📕TSR을 시작하게 된 계기
이전에 Craft와 deep-text-recognition-benchmark를 통해 OCR을 진행 한 적이 있다.
OCR 결과인 text 데이터를 가지고 NLP에 적용시켜 특정 필드만 추출해 보려고 하였다.
여기서 발생한 문제 중 문서에 아래와 같은 Table이 있을 때
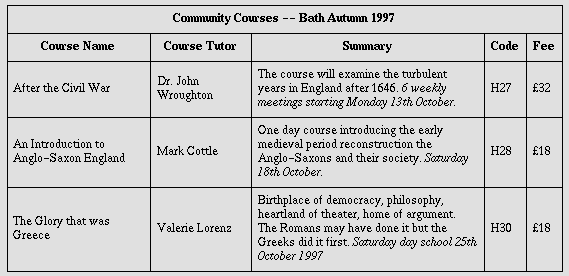
Summary부분에 3줄짜리 텍스트 영역에 대한 인식 결과가 Data Cell단위로 출력 되는 것이 아니라 왼쪽에서 오른쪽으로 가로 라인을 따르며 결과가 출력되기 때문에 NLP를 통해 인식하려고 할 때 맥락에 맞지 않는 엉뚱한 텍스트가 나열되어 나오는 경우가 있었다.
출력 예시) "After the Civil War Dr.John The course will examine the turbulent H27 €32 Wroughton years in England after 1646. 6 weekly"
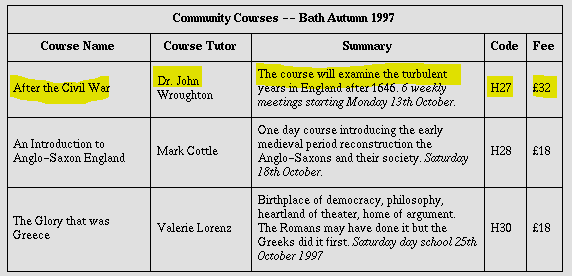
이런 식으로 cell 단위가 아닌 가로라인의 순서대로 출력되는 경우가 있었다.
NLP를 진행하려면 의미있는 텍스트의 묶음으로 결과가 출력 되어야 더욱 일관성 있고 관련있는 텍스트가 나열되어 정확한 NLP 구조 분석이 가능하다. 따라서 Cell단위로 의미있는 데이터를 추출하기 위해 TSR을 도입해 보았다.
1. microsoft-TATR 👉 참고
헤더 영역의 빈 cell이 과도하게 분할되는 현상을 해결하기 위한 알고리즘이다.
- 장점
- Column과 Row단위로 라벨링 되어있어 행, 열의 그룹화가 가능하다.
- Header와 SubHeader도 구분이 가능하다. - 단점
- Detection모델의 성능이 PubTables-1m 데이터에서만 높다.
- 기존 문제점인 병합된 Cell에 대한 인식이 헤더 부분에서만 가능하다.
- Column과 Row가 일정한 격자모양 즉, 테이블의 논리적 구조에 가까워야 인식이 잘된다.
2. CasCadeTabNet 👉 참고

CascadTabNet은 Table Detection과 Recognition을 동시에 진행하는 End to End방식을 제공 해 준다.
문서 내에서 테이블 영역을 탐지하고, 해당 테이블이 Bordered Table인지 Borderless Table인지 구분 해 주고, Borderless Table이라면 각 text영역을 인식하여 테이블의 구조를 파악 해 주는 알고리즘이다.

Borderless Table에서 text 영역을 잘 찾기 위해 Dilation기법을 통해 text 객체를 두껍게 하고, 글자부분을 검은 픽셀의 흐릿하고 번지는 이미지로 mask처리를 하여 Text 영역을 탐지하는 방식이다.
- 장점
- End To End모델로 TSR 단계가 간소화 될 수 있다.
- 단점
- 제공되고 있는 Base모델은 Borderless인 경우에만 text영역에 대한 인식을 한다.
- 빈 영역에 대한 인식은 하지 않기 때문에 정확한 테이블 구조 분석이라고 보기 어려울 수 있다.
