
1. 페이지 교체
처음 부팅했을 때에는 메모리가 비워져 있다가, 프로그램 실행에 따라 요구되는 페이지들을 backing store에서 가져와 메모리에 올린다. 이를 반복하다 보면 언젠가는 메모리가 가득 차게 된다.
메모리가 가득 차면 추가로 페이지를 가져오기 위해 어떤 페이지는 backing store로 몰아내고(page-out) 빈 자리에 페이지를 가져온다.(page-in)
1.1. Victim Page
이렇게 빈 자리를 위해 쫓아내는 페이지를 희생양 페이지(Victim Page)라고 한다.
Backing store로 페이지를 몰아낼 때, 즉 하드 디스크로 페이지를 보낼 때 해당 내용을 하드 디스크에 다시 써줘야 할까? 사실 페이지가 단순히 읽기 작업만 수행한 것이라면, 이미 하드 디스크에 있던 내용일 것이다. 그러나 만일 CPU에서 해당 페이지의 내용을 수정했다면 이를 하드 디스크에 다시 저장해야 한다.
하드 디스크는 일반적으로 속도가 느리기 때문에, 데이터를 쓰는 데 시간이 오래 걸린다. 따라서 가능한 한 수정되지 않은 페이지(victim)를 선택해 내보내는 것이 좋다. 수정 여부를 알기 위해 페이지 테이블에 Modified Bit(=Dirty Bit)를 추가하여 검사한다.
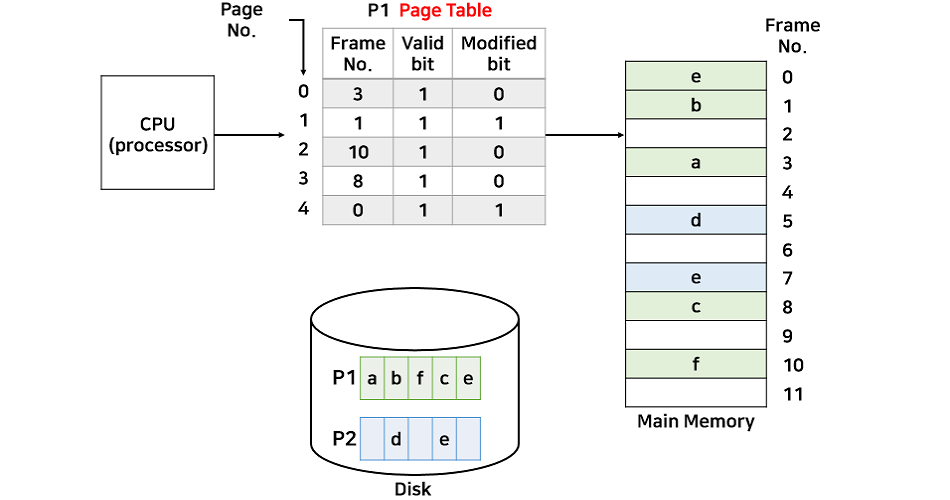
위의 그림은 Modified Bit를 추가한 페이지 테이블이다. 그런데 수정되지 않은 페이지는 0, 2, 3으로 복수 개가 존재한다. 어떤 페이지를 victim으로 설정해야 할까?
Random으로 설정하여 가장 간단하지만 성능 또한 제멋대로인 방법도 있을 거고, FIFO를 사용하여 가장 먼저 메모리에 올라온 페이지를 쫓아내는 방법도 있을 것이다.
이처럼 victim page를 어떤 기준으로 선정할 것인지 판단하는 알고리즘을 페이지 교체 알고리즘(Page Replacement Algorithms)이라고 한다.
2. 페이지 교체 알고리즘
페이징에서는 byte보다 페이지 단위가 중요하다. CPU가 낸 주소를 페이지 넘버와 로 나눌 수 있는데, 이 페이지 넘버를 통해 내가 읽으려는 페이지가 메인 메모리의 어느 주소에 위치하는지 알 수 있기 때문이다.
CPU 주소 = 100 101 102 432 612 103 104 611 612
Page No. = 1 1 1 4 6 1 1 6 6위의 예시에서 Page size = 100byte일 경우 페이지 번호는 1, 1, 1, 4, 6, 1, … 이 된다. (offset은 0, 1, 2, 32, 12, 3, …)
1번 페이지가 Page Fault가 나서 하드 디스크에서 이를 가져온다. 이 뒤에 바로 1번 페이지를 읽으면 절대 Page Fault가 나지 않는다. 이처럼 페이지 번호 중에서 바로 이어지는 번호는 스킵하고 읽는 것을 페이지 참조열(Page Reference String)이라고 한다.
Page Reference String = 1 4 6 1 62.1. FIFO(First-In First-Out)
FIFO(First-In, First-Out) 페이지 교체 알고리즘은 가장 먼저 메모리에 올라온 페이지를 가장 먼저 내보내는 방식으로 동작한다. 매우 간단한 방식이며, 페이지가 메모리에 올라온 순서를 그대로 유지하여 오래된 페이지를 우선적으로 교체한다.
