Kafka Broker
Kafka Broker란 단일 Kafka 서버를 말합니다. 해당 Kafka Broker는 JVM(java version 11+)에서 실행되는 프로그램이며 일반적으로 Kafka Broker 역할을 하는 서버는 필요한 프로그램만 실행하고 다른 것은 실행하지 않습니다.
Kafka Cluster
- kafka Cluster란 함께 동작하는 Kafka Broker의 앙상블을 말합니다.
- 일부 Cluster에는 Broker가 하나만 포함될 수 있고, 다른 Cluster에는 3개 또는 수백 개의 Broker가 포함될 수도 있습니다.
- Neflix 및 Uber와 같은 회사는 데이터를 처리하기 위해 수백 또는 수천 개의 Kafka Broker를 운영한다고 합니다.
- Cluster의 Broker는
고유한 숫자ID로 식별됩니다. 아래 그림처럼 Kafka Cluster는
세 개의 Kafka Broker로 구성됩니다.

Kafka Broker && Topic
- Kafka Broker는 실행되는 서버 디스크의 디렉터리에 데이터를 저장합니다. 각 Topic 파티션은 주제와 관련된 이름이 포함된 자체 하위 디렉터리를 받습니다. Kafka가 데이터를 Kafka Topic 내부에 저장할때 방식은 추후 작성하도록 하겠습니다.
- Topic에 대한 높은 처리량과 확장성을 달성하기 위해 Kafka Topic은 분할됩니다. Cluster에 Kafka Broker가 여러 개 있는 경우 특정 Topic에 대한 파티션이 Broker간에 균등하게 분산되어 로드 밸런싱 및 확정성을 달성합니다.
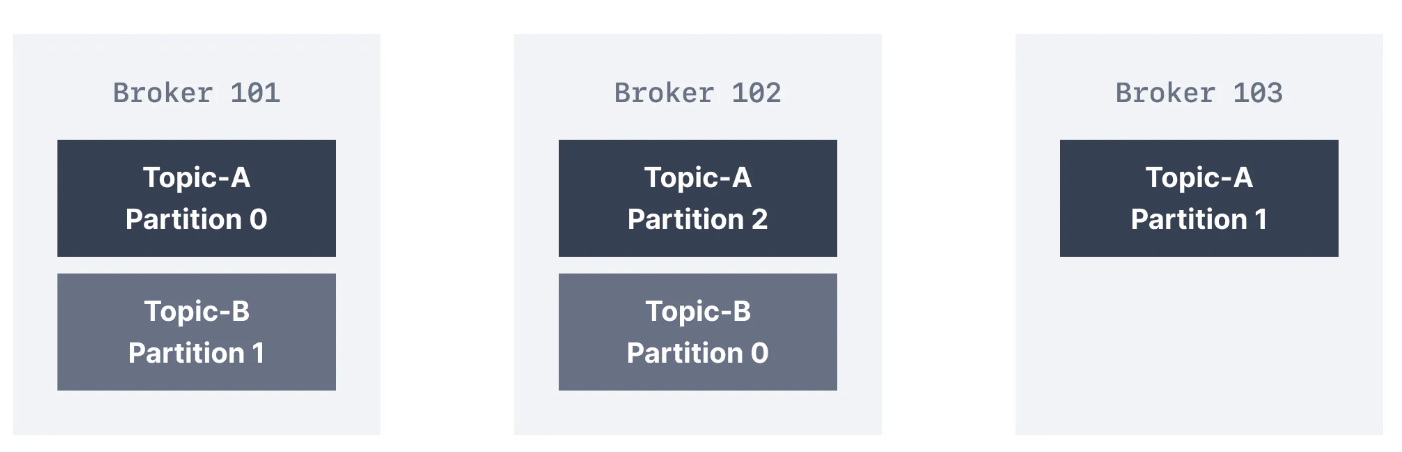
- Broker ID와 Partition ID 사이에는 아무런 관계가 없습니다. Kafka는 사용 가능한 Broker 간에 파티션을 균등하게 배포하는 작업을 잘 수행합니다. 특정 Broker의 과부하로 인해 Cluster의 불균형이 발생하는 경우 Kafka 관리자는 Cluster의 균형을 재조정하고 파티션을 이동할 수 있습니다.