3. Multi-Type-TD-TSR 👉 참고
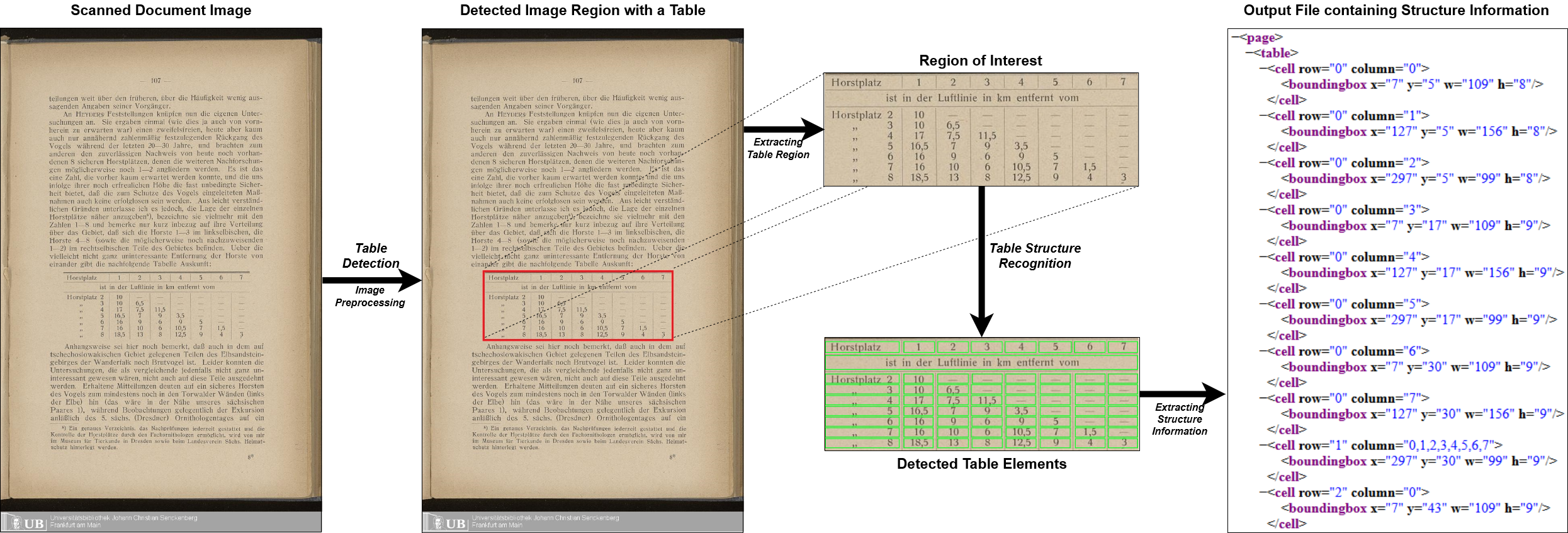
Multi-Type-TD-TSR은 Detection된 Table의 3가지 모양에 따라 분기가 나뉘게 된다. 3가지 방식은 모두 Erosion/Dilation 기법을 통해 진행된다.
1. Bordered Tables
Table 경계선이 있는 경우 Erosion 기법을 통해 모든 텍스트를 지우고 경계선의 가로, 세로 라인을 추출한 뒤 Dilation을 통해 경계선을 팽창시켜서 테이블의 구조를 복구시킨다.
추출한 가로, 세로의 경계선 이미지를 결합시켜 셀 이미지를 얻으면 Opencv의 외곽선 검출 함수를 통해 테이블의 cell을 추출한다.
2. UnBordered Tables
경계선이 없는 테이블은 1번과 유사하게 동작하지만 가장 얇은 가로와 세로의 경계선을 추출하는 것이 아니라 text가 포함되지 않는 가로와 세로의 빈 영역을 찾고 해당 이미지를 결합하여 마찬가지로 외곽선 검출 함수를 통해 테이블 cell을 추출한다.
3. Partially Bordered Tables
부분적으로 경계선이 있는 테이블은 1번과 같은 방식으로 가로와 세로의 경계선을 찾고, 해당 경계선을 없앤다.
1번 방식으로 경계선을 없애면 UnBordered Table이 되기 때문에 이후에는 2번과 같은 방식으로 Table cell 영역을 추출한다.
-
장점
- CasCadeTabNet은 빈 cell의 경우 탐지가 불가능 했지만 Multi-Type알고리즘은 테이블의 경계선을 기분으로 TSR을 진행하기 때문에 빈 cell이 있어도 정확한 구조 분석이 가능하다.
- data cell에 병합된 부분이 있어도 cell단위로 추출이 가능하다.
- 보통 Table Detection과 Recognition단계 모두 딥러닝 모델을 사용하지만 Multi-Type는 이미지처리 알고리즘을 사용하기 때문에 Recognition시 GPU를 필요로 하지 않는다.
- 더 정확한 구조분석을 위해 각종 파라미터들을 세부 조정할 수 있다.
