
1. 주기억장치 관리(Main Memory Management)
보조기억장치(e.g. 하드 드라이브, SSD)에는 운영체제와 다양한 실행 파일들이 저장되어 있다. 컴퓨터의 전원을 켜면, 운영체제는 보조기억장치에서 메인 메모리(RAM)로 로드된다.
운영체제의 중요한 역할 중 하나는 프로세스를 관리하는 것이다. 즉, 운영체제는 CPU 자원을 효율적으로 관리하며, 여러 프로세스가 원활하게 실행될 수 있도록 조정합니다. 이를 프로세스 관리(Process Management)라고 한다.
또 다른 중요한 역할은 메인 메모리(RAM)를 효과적으로 관리하는 것이다. 운영체제는 메모리의 사용을 추적하고, 프로세스가 필요한 메모리를 할당하거나 해제하며, 메모리 자원을 최적화한다. 이를 메모리 관리(Memory Management)라고 한다.
메인 메모리 관리에 대해 자세히 알아보자.
1.1. 메모리의 역사
현재 우리는 메모리를 생각하면 반도체 집적 회로를 떠올린다. 하지만 과거에는 반도체 기술이 지금처럼 발달하지 않았다. 예전에는 반도체 안의 소자, 특히 트랜지스터가 손톱 크기 정도였고, 1비트를 저장하는 데에도 상당한 어려움이 있었다.
트랜지스터 메모리는 1960-1970년대에 사용되었으며, 그 이전에는 진공관 메모리가 있었다. 진공관은 트랜지스터 보다 훨씬 크고 비효율적이었으며, 손가락 서너 개 크기의 진공관이 1비트를 저장할 수 있는 정도였다.
또 다른 초기 메모리 기술로 Core Memory가 있다. 이는 반지 모양의 철심에 자성 물질을 바르고 전기를 흘려 플레밍의 오른손 법칙에 따라 자장이 형성되도록 했다. 전기를 흘려 자석을 만드는 방식을 통해 메모리를 구성했다.
이런 과거의 기술적 한계를 고려할 때, 1비트를 저장하는 데에 굉장히 큰 비용이 들었을 것으로 예상할 수 있다.
1.2. 메모리 용량
메모리 용량은 시간이 지나면서 급격히 증가했다.
- 1970년대: 8-bit PC 64KB
- 1980년대: 16-bit IBM-PC 640KB → 1MB → 4MB
- 1990년대: 수 MB → 수십 MB
- 2000년~: 수백 MB → 수 GB
우리가 배우는 운영체제는 언제 만들어졌을까? 운영체제의 기본 개념은 1960년대에 만들어졌다. (e.g. 리눅스는 1969년에 개발되었다.)
그 시절에는 메모리가 매우 부족했기 때문에, 프로세스 관리도 중요했지만 메모리 관리가 무엇보다도 중요했다. 사람들은 어떻게 하면 작은 메모리를 알차게 사용할 수 있을지 고민하며 다양한 기술을 개발했다.
하지만 지금은 메모리 용량이 매우 커졌다. 그럼 이제 메모리 관리는 중요치 않은 걸까?
그렇지 않다. 메모리는 언제나 부족하다.
1.3. 언제나 부족한 메모리
초등학생 때는 용돈 만 원으로 살고, 중학생 때는 용돈 5만원으로 살고, 고등학생 때는 용돈 10만 원으로도 충분히 살았는데 이제는 그 돈으로는 턱없이 부족하다. 생활 반경이 넓어지고 씀씀이가 커지면서 필요한 돈도 함께 늘어나기 때문이다.
메모리도 마찬가지다. 메모리 용량이 매우 커졌음에도 불구하고, 여전히 메모리는 늘 부족하다.
1950-1960년대에는 프로그램을 작성할 때 주로 기계어, 어셈블리어로 작성했다. 1970년대에는 C 언어와 같은 고급 언어로 작성되기 시작했다. 이후 자바와 같은 객체지향 언어가 등장하면서 프로그램의 규모는 더욱 커졌다. 예전에는 숫자나 문자를 처리하던 프로그램이 지금은 그림, 소리, 비디오 등 다양한 멀티미디어 자료를 처리하게 되면서 데이터의 크기가 기하급수적으로 증가했다.
때문에 현대에도 메모리는 여전히 부족하다. 메모리 관리에 대한 연구는 오랜 연구 분야지만, 그 필요성은 지금도 존재한다.
메모리 관리에서 우리가 배우고자 하는 것은, 이렇게 늘 부족한 메모리를 어떻게 하면 낭비 없이 효율적으로 사용할 수 있을까 하는 것이다.
