Table Structure Recognition 테이블 감지 및 구조분석(TSR) - Multi-Type-TD-TSR
Table Structure Recognition
📗서론
TSR의 여러가지 방식 중 Multi-Type-TD-TSR에 대해 분석 해보겠다.
Multi-Type-TD-TSR소개
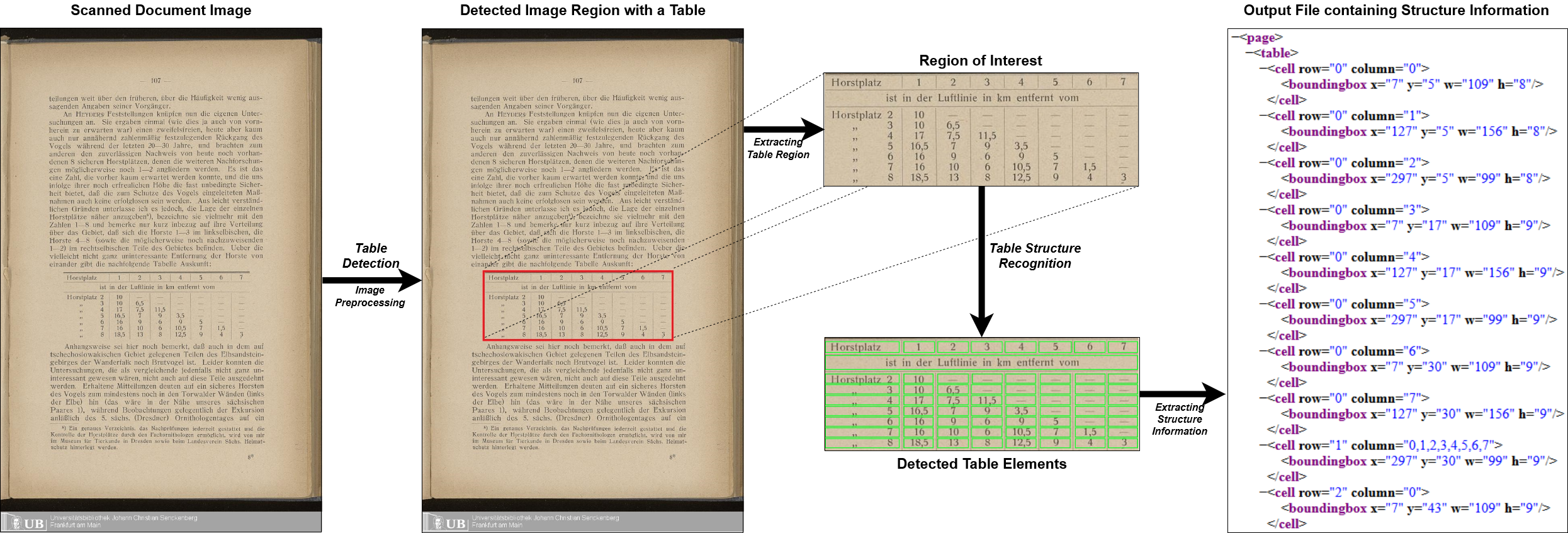
우선 Multi-Type-TD-TSR이 가장 마음에 들었던 이유는 GPU에 의존하지 않고 테이블의 구조분석이 가능하다는 점이 강점이라고 생각 되었다.
이 알고리즘을 소개하기 전에 알고가면 좋은 Erosion과 Dilation방식에 대해 설명하겠다.
1. Erosion기법
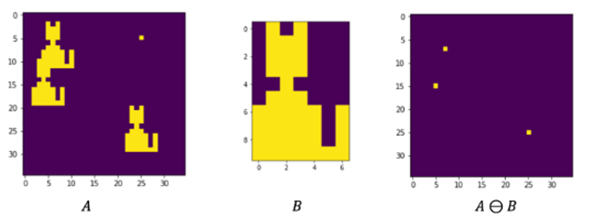
A라는 원본 이미지에 B라는 kernel을 슬라이스 시켜 B와 동일한 픽셀이 있으면 해당 영역의 중앙을 1로하고 나머지 영역을 0으로하여 축소 시키는 기법이다. (AND연산)
예를들어 이런 테이블이 있을 때 가로라인을 제외하고 나머지를 없애고 싶을 때 (n,1)짜리 kernel을 원본 이미지에 적용 시키면 길이가 n이상인 가로선을 제외한 나머지 픽셀은 사라지게 된다.
