'24년 10월 8일, BigQuery가 사용하는 GoogleSQL 언어에 Pipe Syntax(파이프 문법)가 Preview로 추가되었습니다.
이번 글에서는 파이프 문법이 기존 SQL 언어의 사용성을 어떻게 개선할 수 있을지를 살펴보고자 합니다.
개요
SQL은 70년내 초반 개발되어 50여년이 지난 지금 데이터를 다루는 사실상의 표준 언어로서 성공적으로 자리매김하였으나, 오래된 언어로 사용자가 배우기 어렵고 확장성이 떨어진다는 시각도 있다.
Google은 연구 논문[1]에서 파이프 문법이 이런 단점들을 해결하고 SQL을 유연하고 배우기 쉬운 확장성을 가지는 언어로 만들 수 있다고 얘기하고 있다.
논문은 전통적인 SQL 에서의 가장 큰 문제로 ① 문장을 구성하는 표준 절(clause)들이 엄격하게 정의된 순서에 따라 기술되어야 하고, ② 이를 벗어나는 경우 별도 서브쿼리나 우회방안을 적용해야 하며, ③ 복잡한 쿼리의 경우 inside-out 데이터 흐름으로 인해 논리적인 해석 순서와 문법적 해석 순서가 다름을 지적하고 있다.[Figure 1].
반면 파이프 문법에서는 관계형 연산들을 임의의 순서로 조합하여 문장 구성이 가능한데 이는 사용자 경험을 단순화시키고 클린 코드 작성이 가능하다고 말한다.[Figure 2].
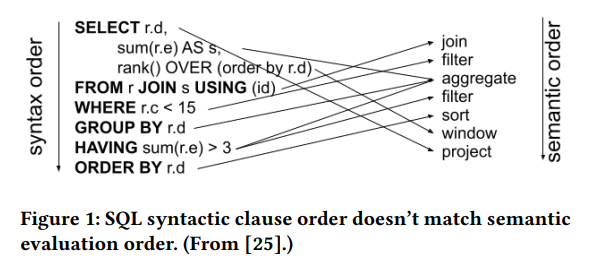

*그림출처 - SQL Has Problems. We Can Fix Them: Pipe Syntax In SQL
TPC-H benchmark 쿼리를 통해 파이프 문법의 개괄적인 구조를 먼저 살펴보자. 먼저 표준 문법을 사용하여 작성된 쿼리는 다음과 같다.
-- Standard Syntax
SELECT c_count, COUNT(*) AS custdist
FROM (
SELECT c_custkey, COUNT(o_orderkey) c_count
FROM customer
LEFT OUTER JOIN orders ON c_custkey = o_custkey
AND o_comment NOT LIKE '%unusual%packages%'
GROUP BY c_custkey
) AS c_orders
GROUP BY c_count
ORDER BY custdist DESC, c_count DESC;표준 SQL 에서 다중 집계(multi-level aggregation)의 경우 서브쿼리 사용이 불가피하여 결과적으로 inside-out* 데이터 흐름을 갖는 복잡한 쿼리가 만들어진다.
(*가장 안쪽 서브쿼리부터 시작하여 바깥쪽 메인쿼리의 순서로 쿼리 구문 해석)
반면에, 파이프 문법에서는 아래와 같이 관계형 연산자를 top-to-bottom 방향으로 순차적으로 적용하여 동일한 결과를 만들어 낼 수 있다.
-- Pipe Syntax
FROM customer
|> LEFT OUTER JOIN orders ON c_custkey = o_custkey
AND o_comment NOT LIKE '%unusual%packages%'
|> AGGREGATE COUNT(o_orderkey) c_count
GROUP BY c_custkey
|> AGGREGATE COUNT(*) AS custdist
GROUP BY c_count
|> ORDER BY custdist DESC, c_count DESC;[Notes] 가독성이 좋으며 데이터 탐색 과정에서 중간 결과를 확인해가며 전체 문장을 단계별로 빌드업 해나가는데 유용한 문법으로 보이나, 선형적인 구조외에 좀 더 복잡한 구조의 문장을 파이프 문법 단독으로 구성하기는 어려워서 결국 기존 표준 문법과 같이 혼용되어 사용될 것으로 보인다.
