1. 텍스트 요약이란?
텍스트 요약은 긴 원문을 짧고 간결하게 요약하는 작업임. 주로 추출적 요약(Extractive Summarization)과 추상적 요약(Abstractive Summarization) 두 가지 방식이 있음.
추출적 요약 (Extractive Summarization)
- 원문에서 중요한 문장이나 단어구를 추출해서 요약을 만듦.
- 원문에서 가져온 내용을 그대로 사용하기 때문에 문장 구조가 자연스럽지 않을 수 있음.
- 대표적인 알고리즘: TextRank
단점: 원문에서 선택된 문장만을 사용하기 때문에, 새로운 표현 생성이 불가능함. 중복된 정보나 긴 문장이 그대로 포함될 수 있음.
추상적 요약 (Abstractive Summarization)
- 원문에 없는 새로운 문장을 생성해서 요약을 만듦.
- 마치 사람이 핵심을 요약하는 것처럼 더 자연스럽고 유려한 문장 생성 가능.
- 주로 seq2seq 모델(Encoder-Decoder 구조)이나, 최근에는 트랜스포머 모델(BERT, BART, T5 등)을 많이 사용함.
- 지도 학습이 필요해서, '원문'과 '요약문' 쌍의 데이터셋이 필수적임.
단점: 모델 학습을 위해 방대한 데이터와 고성능 컴퓨팅 자원이 필요함. 데이터 구축에 많은 시간과 노력이 들어감.
2. 데이터 전처리 (Data Preprocessing)
데이터 로드 및 분석
- 이번 실습에서는 아마존 리뷰 데이터를 사용했음. (Kaggle 데이터 다운로드)
- 'Text' 열(원문)과 'Summary' 열(요약문)만 사용해서 분석 진행.
- 중복 샘플 제거 후, 88,425개의 샘플 확보.
import pandas as pd
data = pd.read_csv("Reviews.csv", nrows=100000)
data = data[['Text', 'Summary']]
data.drop_duplicates(subset=['Text'], inplace=True)
data.dropna(axis=0, inplace=True)
print(f'전체 샘플 수: {len(data)}')데이터 전처리 과정
- 텍스트를 소문자화하고, HTML 태그 및 특수문자 제거.
- 약어 정규화 및 불용어 제거 수행.
import re
from nltk.corpus import stopwords
from bs4 import BeautifulSoup
stop_words = set(stopwords.words('english'))
def preprocess_sentence(sentence):
sentence = sentence.lower()
sentence = BeautifulSoup(sentence, "lxml").text
sentence = re.sub(r'\([^)]*\)', '', sentence)
sentence = re.sub("[^a-zA-Z]", " ", sentence)
sentence = ' '.join(word for word in sentence.split() if word not in stop_words)
return sentence데이터 길이 분석 및 패딩
- 텍스트 최대 길이를 50, 요약문 최대 길이를 8로 설정.
- 길이 초과 샘플은 제거하여 65,818개의 샘플로 축소.
- 이후, 훈련/테스트 데이터를 8:2 비율로 분리.
from tensorflow.keras.preprocessing.sequence import pad_sequences
text_max_len = 50
summary_max_len = 8
# 패딩 처리
encoder_input = pad_sequences(encoder_input, maxlen=text_max_len, padding='post')
decoder_input = pad_sequences(decoder_input, maxlen=summary_max_len, padding='post')3. Seq2Seq + Attention 모델 설계 및 훈련
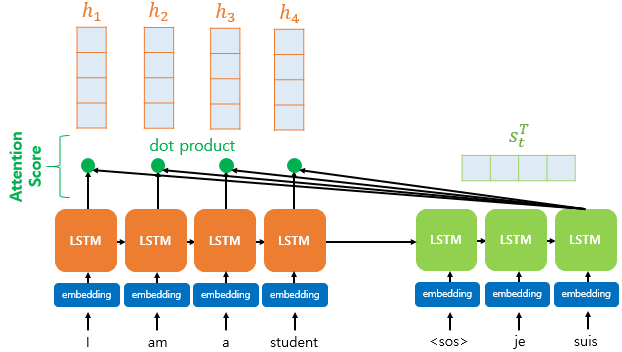
모델 설계 (Encoder-Decoder with Attention)
- 인코더는 3개의 LSTM 층을 사용해 입력 데이터를 인코딩함.
- 디코더는 LSTM과 어텐션 메커니즘을 결합해 요약문을 생성함.
from tensorflow.keras.layers import Input, LSTM, Embedding, Dense, Concatenate
from tensorflow.keras.models import Model
embedding_dim = 128
hidden_size = 256
# 인코더 정의
encoder_inputs = Input(shape=(text_max_len,))
enc_emb = Embedding(input_dim=src_vocab, output_dim=embedding_dim)(encoder_inputs)
encoder_lstm = LSTM(hidden_size, return_sequences=True, return_state=True)
encoder_outputs, state_h, state_c = encoder_lstm(enc_emb)
# 디코더 정의
decoder_inputs = Input(shape=(None,))
dec_emb = Embedding(input_dim=tar_vocab, output_dim=embedding_dim)(decoder_inputs)
decoder_lstm = LSTM(hidden_size, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(dec_emb, initial_state=[state_h, state_c])
# 어텐션 레이어 추가
from attention import AttentionLayer
attn_layer = AttentionLayer(name='attention_layer')
attn_out, attn_states = attn_layer([encoder_outputs, decoder_outputs])
decoder_concat = Concatenate()([decoder_outputs, attn_out])
decoder_softmax = Dense(tar_vocab, activation='softmax')(decoder_concat)
model = Model([encoder_inputs, decoder_inputs], decoder_softmax)
model.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy')모델 학습
- 조기 종료 조건을 설정하고 26 Epoch에서 학습 종료.
- 검증 손실이 줄어들지 않으면 자동으로 학습 중단.
from tensorflow.keras.callbacks import EarlyStopping
es = EarlyStopping(monitor='val_loss', mode='min', patience=2)
history = model.fit([encoder_input_train, decoder_input_train], decoder_target_train,
epochs=50, batch_size=256,
validation_data=([encoder_input_test, decoder_input_test], decoder_target_test),
callbacks=[es])4. 모델 평가 및 테스트
예측 결과 확인
def decode_sequence(input_seq):
e_out, e_h, e_c = encoder_model.predict(input_seq)
target_seq = np.zeros((1, 1))
target_seq[0, 0] = tar_word_to_index['sostoken']
decoded_sentence = ''
while True:
output_tokens, h, c = decoder_model.predict([target_seq, e_out, e_h, e_c])
sampled_token_index = np.argmax(output_tokens[0, -1, :])
sampled_token = tar_index_to_word[sampled_token_index]
if sampled_token == 'eostoken' or len(decoded_sentence.split()) >= (summary_max_len - 1):
break
decoded_sentence += ' ' + sampled_token
target_seq = np.zeros((1, 1))
target_seq[0, 0] = sampled_token_index
e_h, e_c = h, c
return decoded_sentence- 예시 결과:
- 원문: "great product husband eat kind price could little lower..."
- 실제 요약: "best jerky there is"
- 예측 요약: "great jerky"
5. 결론 및 향후 방향
- seq2seq와 어텐션 모델을 사용하면 사람처럼 요약할 수 있음.
- 더 나은 성능을 위해 사전 학습된 트랜스포머 모델(GPT-2, BART, T5 등) 사용을 추천.
- 향후에는 GPT-2나 T5를 활용한 텍스트 생성 모델로 테스트해볼 예정.

만나서 설명해주세여