2. Dilation기법
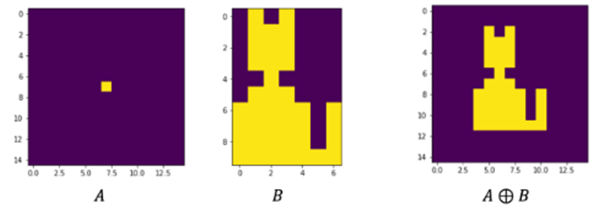
원본 이미지 A에 B라는 kernel을 슬라이스 시켜 OR연산을 통해 커널 사이즈만큼 팽창 시킨다.

예를들어 위의 그림과 같이 글자가 끊어져 있거나, 얇은 선들을 공백없이 이어주고 두껍게 하여 팽창시키는 역할을 한다.
위에서 Erosion기법을 통해 가로라인을 추출할 때 끊어지거나 1픽셀의 얇은 선들이 추출 되었는데 Dilation기법을 통해 끊어진 라인을 복구하고 두껍게 팽창시켜 테이블의 원래 구조로 복원시키기 위한 작업이 필요하다.
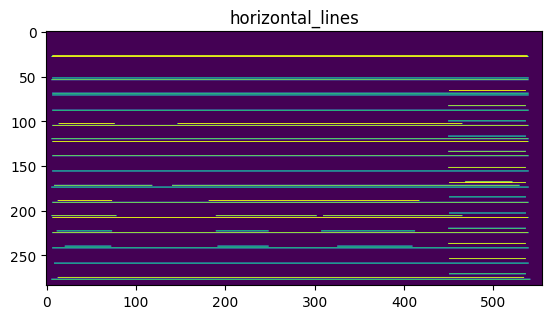
image_2를 Dilation기법을 통해 팽창시킨 결과이다.
3. Table Recognition
Multi-Type-TD-TSR의 테이블 구조분석은 Colab에서 demo코드로 제공 해주고 있다.
나는 Colab이 아니라 Jupyter에서 코드를 수정하며 테스트 해볼 예정이기 때문에 약간 수정된 코드를 통해 공유 하도록 하겠다.
3.1 개발환경
CUDA version : 11.2
torch version : 1.8.2- pip list
Package Version
---------------------------- --------------------
absl-py 1.3.0
addict 2.4.0
albumentations 1.4.7
aliyun-python-sdk-core 2.15.1
aliyun-python-sdk-kms 2.16.3
annotated-types 0.6.0
antlr4-python3-runtime 4.9.3
anyio 3.6.2
appdirs 1.4.4
argon2-cffi 21.3.0
argon2-cffi-bindings 21.2.0
asttokens 2.1.0
astunparse 1.6.3
asynctest 0.13.0
attrs 22.1.0
backcall 0.2.0
beautifulsoup4 4.11.1
black 21.4b2
bleach 5.0.1
cachetools 5.2.0
certifi 2019.11.28
cffi 1.15.1
chardet 3.0.4
charset-normalizer 3.3.2
cityscapesScripts 2.2.3
click 8.1.7
cloudpickle 3.0.0
codecov 2.1.13
colorama 0.4.6
coloredlogs 15.0.1
contourpy 1.0.6
coverage 7.5.1
crcmod 1.7
cryptography 42.0.7
cycler 0.11.0
Cython 3.0.10
dataclasses 0.6
dbus-python 1.2.16
debugpy 1.6.3
decorator 5.1.1
defusedxml 0.7.1
detectron2 0.6+cu111
emoji 2.11.1
entrypoints 0.4
exceptiongroup 1.2.1
executing 1.2.0
fairscale 0.4.13
fastjsonschema 2.16.2
filelock 3.14.0
flake8 7.0.0
flatbuffers 22.10.26
focal-loss 0.0.7
fonttools 4.38.0
future 1.0.0
fvcore 0.1.5.post20221221
gast 0.4.0
gdown 5.1.0
google-auth 2.14.1
google-auth-oauthlib 0.4.6
google-pasta 0.2.0
grpcio 1.50.0
h5py 3.7.0
humanfriendly 10.0
hydra-core 1.3.2
idna 2.8
imagecorruptions 1.1.2
imageio 2.33.1
importlib_metadata 7.1.0
importlib-resources 5.10.0
imutils 0.5.4
iniconfig 2.0.0
iopath 0.1.8
ipykernel 5.1.1
ipython 8.6.0
ipython-genutils 0.2.0
ipywidgets 8.0.2
isort 5.13.2
jedi 0.17.2
Jinja2 3.1.2
jmespath 0.10.0
joblib 1.4.2
jsonlines 4.0.0
jsonschema 4.17.0
jupyter 1.0.0
jupyter_client 7.4.7
jupyter-console 6.4.4
jupyter_core 5.0.0
jupyter-http-over-ws 0.0.8
jupyter-server 1.23.2
jupyterlab-pygments 0.2.2
jupyterlab-widgets 3.0.3
keras 2.11.0
kiwisolver 1.4.4
kwarray 0.6.18
lazy_loader 0.4
libclang 14.0.6
lxml 5.2.1
Markdown 3.4.1
