[소회] 어제 백준에서 N-Queens 문제를 붙잡고 2~3시간 고민하면서 생각이 정말 많아졌었다.
튜플로 접근하고 그럴듯한 해를 찾았다고 생각했는데, 결국 시간초과의 늪에서 빠져나오지 못하고 구글의 힘을 빌리게 되었다. 가장 대표적인 솔루션을 보자마자, 아...! 대학교 전공 수업 때 똑똑한 친구들이 기가 막힌(+ 동시에 간결한) 솔루션을 가져올 때 느낌을 강하게 느꼈다. 동시에 알고리즘 문제를 푼다는 건, 마치 '고등학교 수학 문제 풀기와 수학 전공 문제 푸는 것 사이 그 어딘가'에 있음을 느끼기도 했다.
해를 찾아보기 전까지 생각했던 로직이 크게 몇가지 있었는데,
(1) 하나씩 다 대입하면서 체크해보자
(2) 그렇지만 literally '다 대입'이 아닌, n번째 행을 체크할때는 1~n-1행에 놓인 queen들을 의식하면서 체크해보자
(2-2) 이전에 놓인 queen들을 의식하다보면, n번째 queen을 놓을 때 굳이 확인하지 않아도 되는 열들이 있을 것이다
누구나 생각할 수 있는 로직이고, 역시나 코딩으로 이를 구현하는 건 다른 얘기이니... 꽤나 애를 먹었었다.
구현하는 과정에서 당연하게 생각했던 것은,(+ 결과적으로는 더 나은 방법이 있었던 것)
queen의 위치는 (x,y)로 나타나야 하므로 element 2개짜리 list or tuple, dictionary smth 형식이어야 한다는 것.
위의 형식으로 함수를 짜다보면 인덱스 고민+ 늘어나는 for문들 때문에, 분명 더 간결한 방법이 있겠다는 생각을 할 수 밖에 없었다. 자연스레 코딩까지의 시간도 오래 걸렸고. 사실 아직도 내 솔루션이 왜 틀렸는지는 잘 모르겠다ㅎㅎ
어쨌거나 좋은 솔루션을 내 것으로 만드는 것도 훌륭한 배움의 과정이므로, 관련한 알고리즘 몇가지를 공부해보기로 했다.
- 알고리즘 공부 3주차에 들어서니, 그래프와 더불어 DFS, BFS를 다룰 일이 생겼다. 그래서 해당 포스트에 이어서 공부 내용을 정리하고자 한다.
DFS (Depth-First-Search;깊이우선탐색)

찾고 싶은 노드가 있으면, 최대한 한 방향으로 쭉 가다가 끝에 도달했는데도 못 찾았다면, 직전 '갈림길'로 와서 다른 방향으로 쭉 탐색을 진행하는 방식. '갈림길' 표식이 있으므로, 백트랙킹 도중에 해당 노드가 적합하지 않다는 판단이 들면, 아래에 있는 leaf nodes를 모두 날려버릴 수 있다.(굳이 탐색하지 않아도 된다;가지치기;)
좀 더 비유적으로 "DFS = 미로찾기" 라고 생각하면 된다.
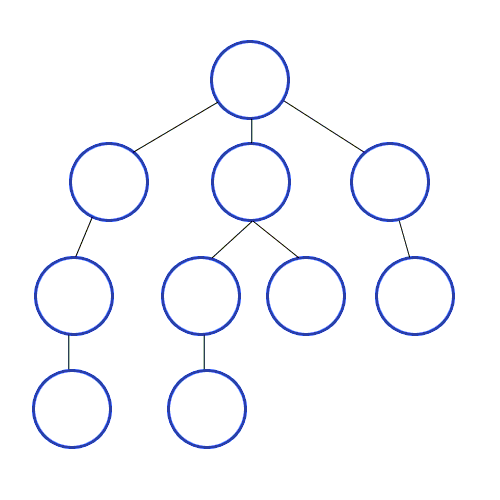
DFS의 데이터 저장 구조
그림에서 알 수 있듯 LIFO의 구조이며, 이에 가장 적합한 것은 'Stack'구조이다.(다른 개념으론 'Queue'가 있다.) + 재귀를 사용해서 표현하기도 한다.
