성능을 기록하며 많이 쓰이고 있음.
- 사전 학습된 상태에서 제공되기 때문에 추가적인 자원 없이도 높은 성능을 낼 수 있음.
2. BERT의 구조
2.1 입력 표현 (Input Representation)
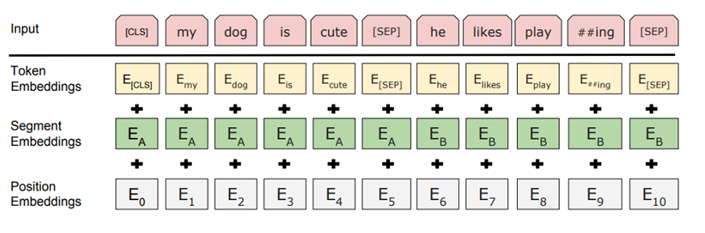
BERT의 입력은 아래와 같이 세 가지 임베딩의 합으로 구성됨:
1) Token Embeddings
- Word Piece 임베딩 방식을 사용해서 자주 등장하는 단어는 그대로, 드물게 등장하는 단어는 sub-word 단위로 분리하여 처리함.
- 모든 문장은 [CLS] 토큰으로 시작하고, 문장 구분을 위해 [SEP] 토큰을 추가함.
2) Segment Embeddings
- 문장 A와 문장 B를 구분하기 위해 A에는 0, B에는 1을 할당함.
3) Position Embeddings
- Self-Attention은 입력 순서를 고려하지 않기 때문에 위치 정보를 제공하기 위해 Position Embeddings를 사용함.
BERT 입력 예시:
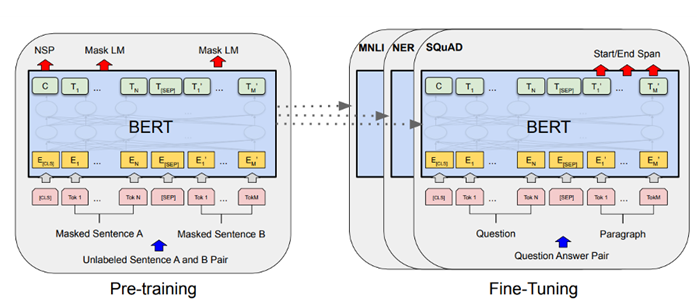
2.2 사전 학습(Pre-training)과 파인 튜닝(Fine-tuning)
BERT는 두 단계로 학습을 진행함:
1) Pre-training: 대규모 비지도 데이터로 언어 모델을 학습.
2) Fine-tuning: 특정 작업(문서 분류, 질의응답 등)에 맞춰 모델을 조정.
3. BERT의 사전 학습 방법
3.1 Masked Language Model (MLM)
- 입력 문장에서 15%의 단어를 [MASK] 토큰으로 대체하고, 이를 예측하도록 학습함.
- 이 방식은 BERT가 양방향으로 문맥을 이해하도록 돕는 핵심 요소임.
3.2 Next Sentence Prediction (NSP)
- 두 문장이 연속된 문장인지 여부를 예측하는 방식임.
- NSP를 통해 BERT는 질의응답이나 문서 분류 작업에서 뛰어난 성능을 보임.
NSP 예시:
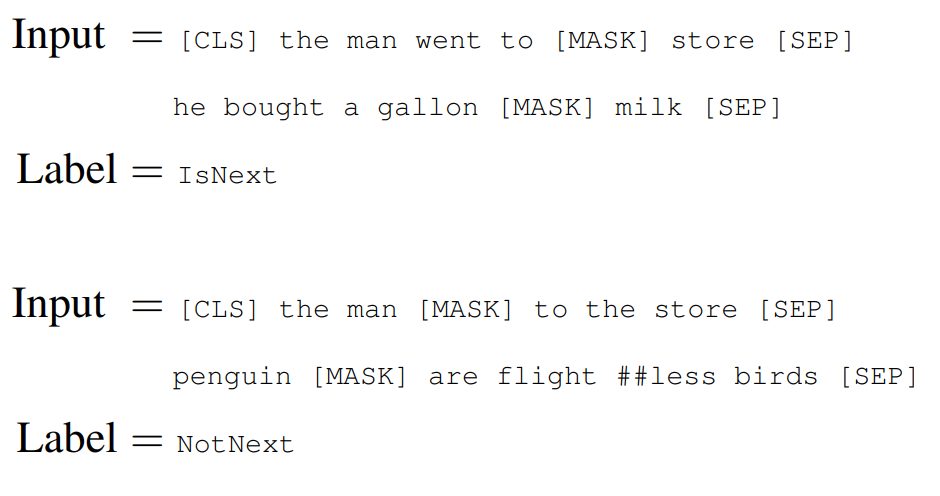
4. BERT 모델 종류
BERT 모델은 Base와 Large 두 가지 버전으로 제공됨:
| 모델 | L (Transformer 블록) | H (히든 레이어 차원) | A (Self-Attention 헤드 수) |
|---|---|---|---|
| BERT-base | 12 | 768 | 12 |
| BERT-large | 24 | 1024 | 16 |
- 대소문자를 구분하는 Cased 모델과 대소문자를 무시하는 Uncased 모델로 나뉨.
결론
BERT는 기존의 NLP 모델과 달리 양방향 학습을 통해 문맥을 깊이 이해하는 모델임. 이로 인해 다양한 자연어 처리 작업에서 최고의 성능을 자랑하며, 앞으로도 NLP 분야에서 더 활발하게 활용될 것으로 기대됨.