해당 알고리즘의 아이디어는 가장 처음 메모리에 올라온 페이지는 주로 프로그램 초기화와 관련된 코드나 데이터를 담고 있을 가능성이 높다는 가정이었다.
e.g. 자바와 같은 언어에서는 객체가 생성될 때 생성자 메서드가 실행되며, 이는 한 번만 실행된다.
이처럼 초기화 코드는 대개 프로그램 초기에 한 번만 사용되고, 이후에는 재사용될 필요가 적다. 따라서 메모리에 가장 먼저 올라온 페이지는 초기화에 필요한 코드나 데이터를 담고 있을 가능성이 크다고 판단해 가장 처음 메모리에 올라온 페이지를 교체 대상으로 선택하는 것이 합리적이라 생각되어 고안된 것이다.
2.1.1. 예제
페이지 참조열 = 7 0 1 2 0 3 0 4 2 3 0 3 2 1 2 0 7 0 1
# of frames = 3| Page-in | 프레임 | First Page | Page Fault |
|---|---|---|---|
| 7 | {7} | 7 | 1 |
| 0 | {7, 0} | 7 | 2 |
| 1 | {7, 0, 1} | 7 | 3 |
| 2 | {2, 0, 1} | 0 | 4 |
| 0 | {2, 0, 1} | 0 | |
| 3 | {2, 3, 1} | 1 | 5 |
| 0 | {2, 3, 0} | 2 | 6 |
| 4 | {4, 3, 0} | 3 | 7 |
| 2 | {4, 2, 0} | 0 | 8 |
| 3 | {4, 2, 3} | 4 | 9 |
| 0 | {0, 2, 3} | 2 | 10 |
| 3 | {0, 2, 3} | 2 | |
| 2 | {0, 2, 3} | 2 | |
| 1 | {0, 1, 3} | 3 | 11 |
| 2 | {0, 1, 2} | 0 | 12 |
| 0 | {0, 1, 2} | 0 | |
| 7 | {7, 1, 2} | 1 | 13 |
| 0 | {7, 0, 2} | 2 | 14 |
| 1 | {7, 0, 1} | 7 | 15 |
최종적으로 Page Fault는 15번 발생한다.
예제를 보면 알 수 있듯, 직전에 내보낸 페이지가 다시 필요한 경우가 있다. 단순히 처음 들어온 페이지를 Page-out하는 구조이기 때문에 이와 같은 경우 비효율적이라는 것을 알 수 있다.
2.1.2. Belady’s Anomaly
일반적으로 메인 메모리의 용량이 작을수록 Page Fault가 더 자주 발생할 가능성이 크다. 메모리에 적재할 수 있는 페이지의 수가 제한적이기에 필요한 페이지를 자주 교체해야 하기 때문이다.
그러나 FIFO(First-In, First-Out)를 사용할 때, 메모리의 프레임 수가 증가함에 따라 페이지 폴트 횟수가 오히려 증가하는 현상이 발생할 수 있다. 이 현상을 Belady's Anomaly라고 한다.
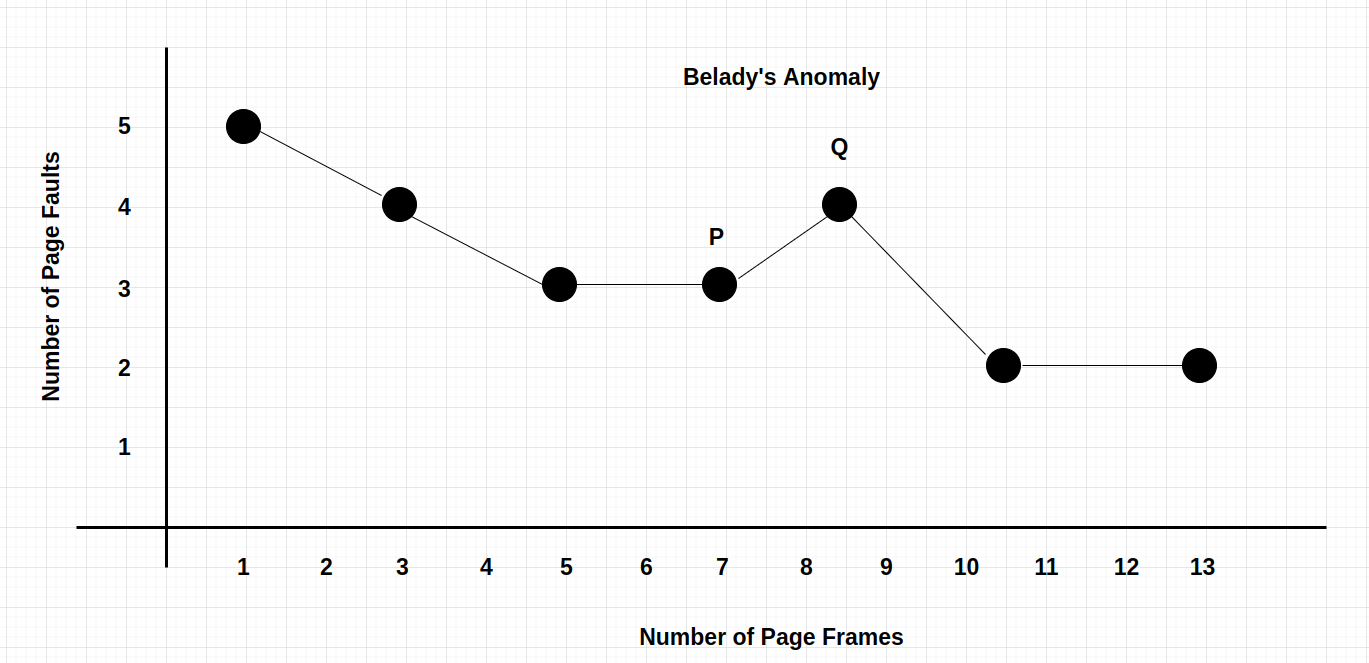
Belady's Anomaly는 FIFO 알고리즘의 특성상 발생하는데, 이는 페이지 참조열이 특정한 패턴을 가질 때 주로 나타난다.
