
시계열성 혹은 데이터의 연속적인 흐름에서 특정 패턴을 인식하는 문제는 고전적인 gaps and islands 풀이법으로 해결되는 경우가 많습니다.
gaps and islands는 연속된 데이터상에서 "경계(틈)와 구간(섬)" 를 식별하는 패턴 인식형 문제로, 특정 조건의 데이터를 추출하거나 집계값을 계산하는 것에 중점을 두는 일반적인 SQL 문제와는 달리 데이터의 연속성, 그룹 내 단절, 패턴의 시작과 끝 등 시계열적, 흐름적 맥락을 파악해야 합니다.
gaps and islands 유형은 길지 않은 Stackoverflow 활동 기간에 여러 답변을 올렸을 만큼 실무에서도 자주 마주치게 되는 유형의 문제입니다. (아래 Stackoverflow 답변 참고)
【참고】 'Gaps and Islands' problems answered by Jaytiger on Stackoverflow
BigQuery가 최근 MATCH_RECOGNIZE 기능을 Preview 로 릴리즈하였고, 이번 글에서는 이러한 gaps and islands 유형의 문제를 MATCH_RECOGNIZE 구문으로 어떻게 풀어낼 수 있을지 예시와 함께 살펴보도록 하겠습니다.
예시 문제
다음과 같이 A 회사 임직원들의 출근 기록 데이터가 있을 때 "각 직원의 연속 출근 구간(일수)"을 찾고자 합니다.
▷ 예시 데이터: attendance (출근 기록)
+--------+------------+
| emp_id | work_date |
+--------+------------+
| 101 | 2024-01-01 |
| 102 | 2024-01-01 |
| 101 | 2024-01-02 |
| 102 | 2024-01-02 |
| 101 | 2024-01-03 |
| 103 | 2024-01-03 |
| 103 | 2024-01-04 |
| 102 | 2024-01-05 |
| 103 | 2024-01-05 |
| 101 | 2024-01-06 |
| 102 | 2024-01-06 |
| 101 | 2024-01-07 |
| 102 | 2024-01-07 |
| 103 | 2024-01-08 |
| 102 | 2024-01-09 |
| 103 | 2024-01-09 |
| 101 | 2024-01-10 |
| 103 | 2024-01-12 |
+--------+------------+
【참고】예시 데이터는 Perplexity 를 이용하여 생성하였습니다.위 예시 데이터를 생성하는 BigQuery에서의 SQL 구문은 다음과 같습니다.
WITH attendance AS (
SELECT e.* FROM UNNEST([
STRUCT('101' AS emp_id, DATE '2024-01-01' AS work_date), ('101', '2024-01-02'),
('101', '2024-01-03'), ('101', '2024-01-06'), ('101', '2024-01-07'), ('101', '2024-01-10'),
('102', '2024-01-01'), ('102', '2024-01-02'), ('102', '2024-01-05'), ('102', '2024-01-06'),
('102', '2024-01-07'), ('102', '2024-01-09'), ('103', '2024-01-03'), ('103', '2024-01-04'),
('103', '2024-01-05'), ('103', '2024-01-08'), ('103', '2024-01-09'), ('103', '2024-01-12')
]) e
)
SELECT * FROM attendance;Gaps and Islands Approach
먼저, gaps and islands 를 이용하여 문제를 풀어보도록 하겠습니다. 주어진 데이터의 구조와 분석 요구사항에 따라 조금씩 달라질 수 있으나 일반적으로 gaps and islands 푸는 과정은 다음과 같습니다.
-
우선
gap(틈)과island(섬,구간)를 명확히 정의하는 것이 필요합니다. 이 문제에서는 연속된 출근 구간 을 찾는 것이 목표이기 때문에island은 출근일이 연속적으로 이어지는 구간으로 정의됩니다. 이 때gap은 연속적인 출근이 깨진 날이 됩니다. -
다음
gap을 먼저 찾아냅니다.gap은 연속적인 출근이 깨진 날로 정의했기 때문에 연속된 데이터 상에서LAG()함수로 가져온 직전 row 의work_date값과 현재 row 의work_date값을 비교하여gap여부를 판단합니다.