이어서 파이프 문법들을 하나씩 구체적으로 살펴보도록 하겠다.
파이프 문법
파이프 문법이 가지는 특징을 나열하면 아래와 같다.[3]
- 파이프 문법에서 각 파이프 연산자는
|>기호와 연산자 이름 그리고 인자(argument)들로 구성됩니다. - 파이프 연산자는 유효한 쿼리의 끝에 연결할 수 있다.
- 파이프 연산자는 순서와 횟수에 상관없이 적용될 수 있다.
- 파이프 문법은 표준 문법이 지원되는 모든 곳에서 동작한다.(쿼리, View, TVF(Table-Valued Function) 및 다른 문맥)
- 파이프 문법은 하나의 쿼리 내에서 표준 문법과 섞일 수 있다. 예를 들어, 서브쿼리는 부모쿼리와는 다른 문법을 사용할 수 있다.
- 쿼리가
FROM절로부터 시작할 수 있다. 그리고 파이프 연산자들을 추가적으로FROM절에 이어나갈 수 있다.
[Notes] 순서와 상관없이 파이프 연산자 적용이 가능하다는 설명의 예시를 보면WHERE 파이프 연산자의 위치가 자유로운 듯 보이나 엄밀하게는 왼쪽 WHERE 파이프 연산자는 표준 문법에서 집계 결과에 대해 필터링을 수행하는 HAVING 절의 역할이고, 오른쪽은 베이스 테이블 필터링을 위한 WHERE 절에 대응된다. 따라서, 2개 문장이 결과적으로 동일한 결과를 만들어 내기는 하지만 (쿼리 실행계획도 최적화에 의해서 동일하게 만들어질 수 있다.) 기본적으로는 다른 문장이기 때문에 파이프 연산자의 위치를 지정할 때 주의를 요한다.

[출처] Youtube - Introducing pipe syntax in BigQuery and Cloud Logging
Hello, Pipe Syntax
실제 예시를 통해 파이프 문법의 구조와 활용 방법을 살펴보자(*구글 공식 문서[2]의 예시 차용). 우선 예시에 사용할 임시 테이블을 아래와 같이 정의한다.
-- *produce* 임시 테이블 생성
CREATE TEMP TABLE produce AS
SELECT 'apples' AS item, 2 AS sales, 'fruit' AS category UNION ALL
SELECT 'apples' AS item, 7 AS sales, 'fruit' AS category UNION ALL
SELECT 'carrots' AS item, 0 AS sales, 'vegetable' AS category UNION ALL
SELECT 'bananas' AS item, 15 AS sales, 'fruit' AS category;
+---------+-------+-----------+
| item | sales | category |
+---------+-------+-----------+
| apples | 7 | fruit |
| apples | 2 | fruit |
| bananas | 15 | fruit |
| carrots | 0 | vegetable |
+---------+-------+-----------+표준 문법에서 produce 테이블을 조회하기 위해서 SELECT로 시작하는 문장(statement)을 수행한다. 이 경우 FROM절이 먼저 해석되고 다음 SELECT절(clause)이 해석되면서 문장이 기술되는 순서와 해석되는 순서가 달라지게 된다.
반면, 파이프 문법에서는FROM 절부터 시작되기 때문 문장이 해석되는 순서와 자연스럽게 일치한다.
-- Standard Syntax
SELECT * FROM `produce`;
-- Pipe Syntax
FROM `produce`;
-- Query Result
+---------+-------+-----------+
| item | sales | category |
+---------+-------+-----------+
| apples | 7 | fruit |
| apples | 2 | fruit |
| bananas | 15 | fruit |
| carrots | 0 | vegetable |
+---------+-------+-----------+파이프 문법에서 쿼리는 FROM 절 외에도 테이블을 생성하는 다른 구문으로 시작 가능하다. 여기에는 서브쿼리, 테이블 JOIN, UNNEST, TVF(Table-Valued Function) 등이 모두 포함된다.
