Kafka Consumer는 Kafka Topic의 파티션의 데이터를 개별적으로 사용할 수 있지만 수평 확장성을 위해서는 Kafka Topic을 그룹으로 사용하는 것이 좋습니다.
Kafka Consumer Groups
-
Consumers는 동일한 애플리케이션의 일부이므로 동일한 “논리적 작업”을 수행하는 Consumer는 Kafka Consumer Group으로 그룹화될 수 있습니다.
-
Topic은 일반적으로 여러 파티션으루 구성됩니다. 이러한 파티션은 Kafka Consumer를 위한 병렬 처리 단위입니다.
-
Kafka Consumer Goup을 활용하면 Group내의 Consumer가 서로 다른 파티션에서 읽기 작업을 분할하기 위해 조정된다는이점이 있습니다.
Kafka Consumer Group ID
-
Kafka Consumer에게 동일한 특정 그룹임을 나타내려면
group.id를 이용해 Consumer측 설정을 지정해야 합니다. -
Kafka Consumer는 자동으로
GoupCoordinator및ConsumerCoordinator를 사용하여 Consumer를 파티션에 할당하고 동일한 그룹의 모든 Consumer 간에 로드 밸런싱이 이뤄지도록 합니다. -
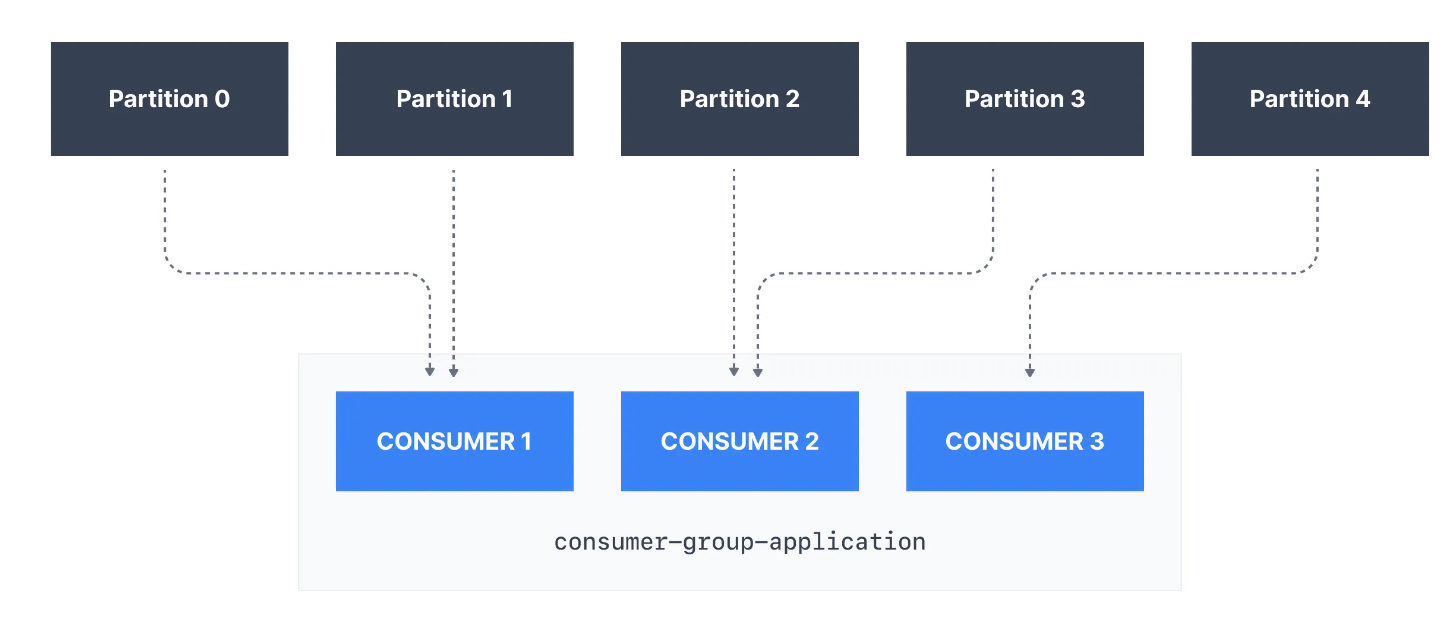
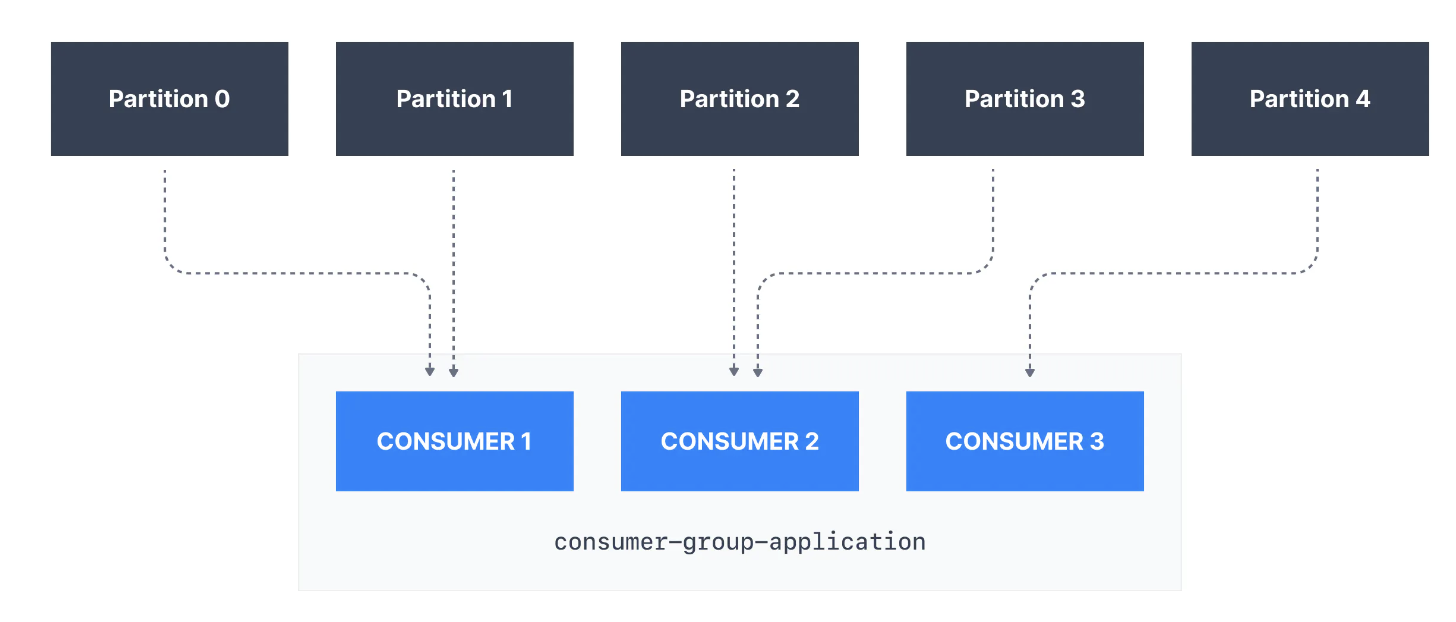
각 Topic 파티션은 Consumer Group 내의 소비자 한 명에게만 할당되지만 Consumer Group의 Consumer는 여러 파티션에 할당될 수 있는 점에 유의하는 것이 중요합니다.
- 즉, Partition은
Consumer Group내 하나의 Consumer에게만 할당되지만, Consumer는 하나 이상의 partition을 할당 받을 수 있다는 것입니다.
- 즉, Partition은
-
위 사진을 보면 Consumer group(consumer-group-application-1)의 Consumer1 에는 Partittion 0과 Partition 1이 할당되고, Consumer2에는 Partition2, Partition3이 할당되며, 마지막 Consumer3에는 Partition4가 할당됩니다.
