가상환경 생성
- conda create -n 폴더명 python=3.10
- conda activate 폴더명
- proceed? [y/n] y
- pip install transformers
PyTorch 웹사이트에 가서 환경에 맞는 설정을 해준뒤 설치 명령어 복붙
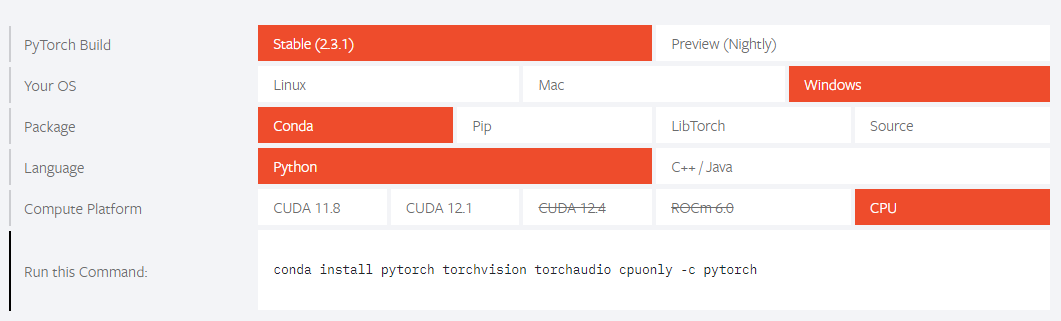
conda install pytorch torchvision torchaudio cpuonly -c pytorch
설치가 완료된 모습
Hugging Face
주 단위로 모델이 약 만 개씩 추가되고 있는 상황이고 앞으로 더욱 고도화될 것이라고 함.
AI 추론을 위한 통상적인 5가지 과정
- 패키지를 잘 설치한 뒤에 모듈 가져오기
- 추론기(객체) 생성
- 추론시킬 데이터 입력
- 추론
- 가공
실제 코드 사용 예시
# STEP 1
from transformers import pipeline
# STEP 2
classifier = pipeline("sentiment-analysis", model="stevhliu/my_awesome_model") # stevhliu가 만든 모델이다. 깃허브상 닉네임과 같은 개념. 스페이스 라고 부름. 만약 모델 제작자 정보가 누락되면 에러 발생함.
# STEP 3
# text = "This was a masterpiece. Not completely faithful to the books, but enthralling from beginning to end. Might be my favorite of the three."
text = "샤오미의 폴더블 폰의 점유율이 삼성전자 보다 높아졌다."
# STEP 4
result = classifier(text)
# STEP 5
print(result)NLP를 다룰때 항상 고민해야하는 부분
- context의 재활용성이 높은지를 항상 고민해야함.
- 자연어는 비정형화된 데이터임을 유의해야함.
예를 들어 "샤오미의 폴더블 폰의 점유율이 삼성전자 보다 높아졌다."라는 텍스트에 Text classification을 돌려보면 긍정이라는 결과를 도출함. 하지만, 삼성전자의 입장에서 부정적인 결과임.