- Topic이 복제될 때 Kafka Broker에 파티션이 배치되는 방법은 Kafka Topic Replication을 참고해주세요
클라이언트는 Kafka Cluster(Bootstrap Server)에 어떻게 연결하는가?
- Kafka Cluster에서 메시지를 보내거나 받으려는 클라이언트는 Cluster의 모든 Broker에 연결할 수 있습니다. Cluster의 모든 Broker에는 다른 모든 Broker에 대한 메타데이터가 있으며 클라이언트가 해당 Broker에 연결하는데에도 도움이 됩니다. 따라서 Cluster의 모든 Broker를 Bootstrap server라고도 합니다.
- Bootstrap Server는 Cluster의 모든 Broker 목록으로 구성된 메타데이터를 클라이언트에 반환합니다. 그런 다음 필요한 경우 클라이언트는 데이터를 보내거나 받기 위해 연결할 정확한 브로커를 파악하고 관련 Topic 파티션이 포함된 Broker를 정확하게 찾습니다.
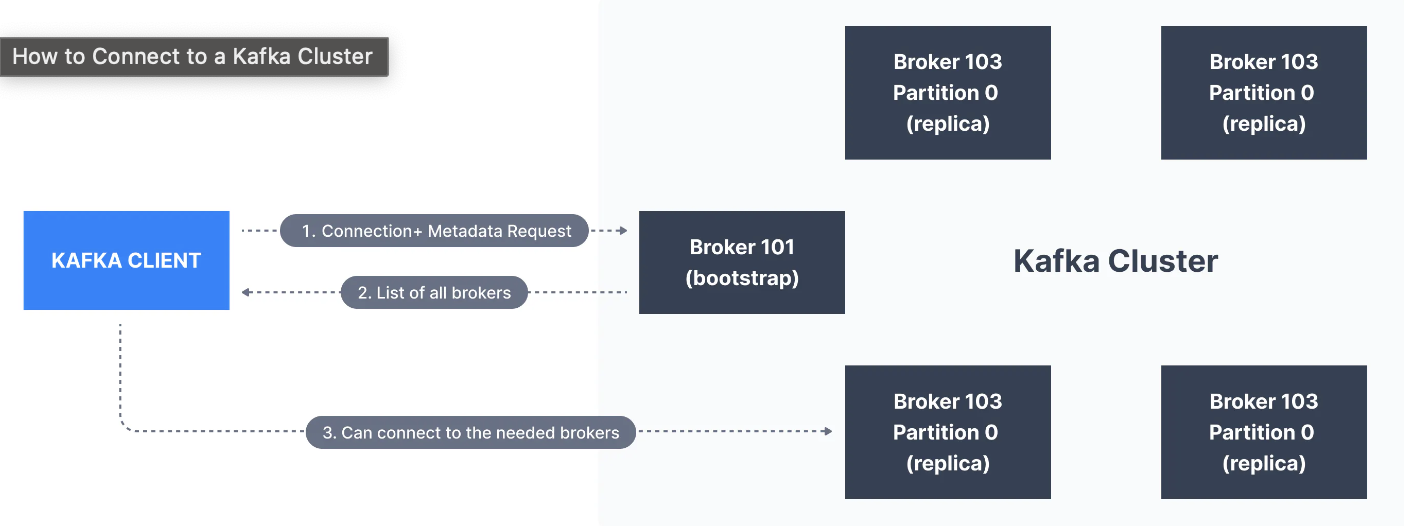
- 실제로 Kafka 클라이언트는 연결 URL에서 두 개 이상의 Bootstrap Server를 참조하는 것이 일반적입니다. 그 중 하나를 사용할 수 없는 경우 다른 하나는 여전히 연결 요청에 응답해야 합니다. 이는 Kafka 클라이언트(Developers or DevOps)가 Kafka 클러스터의 모든 단일 Broker의 모든 단일 호스트 이름을 알 필요가 없고 클라이언트에게 필요한 것은 URL 두 개 또는 세 개를 인식하라고 참조하면 된다는 것을 의미합니다.

문제 해결과 개선 과제를 수행하며 성장을 추구하는 것을 좋아합니다.