markdown-it-py 3.0.0
MarkupSafe 2.1.1
matplotlib 3.6.2
matplotlib-inline 0.1.6
mccabe 0.7.0
mdurl 0.1.2
mistune 2.0.4
mmcv 1.4.0
mmcv-full 1.3.0
mmdet 2.28.1
mmengine 0.10.4
model-index 0.1.11
mypy-extensions 1.0.0
nbclassic 0.4.8
nbclient 0.7.0
nbconvert 7.2.5
nbformat 4.4.0
nest-asyncio 1.5.6
networkx 3.1
ninja 1.11.1.1
notebook 6.5.2
notebook_shim 0.2.2
numpy 1.24.4
oauthlib 3.2.2
omegaconf 2.3.0
opencv-python 4.9.0.80
opencv-python-headless 4.9.0.80
opendatalab 0.0.10
openmim 0.3.9
openxlab 0.0.38
opt-einsum 3.3.0
ordered-set 4.1.0
oss2 2.17.0
packaging 21.3
pandas 2.0.3
pandocfilters 1.5.0
parso 0.7.1
pathspec 0.12.1
pexpect 4.8.0
pickleshare 0.7.5
Pillow 9.3.0
pip 24.0
pkgutil_resolve_name 1.3.10
platformdirs 4.2.2
pluggy 1.5.0
portalocker 2.8.2
prometheus-client 0.15.0
prompt-toolkit 3.0.32
protobuf 3.19.6
psutil 5.9.4
ptyprocess 0.7.0
pure-eval 0.2.2
pyasn1 0.4.8
pyasn1-modules 0.2.8
pycocotools 2.0.7
pycodestyle 2.11.1
pycparser 2.21
pycryptodome 3.20.0
pydantic 2.7.1
pydantic_core 2.18.2
pydot 2.0.0
pyflakes 3.2.0
Pygments 2.13.0
PyGObject 3.36.0
pyparsing 3.0.9
pyquaternion 0.9.9
pyrsistent 0.19.2
PySocks 1.7.1
pytesseract 0.3.10
pytest 8.2.1
pytest-cov 5.0.0
pytest-runner 6.0.1
python-apt 2.0.0+ubuntu0.20.4.8
python-dateutil 2.8.2
pytz 2023.3.post1
PyWavelets 1.4.1
PyYAML 6.0.1
pyzmq 24.0.1
qtconsole 5.4.0
QtPy 2.3.0
regex 2024.4.28
requests 2.28.2
requests-oauthlib 1.3.1
requests-unixsocket 0.2.0
rich 13.4.2
rsa 4.9
scikit-image 0.21.0
scikit-learn 1.3.2
scipy 1.10.1
Send2Trash 1.8.0
setuptools 60.2.0
shapely 2.0.4
six 1.14.0
sniffio 1.3.0
soupsieve 2.3.2.post1
stack-data 0.6.1
tabulate 0.9.0
tensorboard 2.11.0
tensorboard-data-server 0.6.1
tensorboard-plugin-wit 1.8.1
tensorflow 2.11.0
tensorflow-estimator 2.11.0
tensorflow-io-gcs-filesystem 0.27.0
termcolor 2.1.0
terminado 0.17.0
terminaltables 3.1.10
threadpoolctl 3.5.0
tifffile 2023.7.10
tinycss2 1.2.1
toml 0.10.2
tomli 2.0.1
torch 1.8.2+cu111
torchaudio 0.8.2
torchvision 0.9.2+cu111
tornado 6.2
tqdm 4.65.2
traitlets 5.5.0
typing 3.7.4.3
typing_extensions 4.11.0
tzdata 2023.4
ubelt 1.3.5
urllib3 1.25.8
wcwidth 0.2.5
webencodings 0.5.1
websocket-client 1.4.2
Werkzeug 2.2.2
wheel 0.43.0
widgetsnbextension 4.0.3
wrapt 1.14.1
xdoctest 1.1.3
yacs 0.1.8
yapf 0.40.2
zipp 3.10.0다른 프로젝트도 존재하는 Docker Image라 여러가지 패키지들이 많지만 혹시 해당 코드를 실행할 때 의존성 문제가 있다면 위의 개발환경을 참고하여 버전을 맞춰주길 바란다.