저장 과정 & 탐색 과정
(출처1: https://5-ssssseung.tistory.com/33)
(출처2: https://gmlwjd9405.github.io/2018/08/14/algorithm-dfs.html)
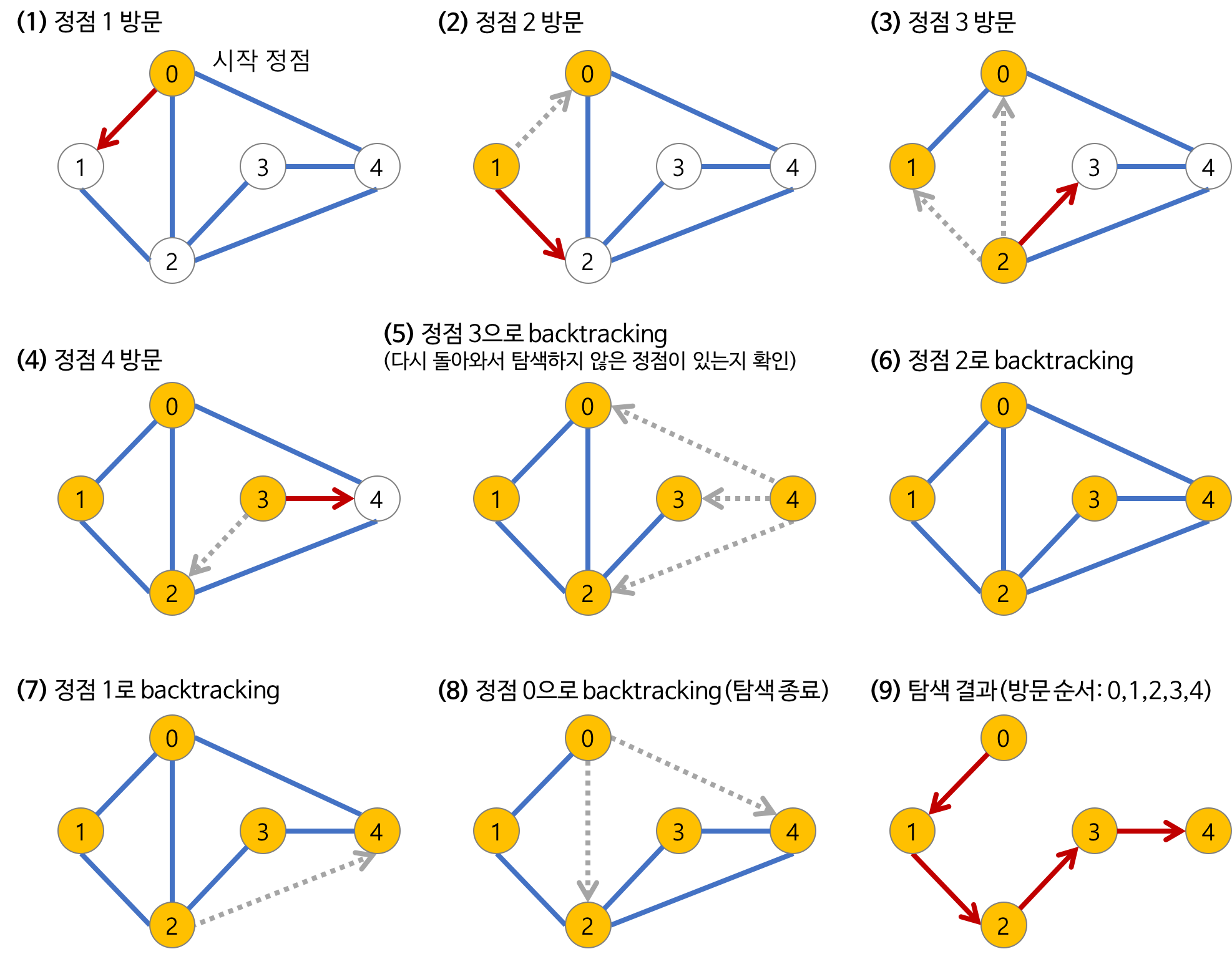
탐색에서의 핵심은, '어떤 노드를 방문했었는지 여부를 반드시 체크' 해야된다는 것이다.
위 출처2를 참고하면 단번에 이해가 가능하다. 또한 github에 업로드한 코드를 보아도, 재귀함수 호출 이전에 리스트에 값을 넣는 행위가 방문 여부 체크와 같다는 것을 알 수 있다.