-- 서브쿼리로 부터 시작되는 파이프 문법 예시
(
SELECT 'apples' AS item, 2 AS sales UNION ALL
SELECT 'bananas' AS item, 5 AS sales UNION ALL
SELECT 'carrots' AS item, 8 AS sales
)
|> WHERE sales >= 3;
-- 테이블 조인으로부터 시작하는 예시
FROM produce AS p1 JOIN produce AS p2 USING (item)
|> WHERE item = "bananas"
|> SELECT p1.item, p2.sales;Selection (필터링)
다음으로 필터링 조건을 추가해 보자. 표준 문법의 WHERE 절에 대응하는 파이프 연산자는 |> 심볼과 WHERE 키워드가 합쳐진 |> WHERE이다. 이를 FROM 절 다음에 추가하면 다음과 같다.
FROM `produce`
|> WHERE sales > 0;
-- query result
+---------+-------+----------+
| item | sales | category |
+---------+-------+----------+
| apples | 2 | fruit |
| apples | 7 | fruit |
| bananas | 15 | fruit |
+---------+-------+----------+표준문법에서는 하나의 SELECT 문 안에서 3단계까지의 필터링이 이루어질 수 있다.
1. WHERE - 베이스 테이블 (Base Table) 에 대한 필터링
2. HAVING - GROUP BY 집계 결과를 대상으로 필터링
3. QUALIFY - Window 함수 적용 이후의 결과를 대상으로 필터링
이와 같이 각 단계별로 필터링을 위한 키워드가 다르지만, 파이프 문법에서는 모두 WHERE 연산자로 통일되어 있다. 이는 집계 결과 혹은 분석(Window 함수를 이용한) 결과를 서브쿼리로 만든 후 바깥 쿼리에서 WHERE 절로 필터링하는 것으로 생각해도 무방하다.
-- Window 함수 수행 결과를 바탕으로 필터링하는 예시
(
SELECT 'apples' AS item, 2 AS sales UNION ALL
SELECT 'bananas' AS item, 5 AS sales UNION ALL
SELECT 'carrots' AS item, 8 AS sales
)
|> WINDOW SUM(sales) OVER() AS total_sales
|> WHERE sales >= 5;Projection (컬럼 선택)
관계형 연산의 Projection(사영) 은 SELECT 절에서 테이블 속성(컬럼)들 중 일부인 부분집합을 취하는 연산으로 파이프 문법에서는 주로 문장의 마지막 연산자로 사용하게 된다. SELECT 파이프 연산자는 선택적으로 사용 가능하며 생략시 표준 문법의 SELECT * FROM ...과 동일한 의미를 가진다.
연산자내에서 계산된 컬럼 (Calculated Column)이나 Window 함수를 추가할 수 있으나 다만 집계(Aggregation) 함수를 사용할 수 없다. 집계는 별도 AGGREGATE 연산자내에서 수행된다.
더불어, 컬럼을 재배열하기 위한 추가적인 연산자들도 제공된다.
EXTEND-SELECT *, calculated_columnSET-SELECT * REPLACE(new_val AS col1)DROP-SELECT * EXCEPT(col1, col2, ...)RENAME-SELECT * EXCEPT (col1), col1 AS new_col
-- SELECT 연산자
FROM (SELECT 'apples' AS item, 2 AS sales)
|> SELECT item AS fruit_name;
-- EXTEND 연산자
(
SELECT 'apples' AS item, 2 AS sales UNION ALL
SELECT 'carrots' AS item, 8 AS sales
)
|> EXTEND item IN ('carrots', 'oranges') AS is_orange;
/*---------+-------+------------+
| item | sales | is_orange |
+---------+-------+------------+
| apples | 2 | FALSE |
| carrots | 8 | TRUE |
+---------+-------+------------*/
-- Window function, with `OVER`
(
SELECT 'apples' AS item, 2 AS sales UNION ALL
SELECT 'bananas' AS item, 5 AS sales UNION ALL
SELECT 'carrots' AS item, 8 AS sales
)
|> EXTEND SUM(sales) OVER() AS total_sales;
/*---------+-------+-------------+
| item | sales | total_sales |
+---------+-------+-------------+
| apples | 2 | 15 |
| bananas | 5 | 15 |
| carrots | 8 | 15 |
+---------+-------+-------------*/
-- RENAME
SELECT 1 AS x, 2 AS y, 3 AS z
|> AS t
|> RENAME y AS renamed_y
|> SELECT *, t.y AS t_y;
/*---+-----------+---+-----+
| x | renamed_y | z | t_y |
+---+-----------+---+-----+
| 1 | 2 | 3 | 2 |
+---+-----------+---+-----*/표준문법과 비교했을 때 EXTEND 연산자는 클린 코드를 만들어 가독성을 높이는데 활용가능하다. 예를 들어, 표준 문법에서는 동일 SELECT 절에서 정의된 별칭(alias)를 참조하지 못하기 때문에 반복이 생기는 경우가 있는데 PIPE 연산자를 사용하는 경우 컬럼 별칭을 통해 반복을 줄여 가독성을 높여준다.