1.4. 메모리에 프로그램 올리기
1.4.1. 메모리 구조
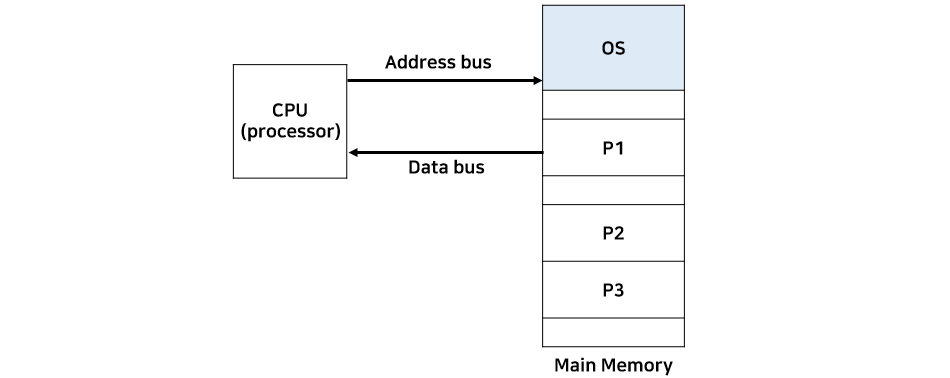
메모리 구조는 기본적으로 주소(Address)와 데이터(Data)로 이루어져 있다. CPU가 특정 주소를 읽으려고 하면, 해당 주소를 메모리에 보내고 메모리는 그 주소에 해당하는 데이터를 CPU로 돌려준다.
1.4.2. 프로그램 개발
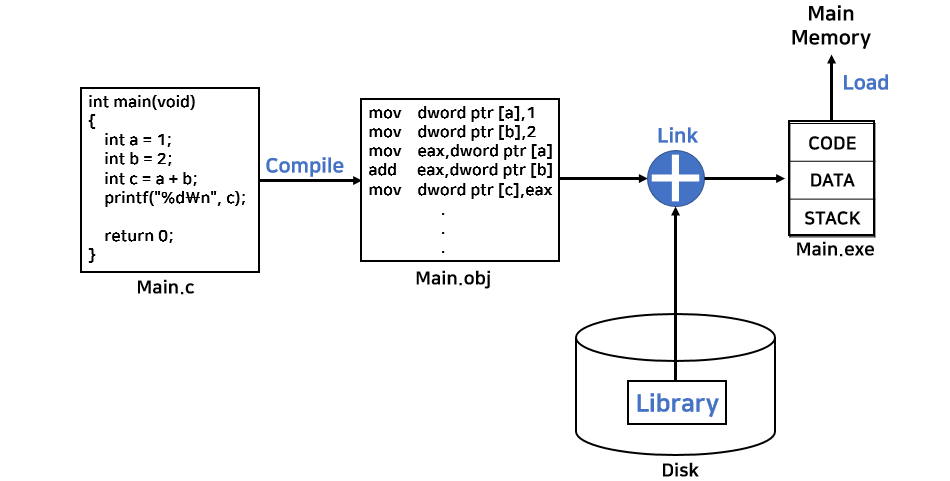
프로그램을 빌드하면 컴파일 과정을 거치면서 원천 파일(Source file), 목적 파일(Object file), 실행 파일(Executable file)이 생성된다.
원천 파일(e.g. main.c)은 고수준 언어나 어셈블리 언어로 작성된 코드가 포함되어 있다. 이 원천 파일을 컴파일하면 목적 파일(e.g. main.o)이 생성된다. 목적 파일은 기계어로 번역된 파일로, 컴파일 과정에서 생성되는 결과물이다. 이 목적 파일은 프로그램 실행에 필요한 코드의 일부만 포함하고 있으며, 나중에 다른 코드들과 연결(Link)되어 최종 실행 파일(e.g. main.exe)이 된다.
1.4.3. 프로그램 실행
실행 파일은 크게 세 가지 주요 세그먼트로 구성된다.
- 코드(Code): 실제 기계어 코드가 저장된 부분
- 데이터(Data): 프로그램이 사용하는 변수들이 저장되는 부분
- 스택(Stack): 함수 호출 시 돌아오는 주소와 지역 변수가 저장되는 부분
1.4.4. 메모리에 실행 파일 올리기
이렇게 만들어진 실행 파일을 메모리에 올려보자. 이걸 메모리의 몇 번지에 올려야 할지 우리는 고민할 필요가 없다. 운영체제가 이 문제를 해결해 주기 때문이다. 운영체제의 메모리 관리 부서에서 Loader가 이 역할을 담당한다.
다중 프로그래밍 환경에서는 여러 프로세스가 메모리에 동시에 올라가 있다. 예를 들어, 오늘은 워드 프로세서를 메모리의 500번지에 올렸다. 내일 해당 주소에 다시 워드 프로세서를 올릴 수 있다는 보장이 있을까? 내일은 해당 주소가 다른 프로세스에 의해 사용될 수 있어 동일한 주소를 보장받을 수 없다.
이 문제를 해결하는 데 중요한 역할을 하는 것이 MMU(Memory Management Unit)이다.
1.4.5 MMU(Memory Management Unit)
MMU는 CPU와 메모리 사이에 위치하며, base 레지스터와 limit 레지스터, 그리고 재배치 레지스터(Relocation Register)를 포함하고 있다.