-
Kafka Topic에서 데이터를 읽는 각 애플리케이션은 서로 다른
group.id가 명시되어야 합니다.
이는 여러 애플리케이션(Consumer Group)이 동시에 동일한 Topic을 사용할 수 있음을 의미합니다. (아래 그림 참고)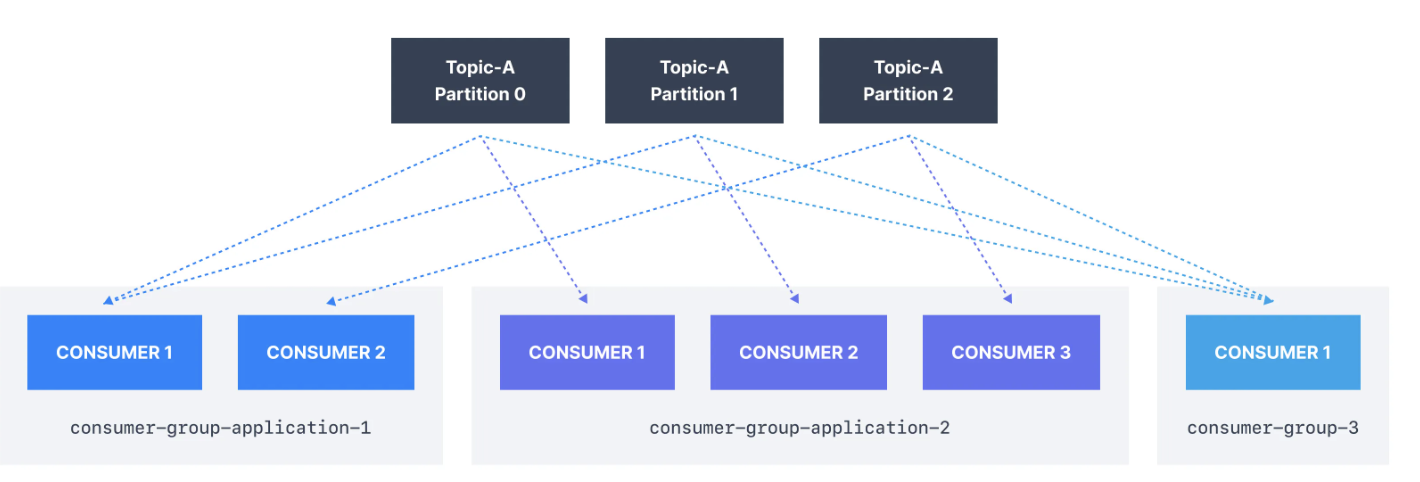
-
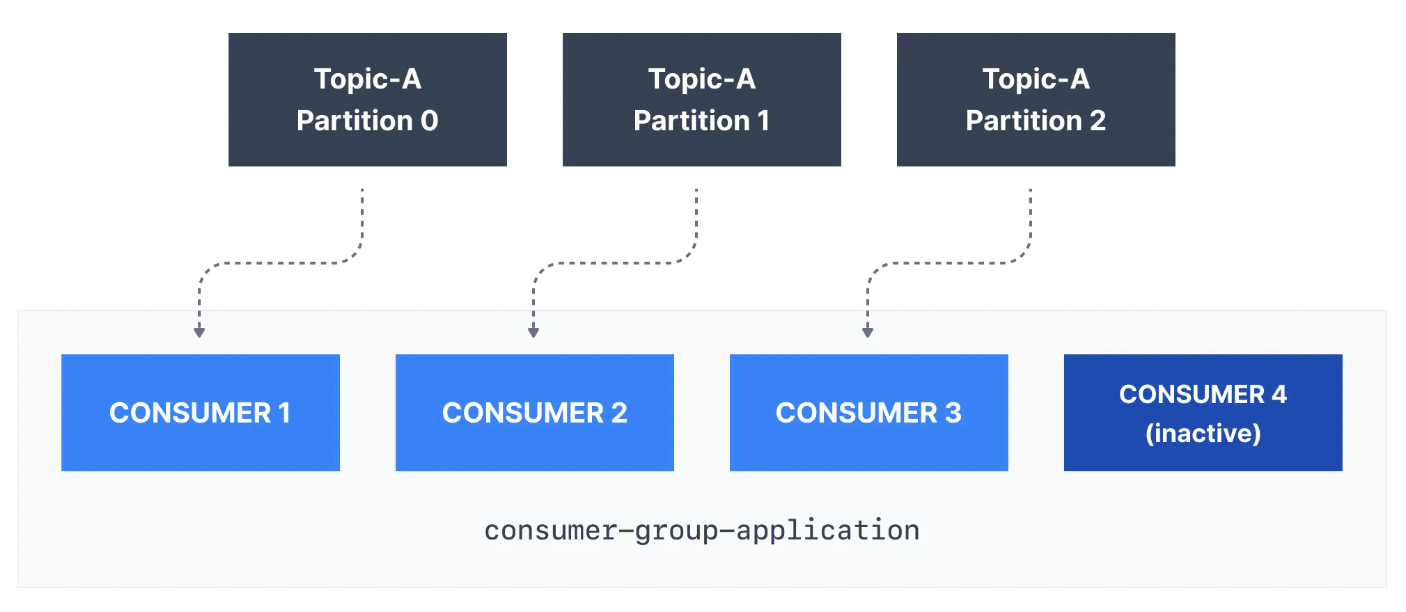
만약 Topic의 파티션 수보다 Consumer가 더 많은 경우 아래와 같이 일부 Consumer가 비활성 상태로 유지됩니다.
-
일반적으로 Consumer Group에는 파티션 수만큼 Consumer가 있습니다. 더 높은 처리량을 위해 더 많은 소비자를 원할 경우 Topic을 생성하는 동안 더 많은 파티션을 생성해야 합니다. 그렇지 않으면 일부 Consumer는 비활성 상태로 유지될 수 있습니다.
Kafka Consumer Offsets
-
Kafka 브로커들은 특정 Consumer Group이 마지막으로 성공적으로 처리한 메시지를 추적하는 내부 Topic인