간단한 psuedo code
def dfs(graph:Dict, start:int): # Dict 자료형 형태로 준다. key는 노드, value는 인접노드를 가리킨다.
visited = {i:False for i in graph.keys()} # 방문 배열. visited[node] = True이면 node는 방문이 끝난 상태이다.
def search(current:int): # 재귀함수 정의
visited[current] = True # current 방문
for nxt in graph[current]: # current의 인접 노드를 확인한다. 이 노드를 nxt라고 하자.
if not visited[nxt]: # 만일 nxt에 방문하지 않았다면
search(nxt) #nxt 방문
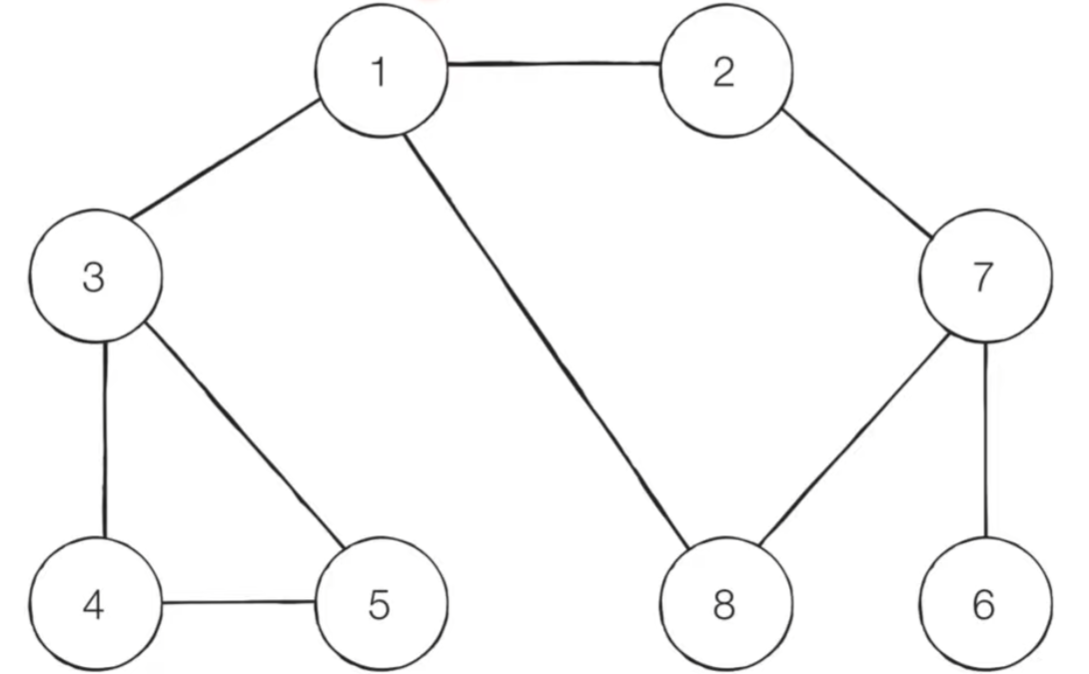
search(start)DFS 동작 예시(재귀함수)
- 방문기준: 번호가 낮은 인접노드부터
- 탐색순서: 1 - 2 - 7 - 6 - 8 - 3 - 4 - 5
# DFS 메서드 정의
def dfs(graph, v, visited):
# 현재 노드를 방문처리
visited[v] = True
print(v, end= ' ')
# 현재 노드와 연결된 다른 노드를 재귀적으로 방문
for i in graph[v]:
if not visited[i]:
dfs(graph, i, visited)
# 연결리스트
graph = [[], [2, 3, 8], [1, 7], [1, 4, 5], [3, 5], [3, 4], [7], [2, 6, 8], [1, 7]]
# 각 노드가 방문된 정보를 표현 (1차원 리스트)
visited = [False] * 9
# 정의된 DFS 함수 호출
dfs(graph, 1, visited)시간 복잡도
인접리스트: O(V+E);
BFS(Breadth-First-Search;너비우선탐색)
노드로부터 인접한 노드들을 먼저 방문하므로, 시작 노드로부터 멀수록 늦게 탐색한다. 그래서 최단 경로를 찾는 문제/임의의 경로 찾기 문제에서 자주 쓰이는 알고리즘이다.
dfs와 다르게, 재귀로 동작하지 않는다는 특징이 있다. 또한 그래프 탐색 시에 어떤 노드를 방문했었는지 여부를 반드시 검사해야 한다. 'Prim', 'Dijkstra'와 유사하다.
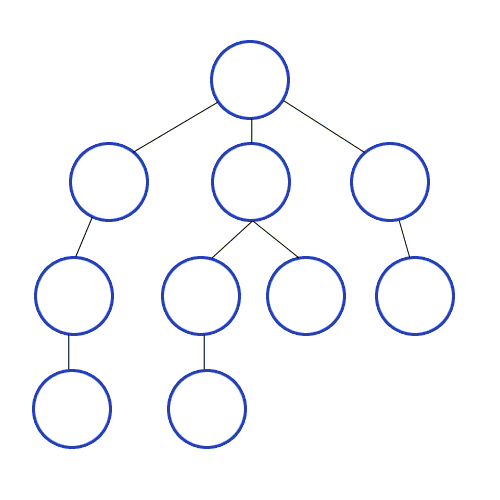
BFS의 데이터 저장 구조
FIFO원리를 적용하기 때문에 'Queue'를 사용해서 구현한다. 노드를 방문할 때, 가장 가까운 노드들을 queue에 넣는다.