3.2 TD-Base모델 다운
Base모델은 table_detection에서 다운 받을 수 있다.
3.3 경계선이 있는 테이블 코드
- 이미지 load 및 전처리
import cv2
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import csv
#from google.colab.patches import cv2_imshow
try:
from PIL import Image
except ImportError:
import Image
import pytesseract as tess
import pytesseract
def recognize_structure(img):
#tess.pytesseract.tesseract_cmd = 'C:/Program Files/Tesseract-OCR/tesseract.exe'
#print(img.shape)
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img_height, img_width = img.shape
#print("img_height", img_height, "img_width", img_width)
#cv2_imshow(img)
plt.title("img")
plt.imshow(img)
plt.show()
# thresholding the image to a binary image
# thresh, img_bin = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
img_bin = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 3, 5)
#cv2_imshow(img_bin)
plt.title("img_bin")
plt.imshow(img_bin)
plt.show()
# inverting the image
img_bin = 255 - img_bin
# cv2.imwrite('/Users/marius/Desktop/cv_inverted.png', img_bin)
# Plotting the image to see the output
plotting = plt.imshow(img_bin, cmap='gray')
plt.show()우선 Colab기준으로 작성 된 코드이기 때문에 Jupyter에는 cv2_imshow라는 함수를 제공 해주지 않아 plt함수를 통해 이미지를 보여주도록 수정하였다.
-
cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) : 이미지를 GRAY이미지로 불러온다.
-
cv2.adaptiveThreshold : 이미지를 2진화시키고 가우시안 노이즈를 주어 선분 영역을 찾기 쉽게 해준다.
# countcol(width) of kernel as 100th of total width
# kernel_len = np.array(img).shape[1] // 100
if img_height > 500:
kernel_len_ver = img_height // 60
elif img_height > 300:
kernel_len_ver = img_height // 50
else:
kernel_len_ver = img_height // 25
if img_width > 500:
kernel_len_hor = img_width // 50
else:
kernel_len_hor = img_width // 25
# Defining a vertical kernel to detect all vertical lines of image
ver_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (1, kernel_len_ver)) # shape (kernel_len, 1) inverted! xD
#print("ver", ver_kernel)
#print(ver_kernel.shape)
# Defining a horizontal kernel to detect all horizontal lines of image
hor_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (kernel_len_hor, 1)) # shape (1,kernel_ken) xD
#print("hor", hor_kernel)
#print(hor_kernel.shape)
# A kernel of 2x2
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (2, 2))
#print(kernel)
#print(kernel.shape)Detection되어 Crop된 Table 이미지의 사이즈가 클수도 있고 작을 수도 있는데 만약 사이즈가 클 때 이미지 사이즈에 너무 작은 수로 나누게 되면 추출 해야하는 가로, 세로 라인이 너무 짧은 상수가 되어 테이블 라인이 아닌 일반 글자의 가로, 세로 라인까지 추출되는 현상이 있어 사이즈 별로 분기를 나눌 수 있도록 수정하였다.
-
ver_kernel : cv2.getStructuringElement함수를 통해 (1, n)의 커널을 만든다. (수직선을 감지하는 커널)
-
hor_kernel : cv2.getStructuringElement함수를 통해 (n, 1)의 커널을 만든다. (수평선을 감지하는 커널)
# Use vertical kernel to detect and save the vertical lines in a jpg
image_1 = cv2.erode(img_bin, ver_kernel, iterations=3)
vertical_lines = cv2.dilate(image_1, ver_kernel, iterations=5)
cv2.imwrite("/Users/marius/Desktop/vertical.jpg", vertical_lines)
# Plot the generated image
#cv2_imshow(image_1)
plt.title("image_1")
plt.imshow(image_1)
plt.show()
#cv2_imshow(vertical_lines)
plt.title("vertical_lines")
plt.imshow(vertical_lines)
plt.show()
# Use horizontal kernel to detect and save the horizontal lines in a jpg
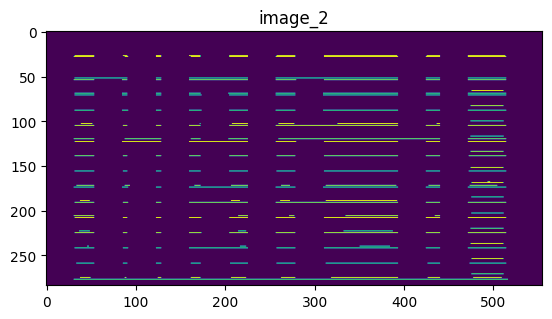
image_2 = cv2.erode(img_bin, hor_kernel, iterations=3)
horizontal_lines = cv2.dilate(image_2, hor_kernel, iterations=5)
# Plot the generated image
#cv2_imshow(image_2)
plt.title("image_2")
plt.imshow(image_2)
plt.show()
#cv2_imshow(horizontal_lines)
plt.title("horizontal_lines")
plt.imshow(horizontal_lines)
plt.show()수직, 수평선을 찾기 위해 erosion기법을 사용하고 테이블의 구조를 복구 시키기 위해 dilation기법을 사용한다.