-- Standard Syntax
SELECT student,
(score1 + score2) / 2 AS average_score,
(score1 + score2) / 2 / points_possible AS average_percent
FROM mydataset.scores;
-- Pipe Syntax
FROM mydataset.scores
|> EXTEND (score1 + score2) / 2 AS average_score
|> EXTEND average_score / points_possible AS average_percent
|> SELECT student, average_score, average_percent;Aggregation (집계)
집계(aggregation) 연산을 위해서는 AGGREGATE 연산자를 필요로 하며 집계함수와 GROUP BY 절이 연산자 다음에 이어 등장한다.
FROM `produce`
|> AGGREGATE SUM(sales) AS total, COUNT(*) AS num_records
GROUP BY item, category;
/*---------+-----------+-------+-------------+
| item | category | total | num_records |
+---------+-----------+-------+-------------+
| apples | fruit | 9 | 2 |
| carrots | vegetable | 0 | 1 |
| bananas | fruit | 15 | 1 |
+---------+-----------+-------+-------------*/ 집계 결과를 확인하기 위해서 정렬을 자주 사용하는데 파이프 문법에서는 별도 연산자를 추가하지 않고 AGGREGATE 연산자내에서 정렬 방식을 같이 지정 가능하다.
-- 별도 ORDER BY 연산자 사용
FROM mydataset.produce
|> AGGREGATE SUM(sales) AS total, COUNT(*) AS num_records
GROUP BY category, item
|> ORDER BY category DESC, item;
-- `GROUP BY` 내에서 정렬 순서 지정
FROM mydataset.produce
|> AGGREGATE SUM(sales) AS total, COUNT(*) AS num_records
GROUP BY category DESC, item ASC;
-- `GROUP AND ORDER BY` 사용
FROM mydataset.produce
|> AGGREGATE SUM(sales) AS total, COUNT(*) AS num_records
GROUP AND ORDER BY category DESC, item;Join
테이블간 Join 연산을 위해서 예시 테이블을 하나 더 생성하겠습니다.
CREATE TEMP TABLE item_data AS
SELECT "apples" AS item, "123" AS id
UNION ALL
SELECT "bananas" AS item, "456" AS id
UNION ALL
SELECT "carrots" AS item, "789" AS id;JOIN 파이프 연산자를 이용하여 JOIN 연산을 수행하는 파이프 문법의 쿼리는 다음과 같습니다.
-- Pipe Syntax
FROM produce
|> WHERE sales > 0
|> AGGREGATE SUM(sales) AS total_sales, COUNT(*) AS num_sales
GROUP BY item
|> JOIN item_data USING (item);
-- Standard Syntax
SELECT * FROM (
SELECT item, SUM(sales) AS total_sales, COUNT(1) AS num_sales
FROM produce
WHERE sales > 0
GROUP BY item
) JOIN item_data USING (item);베이스 테이블이 아닌 서브쿼리와 JOIN시 양쪽 테이블의 동일한 컬럼 이름으로 인한 모호함을 없애기 위해 별칭(alias)이 필요할 수 있는데 이를 위해 파이프 문법에서는 AS 연산자를 제공한다.
-- 서브쿼리에 별칭을 부여하여 JOIN 시 참조
(
SELECT 'apples' AS item, 2 AS sales UNION ALL
SELECT 'bananas' AS item, 5 AS sales
)
|> AS produce_sales
|> LEFT JOIN (
SELECT "apples" AS item, 123 AS id
) AS produce_data
ON produce_sales.item = produce_data.item
|> SELECT produce_sales.item, sales, id;주의할 점은 JOIN 연산시 오른쪽 테이블은 왼쪽 테이블에 대한 가시성(Visibility)를 가지지 못하기 때문에 셀프 조인이 불가능하다. (역주 - 테이블 별칭에 대한 가시성으로 인함)
-- This query doesn't work.