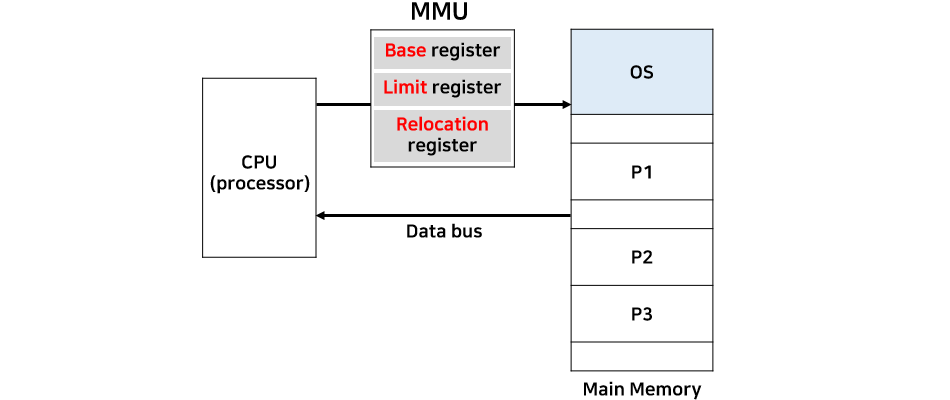
MMU 덕분에 우리는 실행 파일을 메인 메모리의 어느 곳에나 배치하여 실행할 수 있다.
예를 들어, CPU는 main.exe가 항상 메모리의 0번지에서 실행된다고 가정하지만, 실제로는 500번지에 위치할 수 있다. 이때 MMU가 500번지를 매핑해줌으로써 CPU는 0번지에서 실행된다고 생각하지만 실제로는 500번지에서 실행된다. 만약 다음 날 1000번지에서 실행된다면, MMU는 1000번지를 매핑해준다.
운영체제는 이 재배치 레지스터를 조정하여, 실제 메모리의 어느 위치에 프로그램이 있든지 상관없이 동일하게 실행되도록 한다. 따라서 프로그램이 메모리의 어느 번지에 위치하는지는 중요치 않게 된다.
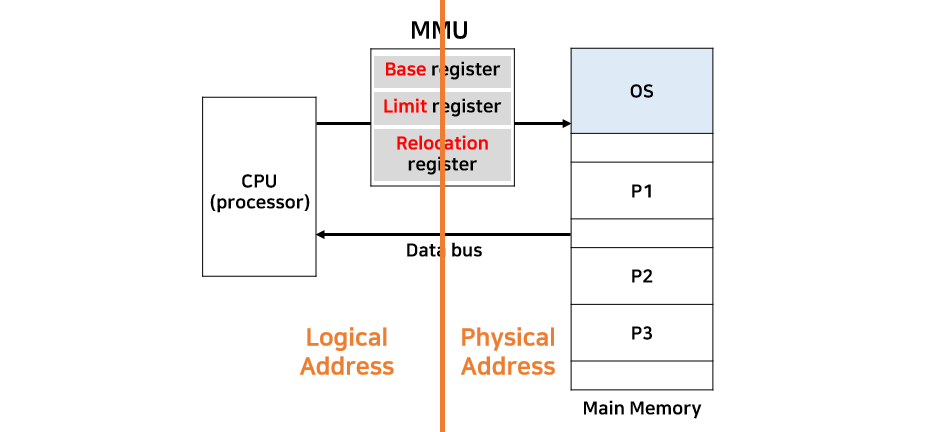
정리하자면, MMU는 주소 변환(Address Translation)을 수행하여 논리적 주소(CPU가 내는 주소)를 물리적 주소(실제 메모리 주소)로 변환한다. CPU는 항상 동일한 주소를 사용하고 있다고 생각하지만, 실제로 물리적 주소는 매번 다를 수 있다. 이렇게 해서 컴퓨터 내에는 두 가지 주소(논리적 주소, 물리적 주소)가 존재하게 된다.
2. 메모리 낭비 방지
운영체제의 주된 목적은 컴퓨터를 쉽게 사용할 수 있도록 하고, 시스템의 효율성을 극대화하는 것이다. 이 과정에서 중요한 요소 중 하나는 메모리 낭비를 최소화하는 것이다. 메모리 낭비를 줄이기 위해 어떤 요소들이 문제로 작용하며, 이를 어떻게 해결할 수 있을지 알아보자.
2.1. 동적 적재(Dynamic Loading)
예를 들어, 오류 처리를 위한 코드가 있다고 생각해보자. 이는 파일이 정상적으로 열리지 않는 경우에만 실행될 텐데, 실제로 대부분의 경우 파일은 정상적으로 열린다. 이처럼 거의 사용되지 않는 오류 처리 루틴을 메모리에 항상 올려놓는 것은 메모리 낭비다.
동적 적재는 이러한 낭비를 방지하기 위한 방법이다. 동적 적재는 프로그램 실행 시 반드시 필요한 루틴이나 데이터만 메모리에 적재하고, 필요 시에만 추가로 적재한다. 모든 오류 처리, 모든 데이터(e.g. 배열)을 필요할 때에만 메모리에 올리는 것이 동적 적재의 예다.
현재 사용하는 윈도우, 리눅스는 동적 적재를 채택해 메모리 사용의 효율성을 높이고 있다.
cf) 정적 적재(Static Loading): 프로그램의 모든 루틴과 데이터를 미리 메모리에 올리는 방식
2.2. 동적 연결(Dynamic Linking)
여러 프로그램이 공통적으로 사용하는 라이브러리 코드가 있다면, 이를 메모리에 중복해서 올리는 것은 큰 낭비이다. 예를 들어, p1.exe와 p2.exe가 printf와 같은 라이브러리 코드를 사용하는 경우, 이 라이브러리를 각각의 프로그램이 중복해서 메모리에 올린다면 메모리 자원의 낭비가 발생한다.