-
image_1 = cv2.erode(img_bin, ver_kernel, iterations=3) : 이미지에서 수직선을 찾기 위해 원본 이미지에 ver_kernel을 슬라이스 시킨다.
-
vertical_lines = cv2.dilate(image_1, ver_kernel, iterations=5) : 추출한 수직선의 끊어지고 얇은 선을 원래의 구조로 팽창시킨다.
# Combine horizontal and vertical lines in a new third image, with both having same weight.
img_vh = cv2.addWeighted(vertical_lines, 0.5, horizontal_lines, 0.5, 0.0)
#cv2_imshow(img_vh)
plt.title("img_vh")
plt.imshow(img_vh)
plt.show()
#cv2_imshow(~img_vh)
plt.title("~img_vh")
plt.imshow(~img_vh)
plt.show()
# Eroding and thesholding the image
img_vh = cv2.erode(~img_vh, kernel, iterations=2)
#cv2_imshow(img_vh)
plt.title("img_vh")
plt.imshow(img_vh)
plt.show()
thresh, img_vh = cv2.threshold(img_vh, 128, 255, cv2.THRESH_BINARY )
#cv2_imshow(img_vh)
plt.title("img_vh")
plt.imshow(img_vh)
plt.show()
bitxor = cv2.bitwise_xor(img, img_vh)
bitnot = cv2.bitwise_not(bitxor)
# Plotting the generated image
#cv2_imshow(bitnot)
plt.title("bitnot")
plt.imshow(bitnot)
plt.show()수직, 수평선을 찾았으면 이를 하나로 합친다.
-
img_vh = cv2.addWeighted(vertical_lines, 0.5, horizontal_lines, 0.5, 0.0) : 수직, 수평선을 50:50의 비율로 하나로 합친다.
-
bitxor = cv2.bitwise_xor(img, img_vh) : (0,0) → 0, (1, 1) → 0 즉, 서로 다른부분을 출력한다. 기존 이미지와 추출한 수직, 수평라인이 겹치지 않는 경우에 출력한다.
-
bitnot = cv2.bitwise_not(bitxor) : Not연산을 적용하여 반전시킨다.
# Detect contours for following box detection
# cv함수를 통해 Box의 외곽선 좌표값을 반환
contours, hierarchy = cv2.findContours(img_vh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
#print(contours)
#print(len(contours))
#print(contours[0])
#print(len(contours[0]))
#print(cv2.boundingRect(contours[0]))
def sort_contours(cnts, method="left-to-right"):
# initialize the reverse flag and sort index
reverse = False
i = 0
# handle if we need to sort in reverse
if method == "right-to-left" or method == "bottom-to-top":
reverse = True
# handle if we are sorting against the y-coordinate rather than
# the x-coordinate of the bounding box
if method == "top-to-bottom" or method == "bottom-to-top":
i = 1
# construct the list of bounding boxes and sort them from top to
# bottom
boundingBoxes = [cv2.boundingRect(c) for c in cnts]
(cnts, boundingBoxes) = zip(*sorted(zip(cnts, boundingBoxes),
key=lambda b: b[1][i], reverse=reverse))
# return the list of sorted contours and bounding boxes
return (cnts, boundingBoxes)