__consumer_offsets를 사용합니다. -
Kafka Topic의 각 메시지는 Partition ID와 연결된 Offset ID가 있습니다.
-
따라서 Consumer가 Topic Partition으로 얼마나 읽어들였는지
"체크포인트"하기 위해, Consumer는 정기적으로 최근에 처리한 메시지, 즉Consumer Offset이라고도 불리는 것을Commit합니다. -
아래 그림에서 Consumer Group의 Consumer는 Offset 4262까지의 메시지를 소비했으므로, Consumer Offset은 4262로 설정됩니다.
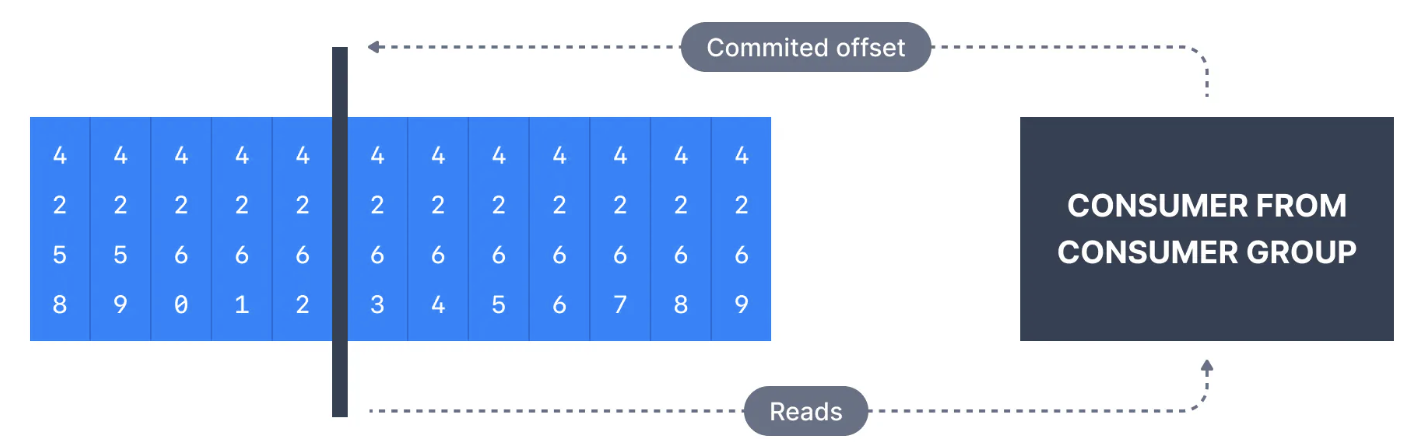
-
대부분의 클라이언트 라이브러리는 주기적으로 Offset을 Kafka에 자동으로 커밋하며, 책임 있는 Kafka 브로커는
__consumer_offsetsTopic에 쓰기를 보장합니다.(따라서 Consumer는 직접 해당 Topic에 쓰지 작업을 하지 않습니다.) -
Offset을 커밋하는 프로세스는 모든 메시지를 소비할 때마다 수행되지 않습니다. (이렇게 하면 비효율적이기 때문입니다.)