동적 연결은 이러한 낭비를 방지하는 방법이다. 공통적으로 사용되는 라이브러리 코드를 하나만 메모리에 적재하고, 여러 프로그램이 이를 공유하는 방식이다. 동적 연결은 프로그램이 실행 파일을 우선 만든 뒤 필요에 따라 하드 디스크에서 이를 링크하는 방식으로, 실행 파일을 만들기 전에 링크가 이루어지는 정적 연결(Static Linking)과 대조된다.
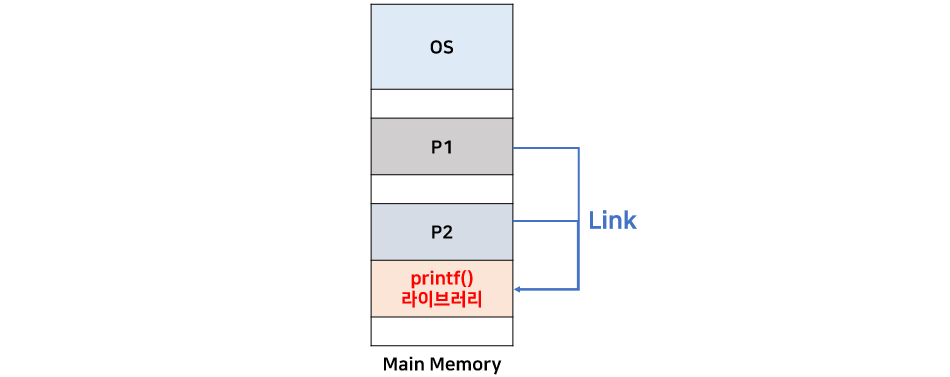
리눅스에서는 이러한 공통 라이브러리를 공유 라이브러리(Shared Library)라고 하며, 윈도우에서는 동적 연결 라이브러리(DLL: Dynamic Linking Library)라고 한다.
2.3. Swapping
Swapping은 메모리에 적재되어 있지만 현재 사용되지 않는 프로세스를 메모리에서 하드 디스크로 이동시키는 방법이다.
hwp 프로그램을 사용하던 중에 전화가 와서 잠시 자리를 비운 상황을 생각해 보자. 내가 자리를 비우더라도 프로그램은 여전히 메모리에 올라가서 실행 중에 있고, 이는 명백한 메모리 자원의 낭비이다. 이때 운영체제는 메모리에서 이 프로그램을 하드 디스크로 이동시키고, 다른 프로세스를 위해 메모리를 확보한다.
하드 디스크에 저장된 hwp.exe 파일에는 기본적으로 code와 data가 포함되어 있다. 이 파일이 메모리에 올라가면 code, data, stack으로 구성된다. 하드 디스크에 있는 hwp.exe와 메모리에 적재된 hwp.exe는 동일한 코드 파일을 가질지 몰라도, data와 stack은 메모리에 로드된 후의 상태에 따라 다르게 관리된다.
따라서, 프로세스를 swap-out할 때 단순히 하드 디스크에 있는 원본 파일로 대체할 수는 없다. Swap-out은 하드 디스크의 특정 영역(Backing Store)에 현재까지 실행 중이던 프로세스의 상태(code, data, stack)를 저장하는 것을 의미한다. 이렇게 swap되어 확보된 메모리 공간은 다른 프로세스가 사용하게 되어 메모리 낭비를 방지한다.
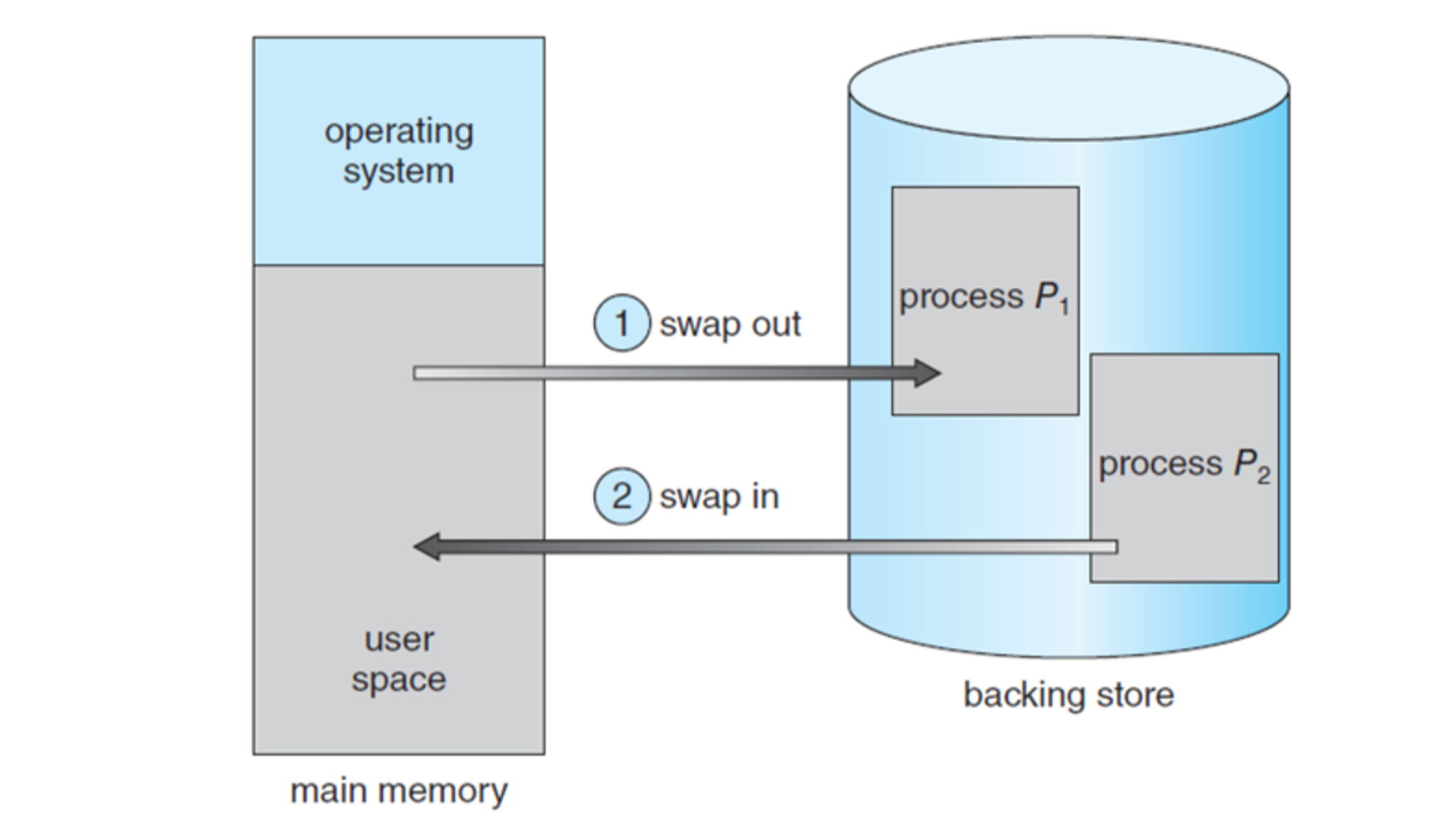