-- gap이 없는 경우 직전의 *work_date* 와는 하루 차이가 납니다. SELECT *, DATE_DIFF(work_date, LAG(work_date) OVER w0, DAY) <> 1 AS gap FROM attendance WINDOW w0 AS (PARTITION BY emp_id ORDER BY work_date)
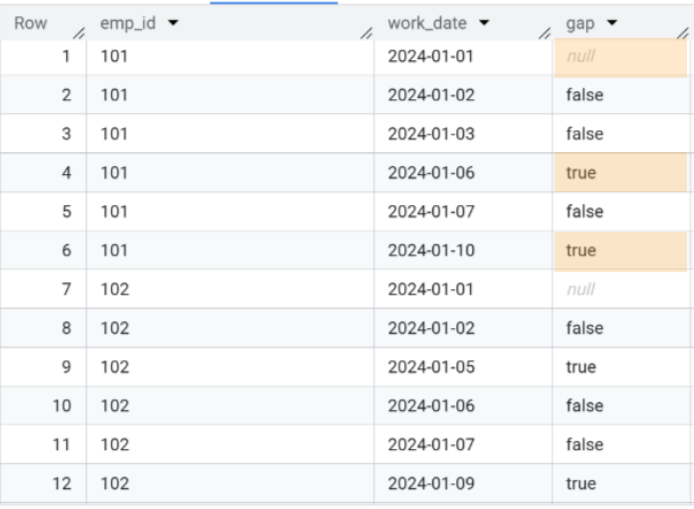
그림에서 연속성 이 깨지는 날의 gap컬럼값이 true임을 확인할 수 있습니다.
island는 연속된 Data 상에서gap의 갯수를 카운트하면 얻어집니다. 위의 그림에서 '2024-01-01' ~ '2024-01-03'까지true인gap의 수는0입니다. 동일한 방식으로 '2024-01-06' ~ '2024-01-07'까지true의 수는 1입니다. 이 과정을 반복하게 되면 출근일이 연속된 구간, 즉island에는 동일한 숫자가 부여됩니다.
코드로 표현하면 다음과 같습니다.
-- COUNTIF() 함수로 gap이 true인 row만 카운트 SELECT *, COUNTIF(gap) OVER w1 AS island FROM ( SELECT *, DATE_DIFF(work_date, LAG(work_date) OVER w0, DAY) <> 1 AS gap FROM attendance WINDOW w0 AS (PARTITION BY emp_id ORDER BY work_date) ) WINDOW w1 AS (PARTITION BY emp_id ORDER BY work_date)
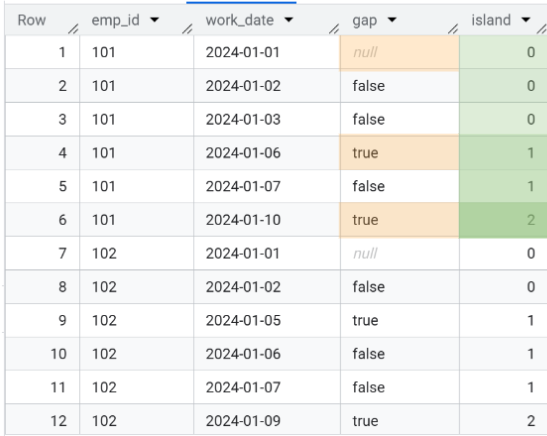
- 마지막으로,
island를 기준으로 필요한 집계 연산을 수행합니다.
연속된 출근 구간(일수) 을 구하는 문제이기 때문에 island를 기준으로 집계 연산을 수행합니다.
SELECT * EXCEPT(gap, island), COUNT(1) OVER (PARTITION BY emp_id, island) AS consecutive_work_days FROM ( SELECT *, COUNTIF(gap) OVER w1 AS island FROM ( SELECT *, DATE_DIFF(work_date, LAG(work_date) OVER w0, DAY) <> 1 AS gap FROM attendance WINDOW w0 AS (PARTITION BY emp_id ORDER BY work_date) ) WINDOW w1 AS (PARTITION BY emp_id ORDER BY work_date) )

지금까지 gaps and islands 문제를 단계별로 푸는 과정을 살펴봤습니다. 각각의 단계별로 서브쿼리를 생성하다 보니 depth가 깊은 코드구조가 만들어졌습니다.