저장 과정 & 탐색 과정
(출처1: https://gmlwjd9405.github.io/2018/08/15/algorithm-bfs.html)
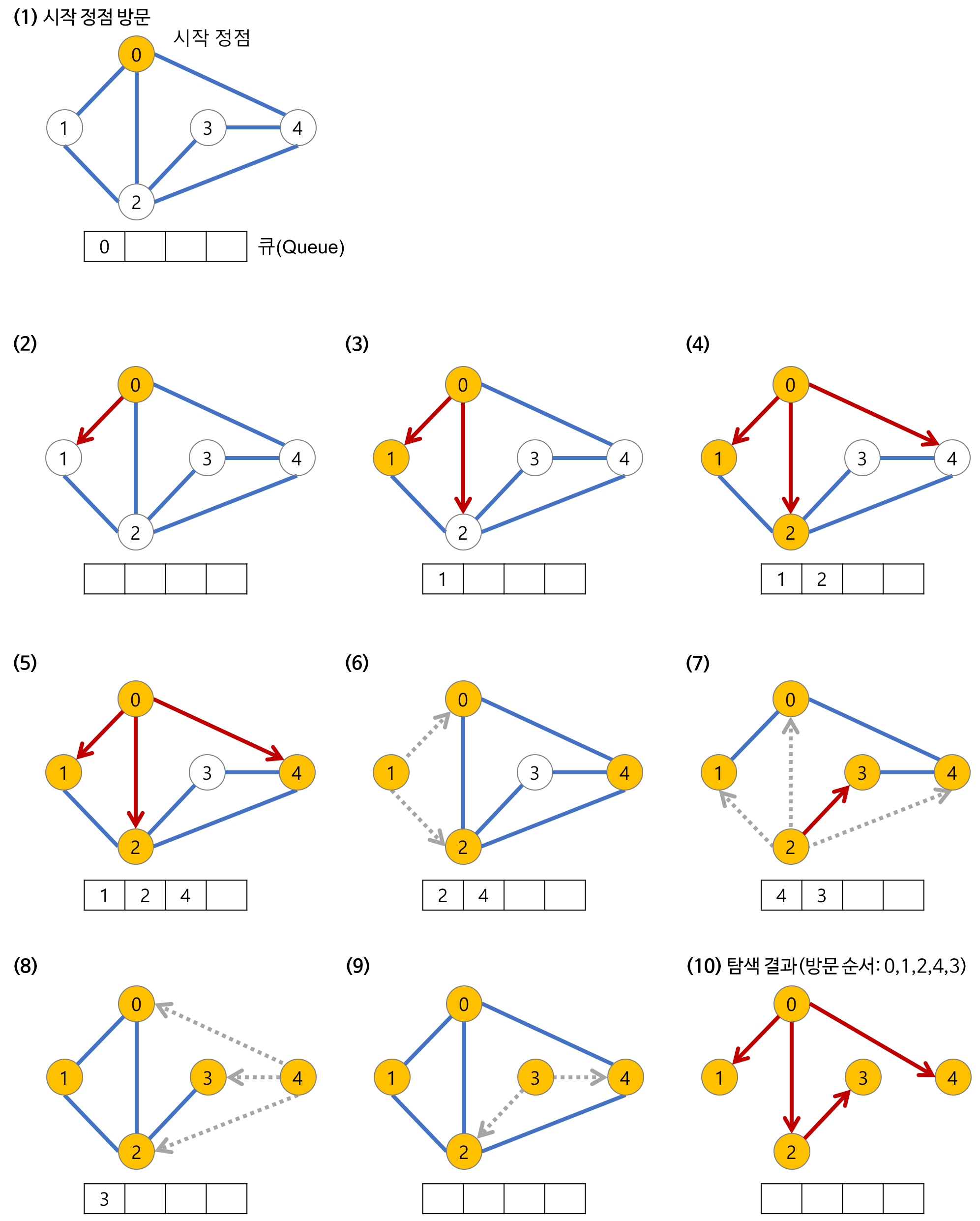
- 시작노드 방문
- 큐에 방문된 노드를 삽입(enqueue)
- 큐에서 꺼낸 노드와, 인접한 노드들을 차례로 방문.