FROM `mydataset.produce`
|> AS produce_table
|> JOIN produce_table AS produce_table_2 USING(item);변경된 테이블에 대한 셀프 조인의 경우는 CTE(Common Table Expression) 구문을 사용하여 우회할 수 있다.
WITH cte_table AS (
FROM `mydataset.produce`
|> WHERE item = "carrots"
)
FROM cte_table
|> JOIN cte_table AS cte_table_2 USING(item);WINDOW 연산자
Window 함수를 사용하는 분석 쿼리의 경우는 WINDOW 연산자를 사용하거나 EXTEND 를 사용할 수 있다.
(
SELECT 'apples' AS item, 2 AS sales UNION ALL
SELECT 'bananas' AS item, 5 AS sales UNION ALL
SELECT 'carrots' AS item, 8 AS sales
)
|> WINDOW SUM(sales) OVER() AS total_sales;파이프 연산자 문맥 (Pipe operator semantics)
지금까지 살펴본 파이프 연산자는 아래의 의미적 행동을 보인다.
- 각 파이프 연산자는 자족(self-contained)적인 연산을 수행합니다.
- 파이프 연산자는 파이프 기호(
|>)를 통해 전달된 입력 테이블을 사용하여 하나의 새로운 결과 테이블을 생산합니다.
(역자 주. 파이프 기호 직전의 테이블을 입력 받아 새로운 테이블을 출력) - 파이프 연산자는 직전의 입력 테이블의 컬럼들만을 참조할 수 있다. 동일 쿼리 내 앞선 테이블의 컬럼은 보여지지 않는다. 서브쿼리내에서 바깥 컬럼과의 상관 참조는 허용된다. ([To-Do] 컬럼/테이블 이름 혹은 별칭의 Naming Scope 정리)
기타 파이프 연산자
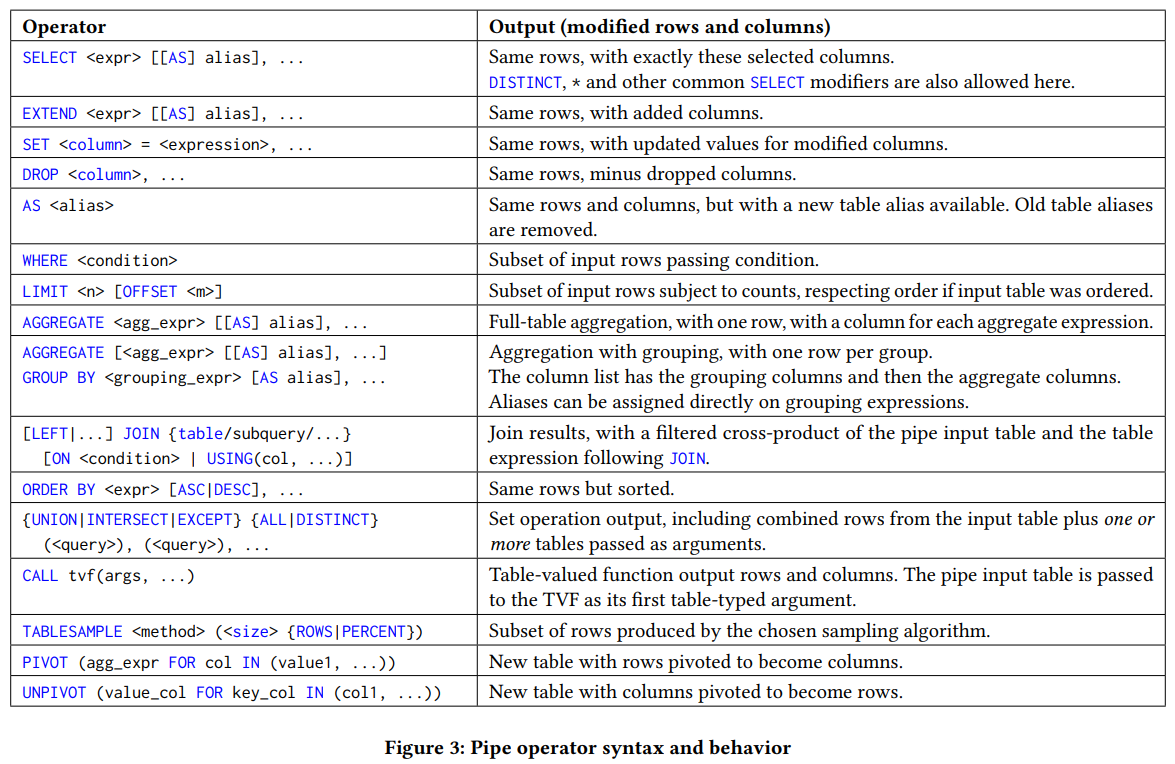
*그림출처 - SQL Has Problems. We Can Fix Them: Pipe Syntax In SQL
마치며
파이프 문법은 간결성을 바탕으로 기존 표준 문법의 보완재로서 역할을 할 것으로 보이며 코드의 가독성을 높이는데 도움을 줄 것으로 기대된다.