# Sort all the contours by top to bottom.
contours, boundingBoxes = sort_contours(contours, method="top-to-bottom")-
cv2.findContours : 외곽선 검출 함수를 통해 박스 영역의 좌표를 map형태로 반환
-
cv2.boundingRect : 외곽선 좌표를 통해 박스의 (x, y, w, h) 값을 찾는 함수
-
sort_contours : 외곽선 좌표를 정렬하는 함수
# Creating a list of heights for all detected boxes
heights = [boundingBoxes[i][3] for i in range(len(boundingBoxes))]
# Get mean of heights
mean = np.mean(heights)
# Create list box to store all boxes in
box = []
# Get position (x,y), width and height for every contour and show the contour on image
#print("lencontours", len(contours))
for c in contours:
#x, y, w, h의 배열로 반환
x, y, w, h = cv2.boundingRect(c)
if (w < 0.9*img_width and h < 0.9*img_height):
image = cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
box.append([x, y, w, h])
#cv2_imshow(image)
plt.title("image")
plt.imshow(image)
plt.show()
# Creating two lists to define row and column in which cell is located
row = []
column = []
j = 0
#print("len box", len(box))
# Sorting the boxes to their respective row and column
for i in range(len(box)):
if (i == 0):
column.append(box[i])
previous = box[i]
else:
if (box[i][1] <= previous[1] + mean / 2):
column.append(box[i])
previous = box[i]
if (i == len(box) - 1):
row.append(column)
else:
row.append(column)
column = []
previous = box[i]
column.append(box[i])
#print(column)
#print(row)
# calculating maximum number of cells
countcol = 0
index = 0
for i in range(len(row)):
current = len(row[i])
if current > countcol:
countcol = current
index = i
#print("countcol", countcol)
# Retrieving the center of each column
#center = [int(row[i][j][0] + row[i][j][2] / 2) for j in range(len(row[i])) if row[0]]
center = [int(row[index][j][0] + row[index][j][2] / 2) for j in range(len(row[index]))]
#print("center",center)
center = np.array(center)
center.sort()
#print("center.sort()", center)
# Regarding the distance to the columns center, the boxes are arranged in respective order
finalboxes = []
for i in range(len(row)):
lis = []
for k in range(countcol):
lis.append([])
for j in range(len(row[i])):
diff = abs(center - (row[i][j][0] + row[i][j][2] / 4))
minimum = min(diff)
indexing = list(diff).index(minimum)
lis[indexing].append(row[i][j])
finalboxes.append(lis)
return finalboxes, img_bin-
heights = [boundingBoxes[i][3] for i in range(len(boundingBoxes))] : 검출된 모든 외곽선 박스들의 높이를 구하기
-
mean = np.mean(heights) :위에서 구한 높이의 평균 찾기
-
center = [int(row[index][j][0] + row[index][j][2] / 2) for j in range(len(row[index]))] : 각 column의 중심을 구함
-
center.sort() : 각 열의 중심을 크기 순으로 나열
-
이렇게 구한 mean과 center을 통해 정렬되지 않은 Box좌표를 왼쪽에서 오른쪽, 위에서 아래 순서로 정렬한다.
3.4 최종 코드
import cv2
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import csv
#from google.colab.patches import cv2_imshow
try:
from PIL import Image
except ImportError:
import Image
import pytesseract as tess
import pytesseract
def recognize_structure(img):
#tess.pytesseract.tesseract_cmd = 'C:/Program Files/Tesseract-OCR/tesseract.exe'
#print(img.shape)
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img_height, img_width = img.shape
#print("img_height", img_height, "img_width", img_width)
#cv2_imshow(img)
plt.title("img")
plt.imshow(img)
plt.show()
# thresholding the image to a binary image
# thresh, img_bin = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
img_bin = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 3, 5)
#cv2_imshow(img_bin)
plt.title("img_bin")
plt.imshow(img_bin)
plt.show()
# inverting the image
img_bin = 255 - img_bin
# cv2.imwrite('/Users/marius/Desktop/cv_inverted.png', img_bin)
# Plotting the image to see the output
plotting = plt.imshow(img_bin, cmap='gray')
plt.show()
# countcol(width) of kernel as 100th of total width
# kernel_len = np.array(img).shape[1] // 100
if img_height > 500:
kernel_len_ver = img_height // 60
elif img_height > 300:
kernel_len_ver = img_height // 50
else:
kernel_len_ver = img_height // 25
if img_width > 500:
kernel_len_hor = img_width // 50
else:
kernel_len_hor = img_width // 25
# Defining a vertical kernel to detect all vertical lines of image
ver_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (1, kernel_len_ver)) # shape (kernel_len, 1) inverted! xD
#print("ver", ver_kernel)
#print(ver_kernel.shape)
# Defining a horizontal kernel to detect all horizontal lines of image
hor_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (kernel_len_hor, 1)) # shape (1,kernel_ken) xD
#print("hor", hor_kernel)
#print(hor_kernel.shape)
# A kernel of 2x2
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (2, 2))
#print(kernel)
#print(kernel.shape)
# Use vertical kernel to detect and save the vertical lines in a jpg
image_1 = cv2.erode(img_bin, ver_kernel, iterations=3)
vertical_lines = cv2.dilate(image_1, ver_kernel, iterations=5)
cv2.imwrite("/Users/marius/Desktop/vertical.jpg", vertical_lines)
# Plot the generated image
#cv2_imshow(image_1)
plt.title("image_1")
plt.imshow(image_1)
plt.show()
#cv2_imshow(vertical_lines)
plt.title("vertical_lines")
plt.imshow(vertical_lines)
plt.show()
# Use horizontal kernel to detect and save the horizontal lines in a jpg
image_2 = cv2.erode(img_bin, hor_kernel, iterations=3)
horizontal_lines = cv2.dilate(image_2, hor_kernel, iterations=5)
# Plot the generated image
#cv2_imshow(image_2)
plt.title("image_2")
plt.imshow(image_2)
plt.show()
#cv2_imshow(horizontal_lines)
plt.title("horizontal_lines")
plt.imshow(horizontal_lines)
plt.show()