하드 디스크는 크게 파일 시스템(File System)과 Backing Store(=Swap Device)로 구분할 수 있다. Backing Store는 swap-out된 프로세스의 이미지를 저장하는 공간이다. 서버나 대형 컴퓨터의 경우, 파일 시스템과 Backing Store를 위한 별도의 하드 디스크를 두기도 한다. 그러나 일반적인 PC나 스마트폰은 하나의 하드 디스크를 나누어 이 기능을 수행한다.
Backing Store의 크기는 대개 메인 메모리 크기와 비슷하게 설정된다. 예를 들어, 메인 메모리가 1GB인 경우, 최대 1GB의 프로세스가 swap-out될 수 있으므로 Backing Store의 크기도 이와 비슷한 크기로 설정된다. 사실 메인 메모리에는 운영체제 영역도 있기 때문에 실제 필요한 크기는 더 작아도 된다. Backing Store의 크기는 시스템에 따라 기본적으로 설정되지만, 사용자가 직접 설정할 수도 있다.
전화를 마치고 돌아와 hwp.exe를 다시 실행하려고 할 때, hwp.exe가 사용 중이던 주소를 다른 프로세스가 사용하고 있다면 hwp.exe는 다른 메모리 영역으로 이동해야 한다. 이때 재배치 레지스터(Relocation Register) 값을 조정하면 문제없이 프로그램 실행이 가능하다.
Swapping 자체는 성능에 부담을 줄 수 있다. 프로세스의 상태를 Backing Store에 기록하는 작업은 하드 디스크의 속도에 의존하기 때문에 느릴 수 있다. 그럼에도 Swapping 덕분에 전체 메모리 활용도는 크게 향상된다. 일부 슈퍼 컴퓨터의 경우, Backing Store를 위해 속도가 느린 별도의 저장 장치를 사용하여 메모리 효율을 극대화하기도 한다.
3. 연속 메모리 할당
최초의 컴퓨터는 OS가 없었기 때문에 메모리에 프로세스 하나만 올라갔다.
시간이 지나면서 메모리에는 운영체제와 프로세스 하나가 올라간다. (e.g. 도스)
이후 메모리에 단일 프로세스와 함께 여러 프로세스가 돌아가는, 다중 프로그래밍 환경이 생성되었다.
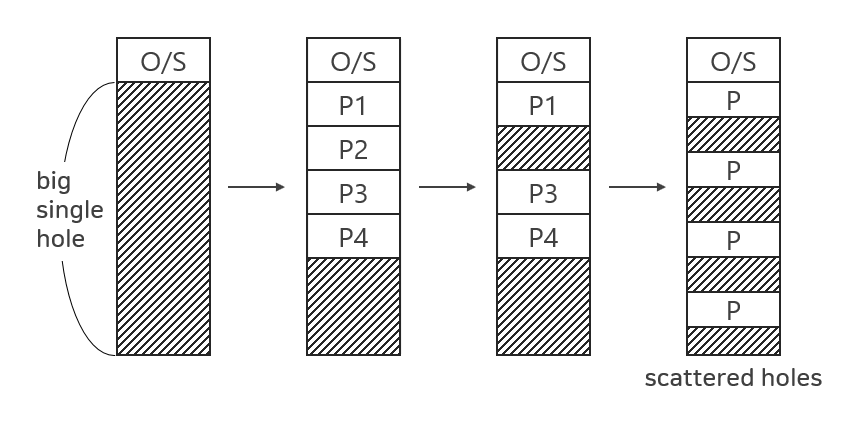
3.1. 외부 단편화(External Fragmentation)
부팅 직후의 메모리 상태는 OS와 big single hole로 구성되어 있다. 이후 프로세스가 생성되고 종료되는 것이 반복되며 scattered holes가 생성된다. 즉, 메모리가 쪼개져 있게 되는데, 이를 메모리 단편화(Memory Fragmentation)라고 한다.