e.g. 페이지 참조열이 순환적이거나 일정한 패턴을 반복하는 경우, FIFO는 초기의 오래된 페이지를 반복적으로 교체하며 더 많은 프레임을 할당받았음에도 불구하고 PF가 증가한다.
이러한 이유로 FIFO는 단순한 알고리즘이지만, 모든 상황에서 최적의 성능을 보장하지는 않는다.
2.2. Optimal(OPT)
위에서 언급한 FIFO의 문제점들을 해결하기 위해, 앞으로 가장 오랫동안 사용되지 않을 페이지를 victim으로 선택하는 방법이 있다. 이 방식을 사용하면 동일한 페이지 참조열과 동일한 프레임 개수에서 Page Fault가 9번 발생하게 된다.
그러나 이 방식은 unrealistic하다. 실제 컴퓨터가 실행될 때, 앞으로 어떤 페이지가 사용되지 않을지 미래를 알 수 없기 때문이다. 따라서 알고리즘으로는 설명할 수 있으나 현실에서 적용하기는 어렵다.
cf) CPU 스케줄링의 Shortest Job First(SJF) 알고리즘
이를 통해 우리는 앞으로 사용되지 않을 페이지를 예측하는 것이 중요하다는 것을 알 수 있다. 해당 아이디어를 가져가면서 realistic한 방법은 없을까?
2.3. Least-Recently-Used(LRU)
미래를 정확히 예측할 수는 없지만 과거를 보면 대략 짐작할 수는 있다. 과거에 시험을 잘 본 사람은 앞으로의 시험을 잘 볼 확률이 높듯 말이다.
LRU는 최근에 가장 오랫동안 사용되지 않은 페이지를 victim으로 설정하는 방식이다. 아이디어는 최근에 사용되지 않았으면 앞으로도 사용될 일이 적을 것이라는 가정이다. 단, ‘최근’의 일이어야만 영향을 미친다고 본다. 유치원 때 공부를 잘했다고 성인이 되어서도 반드시 공부를 잘하는 것은 아닌 것과 비슷하다.
이 방식을 사용하면 동일한 페이지 참조열과 동일한 프레임 개수에서 Page Fault가 12번 발생하게 된다. OPT보다는 많고, FIFO 보다는 적다. OPT는 가장 이상적인 방법이나 적용이 어렵고, FIFO는 가장 간단하나 성능이 좋지 않고 메모리가 증가헀음에도 PF가 증가하는 기현상이 있어 대부분의 컴퓨터는 LRU를 채택한다.
2.4. 교체 방식
2.4.1. Global replacement
메모리 상의 모든 프로세스를 대상으로 하여 victim을 선택하는 방법이다. 모든 프로세스의 메모리 자원을 공유하는 방식으로, 특정 프로세스의 페이지 폴트가 발생할 때 다른 프로세스의 페이지를 희생양으로 선택할 수 있다.
2.4.2. Local Replacement
특정 프로세스의 메모리 공간에서만 victim을 선택하는 방법이다. 각 프로세스가 할당받은 메모리 내에서만 페이지 교체가 이루어지도록 제한한다.
e.g. 의 5번 페이지에서 Page Fault가 발생했을 때, 의 페이지들에 한정하여 FIFO, LRU 등과 같은 알고리즘을 적용해 victim을 선택한다.
💡 Global vs Local Replacement
Global replacement가 대개 더 효율적이다. 이는 모든 프로세스의 페이지를 대상으로 선택할 수 있기 때문에, 시스템 전체적으로 최적의 victim을 선택할 가능성이 높아지기 때문이다.
반면, Local replacement는 특정 프로세스의 페이지에만 제한되기 때문에, 선택의 폭이 좁아져 전체 시스템 성능이 저하될 수 있다.
정리하자면, Global replacement는 시스템 자원의 전반적인 효율성을 높이는 반면, Local replacement는 각 프로세스의 독립성을 보장하는데 더 유리하다.
Reference