-
단점
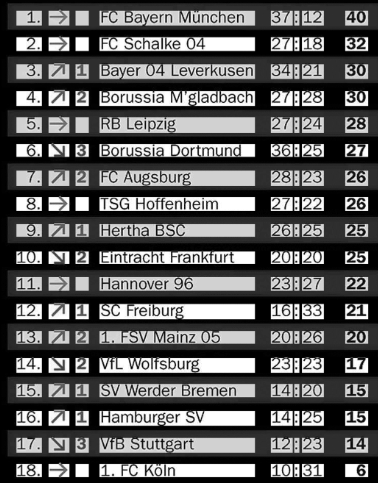
-
위 그림과 같이 37:12는 동일한 cell 영역이지만 text사이의 빈 공간이 존재하면 해당 영역이 과도하기 분할되는 현상이 있을 수 있다.
-
노이즈가 많을 경우 정확한 인식이 안되는 경우가 있을 수 있다.
4. LGPMA 👉 참고
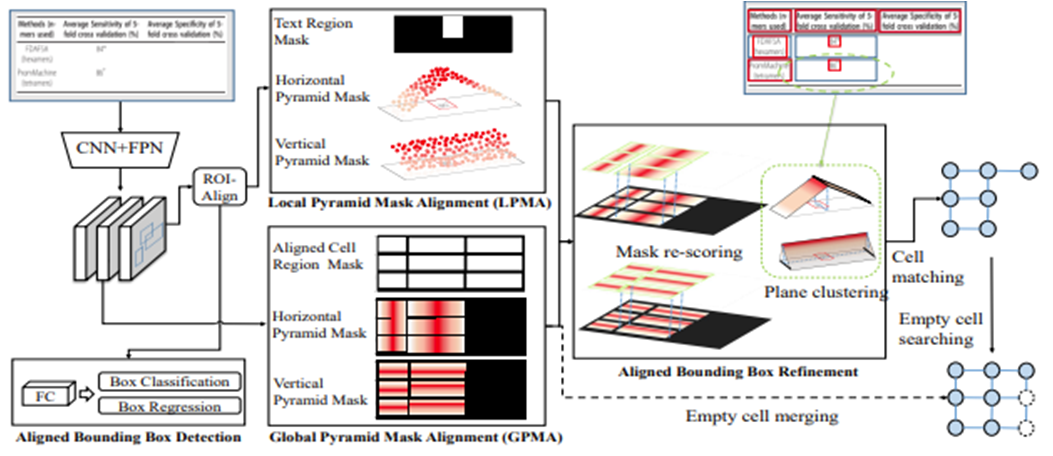
LGPMA는 Local Global Pyramid Mask Alignment의 약자로 LPMA와 GPMA 두 가지 단계를 따른다.
LPMA는 텍스트 영역감지 및 수평 수직 피라미드 마스크를 통해 학습하고
GPMA는 비어있지 않은 셀의 모든 경계선에 대해 학습하고 빈 셀에 대한 추가학습이 진행된다.
최종적으로 Cell 탐지, 빈 셀 병합의 순서로 테이블 구조분석이 진행된다.
- 장점
- 빈 셀을 포함하여 학습하기 때문에 더 정확한 cell 영역을 탐지할 수 있다. - 단점
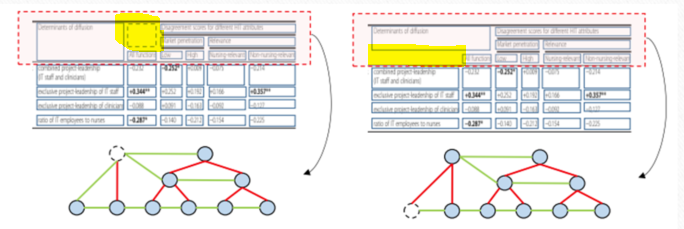
- 위 이미지의 형광표시 한 것처럼 빈 셀의 위치를 어떻게 정하냐에 따라서 결과가 달라질 수 있다.
최종선택
우선 4가지 TSR 방법론에 대해 논문을 읽어가며 장단점을 파악 해 보았다. 그 중 3번 째 방법인 Multi-Type-TD-TSR방식의 범용성이 넓기 때문에 해당 방법을 우선 채택하여 집중적으로 진행 해보려고 한다. 관련 내용은 추가로 포스팅 하도록 하겠다.
📗출처
-
Microsoft/TART : https://arxiv.org/pdf/2203.12555 / https://arxiv.org/pdf/2303.00716
-
Multi-Type-TD-TSR : https://arxiv.org/pdf/2105.11021