[참고] 이 문제에서의 island는 정의에 의해 work_date가 하루씩 증가하며 이어진 섬(island)입니다. 이 특성을 이용하면 이전 코드에서 서브쿼리 하나를 생략할 수 있습니다. gap의 도움없이 island를 찾을 수 있는 케이스로 아래와 같이 코드를 줄일 수 있습니다.
SELECT * EXCEPT(island), COUNT(1) OVER (PARTITION BY emp_id, island) AS consecutive_work_days FROM ( SELECT *, work_date - INTERVAL COUNT(work_date) OVER w0 DAY AS island FROM attendance WINDOW w0 AS (PARTITION BY emp_id ORDER BY work_date) );
MATCH_RECOGNIZE
다음은 동일한 문제를 MATCH_RECOGNIZE 구문을 이용하여 풀어 보겠습니다.
MATCH_RECOGNIZE 구문은 SQL:2016 표준에 명세된 기능으로 정규 표현식이 주어진 문자의 열 (sequence of characters)에서 특정 패턴을 찾는 연산이라고 하면 MATCH_RECOGNIZE는 행의 열(sequence of rows)에서 특정 패턴을 찾는 구문으로 이해하면 될 것 같습니다.
MATCH_RECOGNIZE - regular expressions over rows
자세한 문법과 기능은 이 글에서 다루지는 않겠지만 BigQuery의 경쟁 솔루션의 하나인 Snowflake 보다 상당히 늦게 선을 보였음에도 Pattern Variable 정의시 LEAD, LAG 을 미지원하는 등 어정쩡한 상태로 릴리즈가 된 것은 아쉬운 점입니다.
Analytic function not allowed in MATCH_RECOGNIZE DEFINE predicate
이로 인해 우회적인 방법을 적용해야 하기 때문에 쿼리 구조가 조금 복잡해지게 됩니다.
문제로 돌아가서, MATCH_RECOGNIZE 구문을 사용한 코드는 다음과 같습니다.
SELECT * EXCEPT(dates) FROM ( SELECT *, LAG(work_date) OVER (PARTITION BY emp_id ORDER BY work_date) AS pre_date -- ① FROM attendance ) MATCH_RECOGNIZE ( PARTITION BY emp_id ORDER BY work_date MEASURES ARRAY_AGG(work_date) AS dates, -- ② MATCH_NUMBER() AS island, COUNT(1) AS consecutive_work_days PATTERN ( A N* ) DEFINE A AS TRUE, N AS DATE_DIFF(work_date, pre_date, DAY) = 1 -- ③ ), UNNEST(dates) AS date -- ④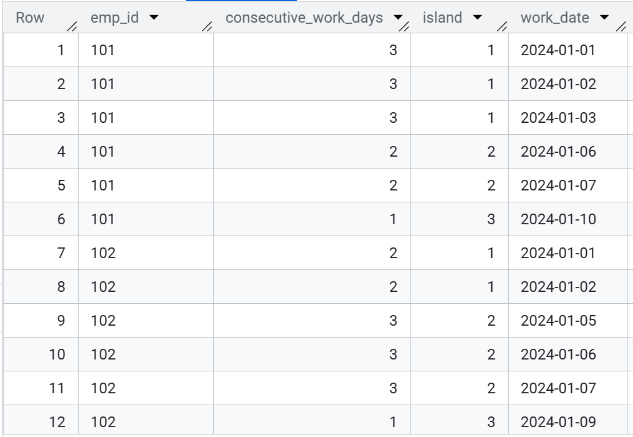
앞선 쿼리와 동일한 결과가 만들어지지만 gaps and islands 코드에 비해 조금 복잡해 보입니다. BigQuery의 어정쩡한 릴리즈로 Workaround를 적용했기 때문이기도 하고 상대적으로 예시의 gaps and islands Rows 패턴이 단순하기 때문이기도 합니다.
그리고 아직 눈에 익숙하지 않아서 복잡해 보이는 면도 있는데 하나의 절(Clause) 안에서 패턴 매칭과 관련한 대부분의 연산을 수행하고 있기 때문에 gaps and islands 의 중첩된 서브쿼리 구조와 달리 쿼리 구조는 오히려 단순해집니다.