대신 주기적인 프로세스를 이용합니다. -
이는 특정 Offset이 커밋될 때 해당 Offset보다 낮은 Offset을 갖는 이전 모든 메시지도 커밋된 것으로 간주된다는 것을 의미합니다.
Consumer Offset을 사용하는 이유는 무엇인가?
- Offset은 많은 응용 프로그램에서 중요합니다. Kafka 클라이언트가 충돌하면 rebalance가 발생하고, 최신으로 커밋된 Offset은 남아있는 Kafka Consumers가 메시지를 어디서 다시 읽고 처리할지 알 수 있도록 도와줍니다.
- 새로운 Consumer가 Group에 추가되면 다른 Consumer Group rebalance가 발생하고 다시 한 번 Consumer Offset이 사용되어 Consumer에게 데이터를 어디서부터 읽기 시작해야 하는지 알립니다.
- 따라서 Consumer Offset은 정기적으로 커밋되어야 합니다.
Consumer를 위한 전달 의미론(Delivery Semantics)
- 기본적으로 Java Consumer는
.poll()이 호출될 때마다(enable.auto.commit=true)auto.commit.interval.ms(default: 5s)offset을 자동으로 커밋합니다. - Delivery Semantics for Consumers 매커니즘의 자세한 설명은 추후 작성하도록 하겠습니다.
- Consumer는 Offset을 자체적으로 커밋할 수 있습니다.
(enable.auto.commit=false)Offset을 언제 커밋하려고 하는지에 따라 Consumer에게 제공되는전달 의미론(Delivery Semantics)이 있습니다.
At most Once
- Offset은 메시지가 수신되는 즉시 커밋됩니다.
- 처리가 잘못되면 메시지가 손실됩니다.(다시 읽을 수 없음)
At least Once(일반적으로 선호됨)
- 메시지가 처리된 후에 Offset이 커밋됩니다.
- 처리가 잘못되면 메시지를 다시 읽습니다.
- 이로 인해 메시지의 중복 처리가 발생할 수 있습니다. 따라서 데이터 처리가 멱등성을 갖도록 하는 것이 가장 좋습니다.
Exactly Once
- 이것은 트랜잭션 API를 사용하여 Kafka Topic 간 워크플로에서만 가능합니다. Kafka Streams API는 해당 API를 간소화하고
processing.guarantee=exactly_once_v2설정을 사용하여 정확히 한 번을 가능하게 합니다. (kafka 2.5 버전 하위에서는 exactly_once 값 사용) - Kafka Topic에서 외부 시스템 워크플로를 사용할 경우 정확히 한 번을 효과적으로 달성하려면 멱등한 Consumer를 사용해야 합니다.
실제로는 At most Once(최소 한 번)의 멱등한 처리가 Kafka Consumer를 위한 가장 바람직하고 널리 구현된 메커니즘입니다.
