Wav2Lip이란?
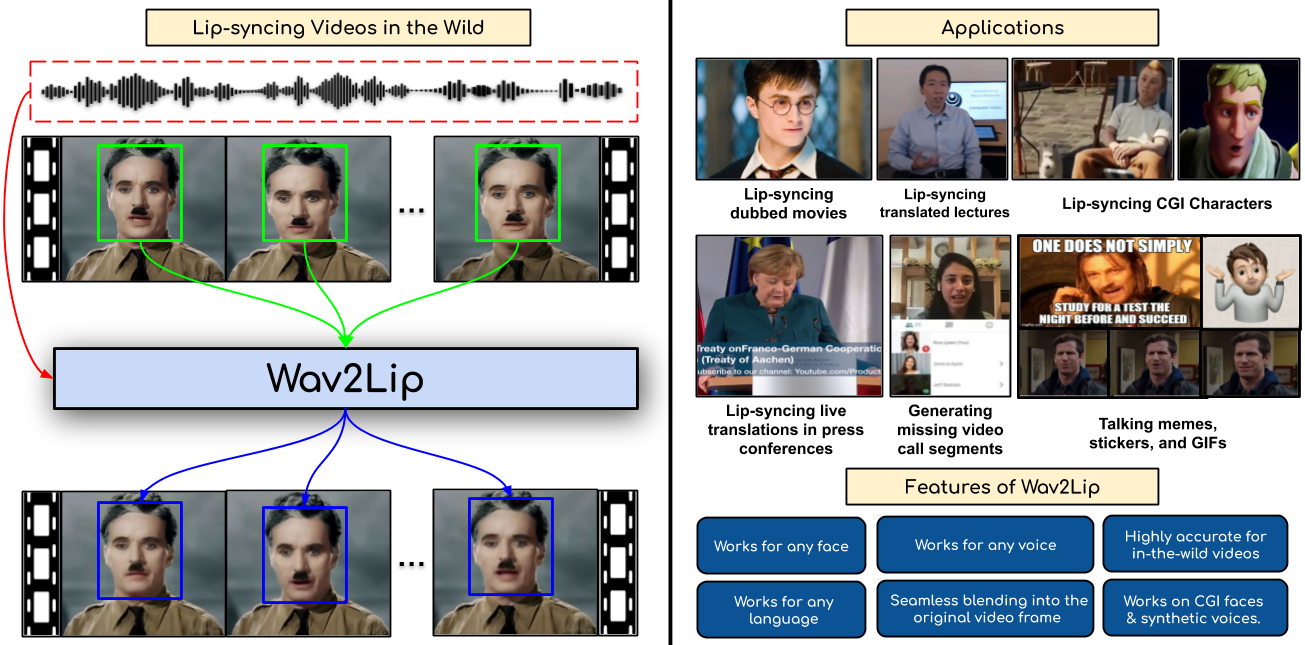
Wav2Lip은 임의의 얼굴과 음성을 정확하게 동기화하여 립싱크를 생성하는 딥러닝 모델임.
기존 립싱크 모델의 한계를 극복하고 실제처럼 자연스러운 입 모양을 만들어냄.
특히, 동적인 제약 없는(talking face) 비디오에서도 정확하게 동작하는 것이 특징임.
Wav2Lip의 주요 특징
- 모든 얼굴과 음성에서 동작: 특정 데이터셋이나 인물에 의존하지 않고 일반적인 동기화 지원.
- 높은 립싱크 정확도: 실제 비디오와 거의 구분할 수 없는 정밀한 동기화 제공.
- CGI 및 합성 음성에도 사용 가능: 애니메이션 캐릭터나 합성된 음성 데이터에도 자연스럽게 동기화 가능.
Wav2Lip 작동 방식
아키텍처
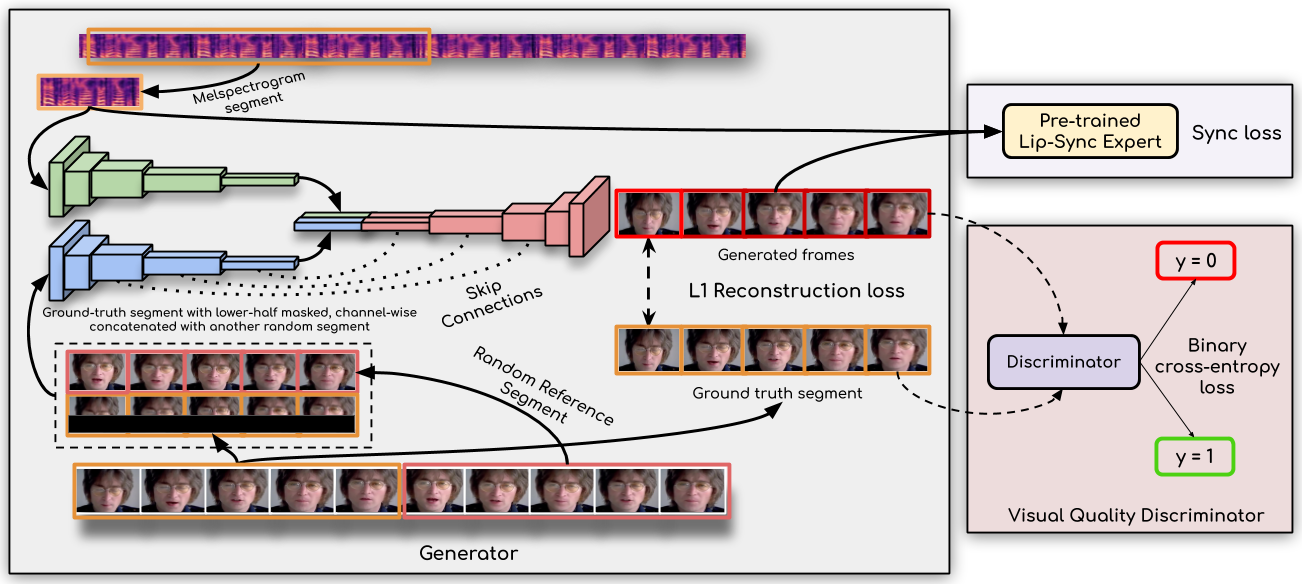
Wav2Lip의 핵심은 "이미 학습된 립싱크 전문가 모델"을 활용해 동기화를 최적화하는 것임.