코드를 조금 풀어서 설명드리면,
-
하단부의
DEFINE에서는 패턴 변수를 정의합니다.AAS TRUE에서A패턴 변수는 임의의 row 에 매치됩니다.N은 직전 행의 출근 날짜와 현재 행의 출근 날짜와의 차이가 하루인 row에 매치됩니다.- N AS DATE_DIFF(work_date, LAG(work_date), DAY) = 1 과 같이 패턴 변수 정의 구문에서
LAG함수를 바로 사용할 수 있다면 ① 과 같이 서브쿼리에서LAG윈도우 함수를 사용하여pre_date컬럼을 미리 정의할 필요가 없겠지만 이번 릴리즈에서 BigQuery가 이를 미지원하고 있어 우회적인 방식을 택했습니다.
- N AS DATE_DIFF(work_date, LAG(work_date), DAY) = 1 과 같이 패턴 변수 정의 구문에서
-
각 단위 패턴을 정의한 패턴 변수를 이용하여
PATTERN구문에 찾고자 하는 rows 패턴을 정의합니다. 여기에서는 정규표현식의 문법을 차용하고 있습니다.A N*A는 임의의 row이고 다음N은 직전과 하루차이가 나는, 동일 island에 속하는 row입니다.*는 정규표현식에서 0개 이상을 의미하므로A N*는 임의의 날을 시작으로 날짜가 연속적으로 이어진 구간에 매치됩니다. 즉 하나의 island가 하나의 match에 대응합니다.

MEASURES구문에서는 2.에서 찾아진 Match에 대해서 어떤 집계 연산을 적용할지를 정의합니다.- 기본적으로 집계 연산은 각 Match에 대해서 하나의 행을 리턴합니다. 이 문제에서 원하는 출력은 집계된 행이 아니라 각 행에 island 번호가 붙여진 결과이기 때문에 ②, ④ 의 trick을 사용하고 있습니다.
- BigQuery는 각 Match에 대해
ALL ROWS PER MATCH가 아닌 default로ONE ROW PER MATCH로만 결과를 리턴하고 있습니다.
마지막으로 동일한 쿼리를 BigQuery Pipe Syntax로 작성하면 아래와 같습니다. MATCH_RECOGNIZE 구문은 Pipe 문법과도 잘 어울리는 것 같습니다. (참고 - Pipe Syntax in BigQuery)
FROM attendance |> EXTEND LAG(work_date) OVER (PARTITION BY emp_id ORDER BY work_date) AS pre_date |> MATCH_RECOGNIZE ( PARTITION BY emp_id ORDER BY work_date MEASURES ARRAY_AGG(work_date) AS dates, MATCH_NUMBER() AS island, COUNT(1) AS consecutive_work_days PATTERN ( A N* ) DEFINE A AS TRUE, N AS DATE_DIFF(work_date, pre_date, DAY) = 1 ) |> CROSS JOIN UNNEST(dates) AS date |> DROP (dates);
마치며
지금까지 간단한 gaps and islands 유형의 문제를 MATCH_RECOGNIZE 구문으로 작성해 보았습니다.
이번 예시와 같이 단순한 형태가 아닌 여러 행을 순서와 상태 변화에 따라 조건별로 그룹화·패턴화 하는 복잡한 문제에서는 윈도우 함수 사용을 포함한 gaps and island 접근법은 한계가 있어 이를 MATCH_RECOGNIZE가 보완해 줄 수 있을 것으로 생각합니다.
BigQuery의 아쉬운 릴리즈로 간결한 쿼리로 작성되지는 못했지만 복잡한 패턴을 찾아야 하는 경우에는 상대적으로 유지보수나 가독성 측면에서 높은 점수를 줄 수 있을 듯 합니다.
문법적인 상세는 아래 참고문서를 참고하시고 기회가 되면 좀 더 다양한 예시로 후속 글을 작성해 보도록 하겠습니다.
감사합니다.
▷ MATCH_RECOGNIZE 활용 예시
- 금융 데이터 분석 (이상징후, 랠리, 급락 등 추세 감지)
- 센서/시계열 데이터 이벤트 탐지 (이상 상황, 반복 패턴 등)
- 로그 분석 및 사용자 행동 추적 (특정 활동 순서 감지 등)
▷ 참고문서

정말 유익한 글이예요. 링크드인에 공유하면 좋아요 좀 받으실 것 같은데요! match-magazine 함수가 있다는 것도 처음 알았습니다. 감사합니다!