그 외에도 TVF(Table-Valued Function)과 함께 새로운 관계형 연산들을 추가하거나 Logging 또는 Debugging 기능의 확장 가능성에도 주목할 필요가 있다.
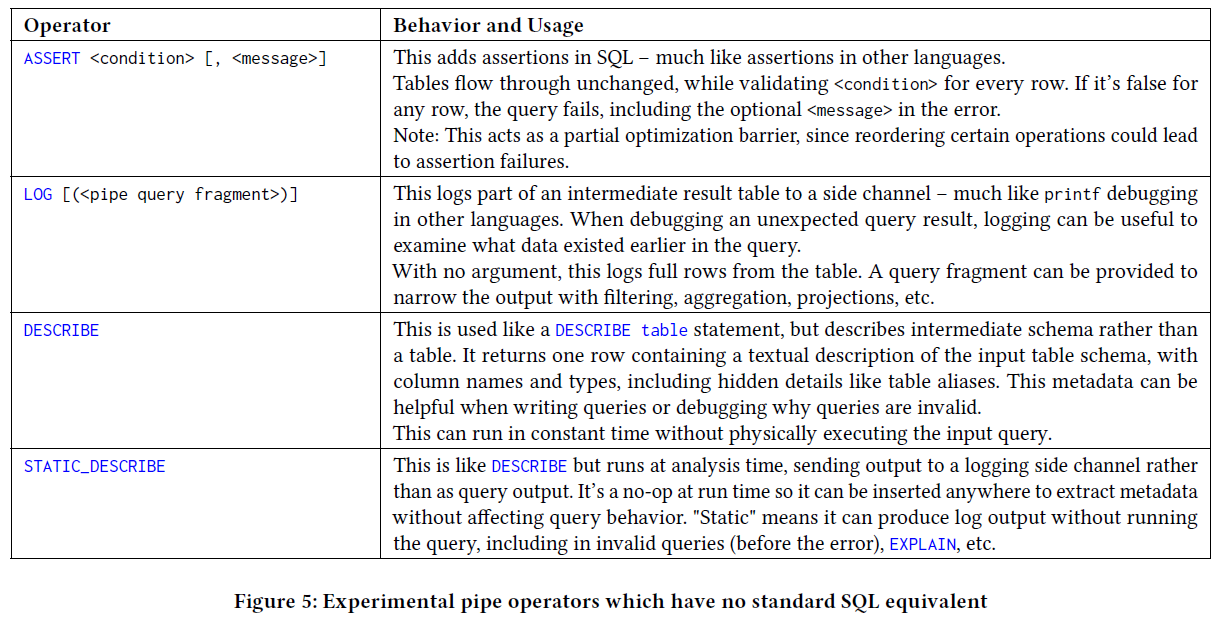
마지막으로, 생성형 AI 를 활용한 Query Generation 시에도 문장의 복잡도를 낮춰 좀 더 정확한 쿼리 생산에 기여할 것으로 기대된다.
Speculatively, an LLM that understands pipe SQL syntax could more clearly understand operations in a query, and should be able to generate queries more accurately from its “mental model” of desired query operations.
참고내용
[1] SQL Has Problems. We Can Fix Them: Pipe Syntax In SQL
[2] Pipe syntax
[3] Pipe query syntax
[4] Google Pipe Syntax: Modernizing SQL Without Sacrificing its Strengths

잘 읽었습니다.