# Combine horizontal and vertical lines in a new third image, with both having same weight.
img_vh = cv2.addWeighted(vertical_lines, 0.5, horizontal_lines, 0.5, 0.0)
#cv2_imshow(img_vh)
plt.title("img_vh")
plt.imshow(img_vh)
plt.show()
#cv2_imshow(~img_vh)
plt.title("~img_vh")
plt.imshow(~img_vh)
plt.show()
# Eroding and thesholding the image
img_vh = cv2.erode(~img_vh, kernel, iterations=2)
#cv2_imshow(img_vh)
plt.title("img_vh")
plt.imshow(img_vh)
plt.show()
thresh, img_vh = cv2.threshold(img_vh, 128, 255, cv2.THRESH_BINARY )
#cv2_imshow(img_vh)
plt.title("img_vh")
plt.imshow(img_vh)
plt.show()
bitxor = cv2.bitwise_xor(img, img_vh)
bitnot = cv2.bitwise_not(bitxor)
# Plotting the generated image
#cv2_imshow(bitnot)
plt.title("bitxor")
plt.imshow(bitxor)
plt.show()
plt.title("bitnot")
plt.imshow(bitnot)
plt.show()
# Detect contours for following box detection
# cv함수를 통해 Box의 외곽선 좌표값을 반환
contours, hierarchy = cv2.findContours(img_vh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
#print(contours)
#print(len(contours))
#print(contours[0])
#print(len(contours[0]))
#print(cv2.boundingRect(contours[0]))
def sort_contours(cnts, method="left-to-right"):
# initialize the reverse flag and sort index
reverse = False
i = 0
# handle if we need to sort in reverse
if method == "right-to-left" or method == "bottom-to-top":
reverse = True
# handle if we are sorting against the y-coordinate rather than
# the x-coordinate of the bounding box
if method == "top-to-bottom" or method == "bottom-to-top":
i = 1
# construct the list of bounding boxes and sort them from top to
# bottom
boundingBoxes = [cv2.boundingRect(c) for c in cnts]
(cnts, boundingBoxes) = zip(*sorted(zip(cnts, boundingBoxes),
key=lambda b: b[1][i], reverse=reverse))
# return the list of sorted contours and bounding boxes
return (cnts, boundingBoxes)
# Sort all the contours by top to bottom.
contours, boundingBoxes = sort_contours(contours, method="top-to-bottom")
# Creating a list of heights for all detected boxes
heights = [boundingBoxes[i][3] for i in range(len(boundingBoxes))]
# Get mean of heights
mean = np.mean(heights)
# Create list box to store all boxes in
box = []
# Get position (x,y), width and height for every contour and show the contour on image
#print("lencontours", len(contours))
for c in contours:
#x, y, w, h의 배열로 반환
x, y, w, h = cv2.boundingRect(c)
if (w < 0.9*img_width and h < 0.9*img_height):
image = cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
box.append([x, y, w, h])
#cv2_imshow(image)
plt.title("image")
plt.imshow(image)
plt.show()
# Creating two lists to define row and column in which cell is located
row = []
column = []
j = 0
#print("len box", len(box))
# Sorting the boxes to their respective row and column
for i in range(len(box)):
if (i == 0):
column.append(box[i])
previous = box[i]
else:
if (box[i][1] <= previous[1] + mean / 2):
column.append(box[i])
previous = box[i]
if (i == len(box) - 1):
row.append(column)
else:
row.append(column)
column = []
previous = box[i]
column.append(box[i])
#print(column)
#print(row)
# calculating maximum number of cells
countcol = 0
index = 0
for i in range(len(row)):
current = len(row[i])
if current > countcol:
countcol = current
index = i
#print("countcol", countcol)
# Retrieving the center of each column
#center = [int(row[i][j][0] + row[i][j][2] / 2) for j in range(len(row[i])) if row[0]]
center = [int(row[index][j][0] + row[index][j][2] / 2) for j in range(len(row[index]))]
#print("center",center)
center = np.array(center)
center.sort()
#print("center.sort()", center)
# Regarding the distance to the columns center, the boxes are arranged in respective order
finalboxes = []
for i in range(len(row)):
lis = []
for k in range(countcol):
lis.append([])
for j in range(len(row[i])):
diff = abs(center - (row[i][j][0] + row[i][j][2] / 4))
minimum = min(diff)
indexing = list(diff).index(minimum)
lis[indexing].append(row[i][j])
finalboxes.append(lis)
return finalboxes, img_bin
3.5 경계선이 없는 테이블
경계선이 있는 테이블에서는 kernel에 (1,n)과 같이 선을 추출 하였다면 경계선이 없는 테이블에서는 kernel = max(10,img_height // 25)와 같이 text가 포함되지 않는 가로와 세로의 빈 영역을 찾아 합치는 방식으로 테이블 cell을 찾게 된다. kernel이 다를 뿐 전반적인 흐름은 동일하다.