- 큐에서 꺼낸 노드 방문
- 큐에서 꺼낸 노드와 인접한 노드들 모두 방문
- 인접한 노드 없으면, 큐의 앞에서 노드 꺼냄.(dequeue) - 큐에 방문된 노드 삽입(enqueue)
- 큐 소진까지 계속.
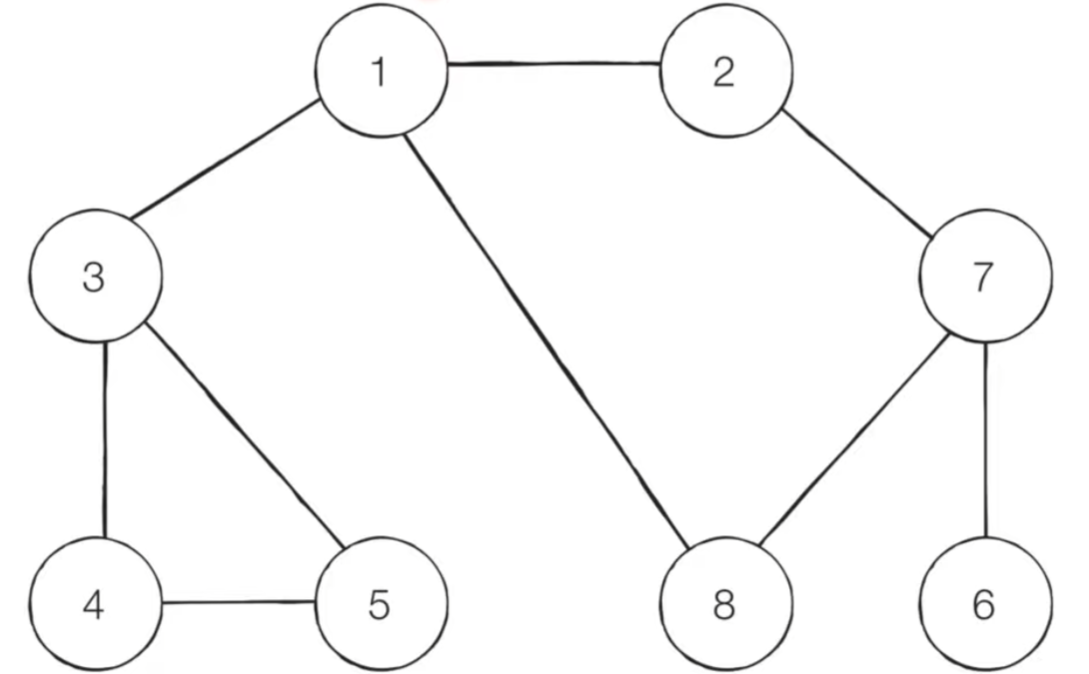
BFS 동작 예시(재귀로 구현 불가능!)
- 방문기준: 번호가 낮은 인접노드부터
- 탐색순서: 1 - 2 - 3 - 8 - 7 - 4 - 5 - 6
from collections import deque
# BFS 메서드 정의
def bfs(graph, start, visited):
# 큐(Queue) 구현을 위해 deque 라이브러리 사용
q = deque()
q.append(start)
# 현재 노드를 방문처리
visited[start] = True
# 큐가 빌 때까지 반복
while q:
# 큐에서 하나의 원소를 뽑아 출력하기
v = q.popleft()
print(v, end=' ')
# 아직 방문하지 않은 인접한 원소들을 큐에 삽입
for i in graph[v]:
if not visited[i]:
q.append(i)
visited[i] = True
# 연결리스트
graph = [[], [2, 3, 8], [1, 7], [1, 4, 5], [3, 5], [3, 4], [7], [2, 6, 8], [1, 7]]
# 각 노드가 방문된 정보를 표현 (1차원 리스트)
visited = [False] * 9
# 정의된 DFS 함수 호출
bfs(graph, 1, visited)Back-Tracking
모든 경우의 수를 전부 따져서 탐색하는 알고리즘.
BFS, DFS 등에 '쓰이는' 알고리즘이다. 두 개가 같다고 생각하면 안 된다. 근데 조금 파다보니, 개념적으로 이해만 하면 되지, 굳이 단어의 의미를 구분지어야 될 필요성은... 아직은 못 느낀다. 특히 코딩에선 주어진 상황, 문제를 풀 수 있으면 됐지, 굳이 definition을 알 필요는 없지 않을까?
++ for문으로는 확인이 불가한 경우에 쓰인다. (깊이가 달라질 때)