Holes의 크기를 100KB, 50KB, 80KB라고 해보자. 새로운 130KB짜리 프로세스를 메인 메모리에 올리고 싶은데, holes가 불연속적으로 흩어져 있어 올릴 수 없다. 이를 외부 단편화라고 한다. 비어 있는 메모리 공간을 합치면 충분히 들어갈 수 있는데 떨어져 있기 때문에 이를 사용할 수 없는 상황을 말한다.
3.2. 연속 메모리 할당 방식
외부 단편화를 어떻게 하면 최소화할 수 있을까? 우선 연속 메모리 할당 방식부터 살펴보자.
- First-fit(최초 적합): 메모리를 순차적으로 돌면서 해당 프로세스가 올라갈 수 있는 곳을 찾으면 즉시 올린다.
- Best-fit(최적 적합): 프로세스의 크기와 가장 밀접한 메모리 공간에 올린다.
- e.g. 60KB의 프로세스는 100KB가 아니라 80KB에 올린다.
- Worst-fit(최악 적합): 프로세스와 가장 밀접하지 않은 메모리 공간에 올린다. 더 작은 메모리 공간에는 올릴 수 없다.
메모리를 순차적으로 돌면서 알맞은 공간이면 바로 프로세스를 올린다는 점에서 속도 측면으로는 first-fit이 가장 우수하다. 메모리가 가장 효율적으로 활용되는 방식은 의외로 best-fit과 first-fit이 비슷하다. Best-fit 방식이 가장 우수할 것이라고 예상되지만, 여러 케이스를 돌려본 결과 두 방식이 유사하다고 한다. Worst-fit은 언제나 가장 비효율적이다.
그러나 어떤 방식을 사용하든 외부 단편화 문제를 완벽히 해결할 수는 없다. 실제로 이로 인한 메모리 낭비는 수준에 달한다.
운영체제가 메모리 공간을 지켜보다가, 프로세스를 새로 돌리려고 할 때 실행 중인 프로세스들 또는 holes를 한 곳으로 모으는 것을 Compaction이라고 한다. 이는 외부 단편화를 해결할 수는 있겠으나 부담이 크고, 어떤 프로세스를 어디로 모으는 게 효율적일지 계산하는 최적 알고리즘이랄 게 없다.
4. 가상 메모리
가상 메모리는 물리적 메모리 크기의 한계를 극복하기 위해 개발된 기술이다. 메인 메모리가 100MB밖에 없는데 200MB 크기의 프로그램을 실행하고 싶은 상황을 생각해 보자.
200MB의 프로그램을 실행할 때, 반드시 모든 프로세스 이미지를 메모리에 올려야 할까? 그렇지 않다. 우리는 동적 적재에서 보았듯, 오류 처리 코드와 같이 반드시 필요하지 않은 루틴은 실행 중에 올릴 필요가 없다. 예를 들어, 오류 처리 루틴이 50MB라면 이를 제외하고 150MB만 메모리에 올리면 된다.
그래도 메모리가 부족하다면 사용하지 않을 루틴을 더 제외할 수 있다. 예를 들어, 한글 작업을 하는 동안 정렬 또는 표 만들기 기능을 사용하지 않을 예정이라면, 이들을 메모리에 올리지 않고 당장 사용하는 부분만 올려 실행한다.
결국 가상 메모리의 핵심은, 우리가 프로그램의 모든 코드를 메모리에 올려야 한다고 생각할 필요가 없다는 것이다. 필요한 부분만 메모리에 올려 프로그램을 실행할 수 있다는 개념이 가상 메모리의 본질이다.
4.1. 요구 페이징(Demand Paging)
요구 페이징은 프로세스를 페이지 단위로 나누어, 현재 필요한 페이지만 메모리에 올리는 방식이다. 필요한 페이지가 메모리에 없으면 하드 디스크에서 해당 페이지를 가져오고, 현재 요구되지 않는 페이지는 Backing Store에 저장한다.