4. Inference 결과
import detectron2
import Multi_Type_TD_TSR.google_colab.deskew as deskew
import Multi_Type_TD_TSR.google_colab.table_detection as table_detection
import Multi_Type_TD_TSR.google_colab.table_structure_recognition_all as tsra
import Multi_Type_TD_TSR.google_colab.table_structure_recognition_lines as tsrl
#import Multi_Type_TD_TSR.google_colab.table_structure_recognition_wol as tsrwol
import Multi_Type_TD_TSR.google_colab.table_structure_recognition_lines_wol as tsrlwol
import Multi_Type_TD_TSR.google_colab.table_xml as txml
#import Multi_Type_TD_TSR.google_colab.table_xml_Copy1 as txml2
import Multi_Type_TD_TSR.google_colab.table_ocr as tocr
import pandas as pd
import os
import json
import itertools
import random
from detectron2.utils.logger import setup_logger
# import some common libraries
import numpy as np
import cv2
import matplotlib.pyplot as plt
# import some common detectron2 utilities
#from detectron2 import model_zoo
from detectron2.engine import DefaultPredictor
from detectron2.config import get_cfg
#from detectron2.utils.visualizer import Visualizer
#from detectron2.data import MetadataCatalog
#from detectron2.data import DatasetCatalog, MetadataCatalog
#from google.colab.patches import cv2_imshow
setup_logger()
#create detectron config
cfg = get_cfg()
#set yaml
cfg.merge_from_file('/home/hmjoe/Table_Structure_Recognition/Multi-Type-TD-TSR/All_X152.yaml')
#set model weights
cfg.MODEL.WEIGHTS = '/home/hmjoe/Table_Structure_Recognition/Multi-Type-TD-TSR/model_final.pth' # Set path model .pth
predictor = DefaultPredictor(cfg)
document_img = cv2.imread("/home/hmjoe/Table_Structure_Recognition/Multi-Type-TD-TSR/images/PMC4985124_5.jpg")
table_detection.plot_prediction(document_img, predictor)
list_table_boxes = []
for table in table_list:
finalboxes, output_img = tsrl.recognize_structure(table)
list_table_boxes.append(finalboxes)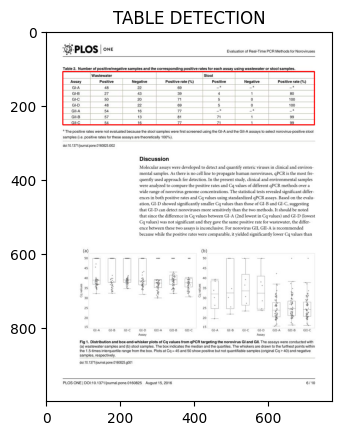
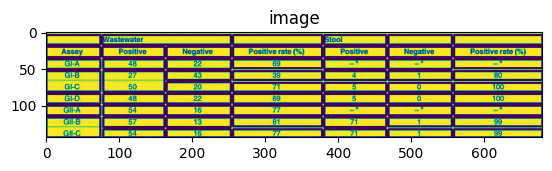
📗마치며
해당 알고리즘은 Table Detection 단계만 지나면 구조분석 시 GPU를 필요로 하지 않는다는 장점이 있다. 하지만 Inference 결과를 보면 모든 cell을 100% 탐지 하지 못했다.
이는 kernel사이즈를 수정하거나 erosion이나 dilation의 반복 횟수를 수정하여 보완할 수 있다.
따라서 해당 알고리즘을 잘 분석하여 커스터마이징 할 수 있다면 간단하지만 아주 강력한 테이블 구조분석이 가능할 것이라고 기대가 된다.