우리의 접근법은 사전 훈련된 립싱크 판별기를 활용하여 정확하고 자연스러운 립싱크를 생성함.
특히, 기존 연구에서 사용한 단순 재구성 손실(reconstruction loss)이나 GAN 기반 판별기를 사용하는 방식의 한계를 극복함.
주요 구성 요소
- Speech Encoder
- 음성을 입력받아 Mel-Spectrogram으로 변환.
- Identity Encoder
- 얼굴 이미지를 인코딩하여 고유한 특징 추출.
- Face Decoder
- 얼굴 특징과 음성을 결합해 최종 립싱크 프레임 생성.
- Visual Quality Discriminator
- 시각적 품질 향상을 위해 추가된 판별기.
손실 함수
- L1 Reconstruction Loss: 프레임의 재구성 손실 최소화.
- Sync Loss: 립싱크 전문가의 피드백으로 동기화 최적화.
- Visual Quality Loss: 시각적 품질을 향상시키기 위한 추가 손실.
성능 비교
기존 모델과 비교
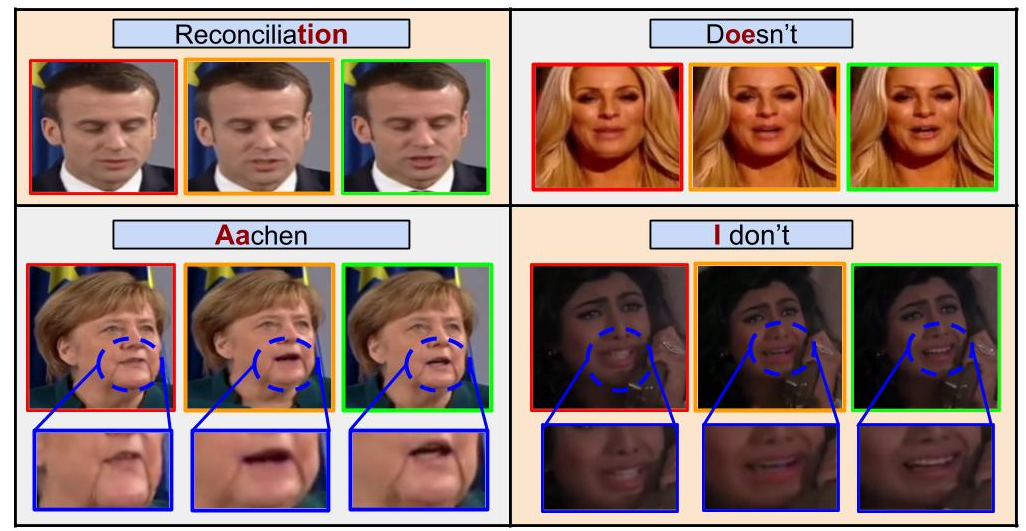
- 기존 모델(LipGAN 등): 특정 데이터셋이나 인물에서만 제대로 작동하며, 동기화 품질이 낮음.
- Wav2Lip: 더 자연스럽고 정확한 립싱크 생성. 특히, 시각적 품질에서 큰 개선을 보여줌.
실제 활용 사례
1. 영화 및 강의 더빙
- 번역된 음성을 동기화하여 더 자연스러운 시청 경험 제공.
2. CGI 애니메이션
- 캐릭터의 입 모양을 자동 생성하여 제작 시간 단축 가능.
3. 소셜 미디어 콘텐츠
- 립싱크 밈, GIF 등 개인화된 콘텐츠 제작에도 활용 가능.
Wav2Lip의 한계와 향후 과제
- 다국어 지원: 특정 도메인에 특화된 성능 향상 필요.
- 비동기화 문제: 특정 상황에서 발생할 수 있는 동기화 오류 개선 필요.
결론
Wav2Lip은 립싱크 생성 기술의 새로운 기준을 제시했으며, 다양한 응용 가능성을 보여줌.
앞으로 비디오 번역, 애니메이션 제작, 소셜 콘텐츠 등에서 중요한 역할을 할 것으로 기대됨.