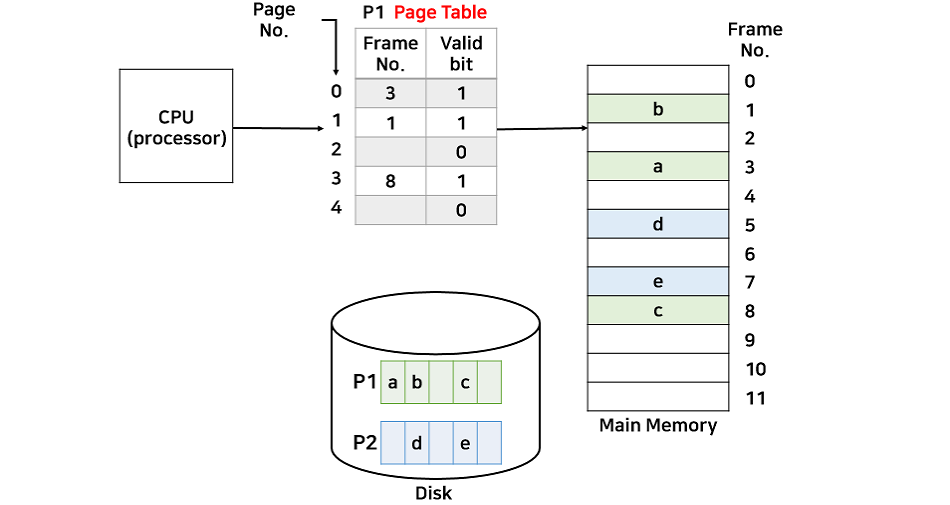
페이지 테이블에는 각 페이지 상태를 기록하는 유효 비트(Valid Bit)가 있다. 이 비트를 통해 메모리에 올라와 있는 페이지와 그렇지 않은 페이지(invalid)를 구분할 수 있다. CPU가 요청한 주소가 페이지 테이블에 없으면, MMU는 CPU에 인터럽트를 걸어 OS가 해당 페이지를 하드 디스크에서 메모리로 가져오도록 처리한다.
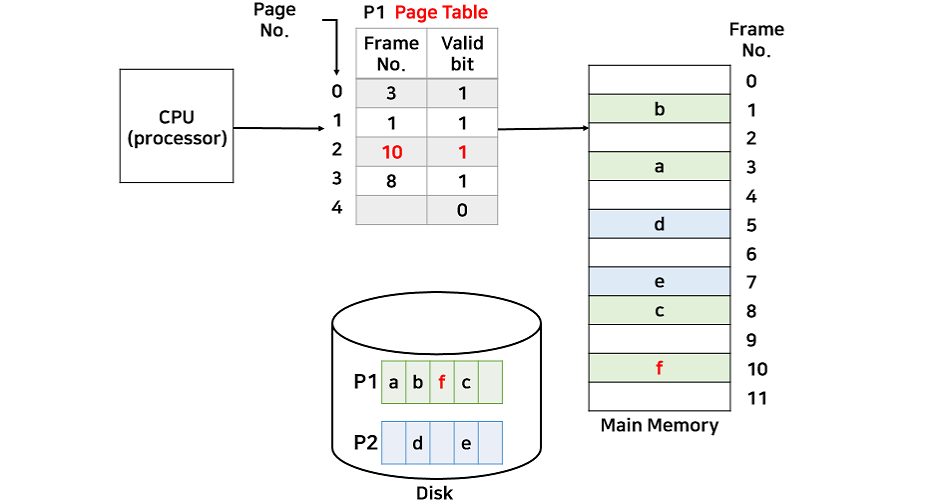
가상 메모리를 만드는 방법은 대표적으로 두 가지가 있으나, 요구 페이징이 가장 일반적으로 사용되어 두 용어를 동일하게 간주하는 경우가 많다.
4.1.1. Pure Demanding Paging
진짜 필요한 페이지만 메모리에 가져오는 방식이다. 프로그램이 처음 실행될 때 어떤 페이지가 필요한지 예측하지 않고, 처음에는 아무 페이지도 메모리에 올리지 않는다.
처음 프로그램이 실행될 때 페이지 부재가 많이 발생하여 속도가 느려질 수 있으나, 메모리 절약에는 도움이 된다.
4.1.2. Prepaging
앞으로 필요할 것으로 예상되는 페이지를 미리 가져오는 방식이다.
페이지 부재를 줄이고 프로그램 실행 속도를 높일 수 있지만, 미리 가져온 페이지가 실제로 사용되지 않으면 메모리 낭비가 발생할 수 있다.
4.1.3. Swapping vs Demanding Paging
Swapping은 프로세스 전체를 메모리에서 하드 디스크로 내보내고, 필요할 때 전체를 다시 가져오는 방식이다. 반면, Demanding Paging은 필요한 페이지만을 메모리로 가져오는 방식이다.
둘 다 메모리와 Backing Store를 오가는 방식이지만, Swapping은 프로세스 단위로, Demanding Paging은 페이지 단위로 작업이 이루어진다.
4.2. 페이지 부재(Page Fault)
CPU가 요청한 페이지가 메모리에 없을 때 발생하는 상황이다. 페이지 부재가 발생하면 CPU는 하던 일을 멈추고, OS가 해당 페이지를 하드 디스크에서 메모리로 가져오도록 처리한다.
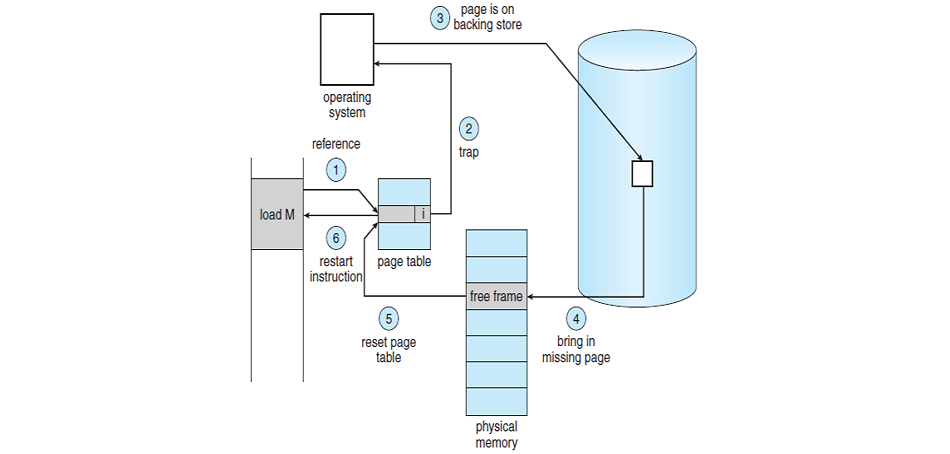
과정은 다음과 같다.
- CPU가 특정 주소를 요청한다.
- 해당 주소가 포함된 페이지가 메모리에 없는 경우, MMU가 페이지 부재를 감지하고 CPU에 신호를 보낸다.
- OS가 하드 디스크를 돌면서 요구 페이지를 찾는다.
- 요구 페이지를 메인 메모리로 가져온다.
- 페이지 테이블을 갱신한다.
- 해당 페이지를 읽어 명령을 마저 수행한다.
4.2.1. 유효 접근 시간(Effective Access Time)
CPU가 메모리에 접근하는 시간은 페이지 부재 발생 여부에 따라 달라진다. 페이지 부재가 발생하지 않으면 메모리에서 데이터를 즉시 가져올 수 있지만, 페이지 부재가 발생하면 하드 디스크에서 데이터를 가져와야 하므로 시간이 더 오래 걸린다.
유효 접근 시간이란 페이지 부재 확률()와 페이지 부재 처리 시간(), 메모리 접근 시간()을 조합한 평균 접근 시간을 의미한다. ()
아래 예제를 살펴 보자.
- (DRAM)
여기서 페이지 부재 확률의 계수가 매우 커 가 높아질수록 유효 접근 시간 가 크게 증가하는 것을 확인할 수 있다.
예를 들어 일 경우, 으로 보다 40배는 느리다.
일 경우 으로 보다 10% 느리다.
⏱️ 페이지 부재 처리 시간 은 Seek Time, Rotational Delay, Transfer Time으로 구성되어 있다.
하드 디스크의 구조는 원판(플래터)에 자성 물질이 코팅되어 있고, 그 위에 디스크 헤드가 위치하여 데이터를 읽고 쓴다. 디스크 헤드는 전기 코일로 이루어져 있으며, 이 코일에 전류가 흐르면 자성이 발생하고, 자성 물질에 기록된 데이터를 읽을 수 있다. 원판이 고속으로 회전하면서 디스크 헤드가 자성 물질의 변화에 따라 유도된 전기 신호를 감지하여 데이터를 읽어낸다.
하드 디스크에서 데이터를 읽어내는 과정은 다음과 같다.
- Seek Time: 디스크 헤드를 원하는 트랙(원판의 특정 위치)으로 이동시키는 데 걸리는 시간. 트랙은 원판의 원형 경로를 의미하며, 헤드가 물리적으로 해당 트랙으로 이동해야 한다. 이 과정은 전체 디스크 접근 시간 중 가장 오래 소요되는 부분이다.
- Rotational Delay: 트랙에 도달한 후, 원판이 회전하여 디스크 헤드 아래로 원하는 데이터가 위치할 때까지의 대기 시간. 원판이 회전하는 속도에 따라 달라지며, 데이터가 헤드 아래에 도착할 때까지의 시간이다.
- Transfer Time: 디스크 헤드가 데이터를 읽어내는 실제 시간. 원판이 회전하면서 자성 물질의 변화를 감지해 데이터를 읽어들이며, 전기가 유도되는 과정에서 정보가 전송된다.
이 세 가지 시간을 모두 합한 것이 하드 디스크에서 데이터를 읽는 데 걸리는 총 시간이다. 일반적으로 이들 중 가장 오래 걸리는 시간은 Seek Time이다. Seek Time은 헤드가 물리적으로 움직여야 하기 때문이다.
이를 거꾸로 생각해 보면, Backing Store를 하드 디스크로 쓰지 않고 SSD, 느린 저가 DRAM을 사용하는 방법을 활용해 유효 접근 시간을 낮출 수 있다.
4.2.2. 지역성의 원리(Principal of Locality)
CPU가 특정 주소를 참조할 때, 그 근처의 주소를 자주 참조하게 된다(Locality of Reference)는 특성을 말한다.
- 시간적 지역성(Time Locality): 최근에 접근한 데이터를 다시 접근할 가능성이 높다.
- e.g. 보통 컴퓨터 프로그램은 반복문이 많아 방금 읽은 코드를 다시 읽을 가능성이 높다.
- 공간적 지역성(Spatial Locality): 근처 주소를 연속적으로 접근할 가능성이 높다.
- e.g. 한 명령어 길이가 4byte면, 주소 1000번지에서 시작된 명령어를 읽고 곧바로 1004, 1008, … 등 그 인접 주소의 명령어들도 읽히게 된다.
이 원리 덕분에, 페이지 부재가 발생하면 그 인근의 데이터를 블록 단위로 미리 가져옴으로써 페이지 부재 확률을 줄일 수 있다.
Reference
