📕서론
삼성 앨범 기능 중 이미지에서 글자 영역을 detect하여 인식 결과를 보여주는 기능이 있다. 이러한 OCR 기능을 구현 해보려고 한다.
- 문서OCR 순서
1. 이미지에서 글자 영역을 찾는다 (Craft 사용)
2. 탐색된 영역을 crop하여 recognition한다 (deep-text-recognition-benchmark 사용)
📕본론
1. Craft 사용
naver에서 제공해주는 Craft model을 통해 이미지에서 글자 영역을 detect한다.
https://paperswithcode.com/sota/scene-text-detection-on-icdar-2017-mlt-1
위 사이트는 'Scene Text Detection'의 명칭으로 영문, 한글, 숫자 등 문자가 포함된 공개된 데이터셋을 기준으로 여러 유저들이 테스트해보고 성능측정 결과를 공유한 목록이다. 이 중 Craft는 현재 기준 Precision: 80.6, Recall: 68.2로 8위에 올라와 있다.
높은 Score를 기록한 사이트가 많이 있지만 detect로 끝나는 것이 아니라 recognition까지 진행해야 하기 때문에 국내 기업에서 제공하는 사이트를 이용하는 것이 정보탐색에 용이할 것이라고 생각하여 naver의 오픈소스를 채택하였다.
2 Craft 논문 리뷰
👉논문
간단히 요약하면 단어수준의 영역 Box를 생성할 때 단어가 휘어있거나 변형되어 있는 경우 단일 Box로는 detect하는것이 어렵다. 이에 해결방안으로 단어 단위가 아닌 낱자 단위로 영역을 감지하고 각 낱자간의 자간이나 떨어진 정도를 바탕으로 Region Score와 Affinity Score를 구하여 하나의 단어로 연결시켜 단어 영역을 탐지하는 알고리즘이다.
📌Craft의 핵심 알고리즘
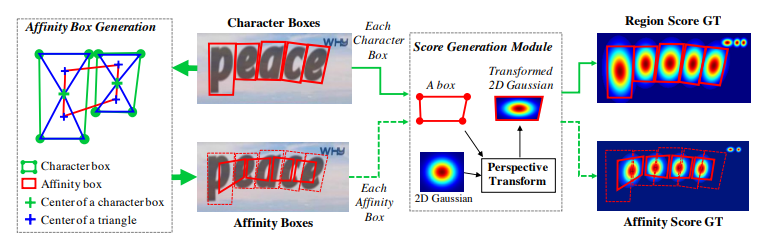
- Craft는 Word-Level(단어영역)을 바로 탐지하는 것이 아니라 Character-Level(낱자영역)의 조합을 통해 Word-Level Box를 유추하여 조합하는 방식이다.
- 문자의 위치를 찾는 Region Score와 문자간의 거리를 나타내는 Affinity Score를 예측한다.
- 예측한 각 낱자의 bbox를 그리고 이 상자에 맞춰 Gaussian map을 그린다. (Region Score Map)
- Affinity Score Map은 Region Score Map을 생성할 때 사용한 bbox를 사용한다.
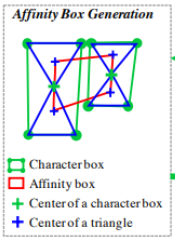
여기서 bbox의 대각선을 잇는 선을 그었을 때 삼각형이 4개가 생기는데 위쪽과 아래쪽 삼각형의 중심점이 생긴다. 이 때 인접한 두 box의 중심점을 이었을 때 생기는 박스가 Affinity Box이다. - 이 박스에 Gaussian Map을 그리면 Affinity Score Map이 된다.
- 이렇게 구한 Region Score와 Affinity Score를 조합하여 단어의 box를 그린다.
- 학습 데이터 구성 시 낱자 영역과 단어 영역에 대한 정보 둘 다 가지고 있어야 한다.
etc. Inference할 때 Affinity Score의 문자와 문자사이의 거리 정도를 나타내는 임계점을 조절하여 단어 box의 범위를 조절할 수 있다.
📌 Craft의 문제점
앞서 소개했던 공개 데이터는 Word-Level로 라벨이 되어있다. Craft는 Character-Level의 라벨이 필요하기 때문에 Ground Truth를 만드려면 너무 많은 비용이 요구된다. 이를 해결하기 위해 사전에 학습된 Interim model을 이용한다.
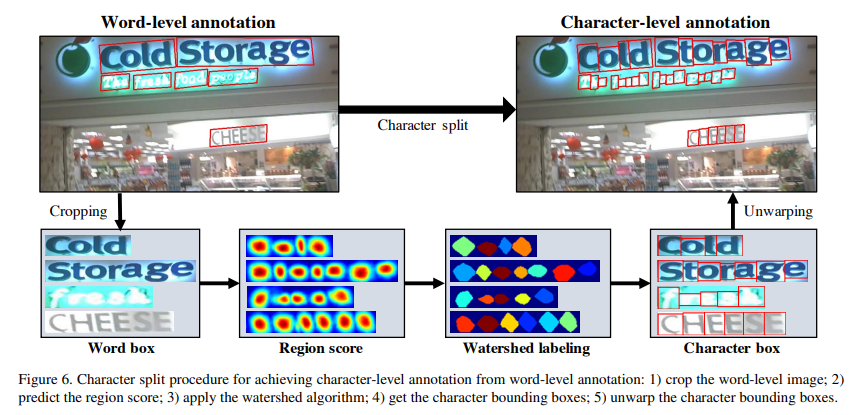
논문 내용은 다음과 같다.
1. Word-Level로 이미지를 crop한다.
2. Interim model을 통해 Region Score를 예측한다.
3. Watershed algorithm을 적용한다.
4. Character-Level의 bbox를 결정한다.
5. 기존의 Word-Level box를 결정된 Character-Level box로 대체한다.
이러한 방법으로 Character-Level의 Ground-Truth를 얻는 방법을 사용한다. 명확히 말하면 이는 Interim model을 통해 예측된 Groud-Truth이기 때문에 GT보다는 Pseudo-Ground-Truth(유사 정답)라고 칭한다.
그렇다면 Pseudo-Ground-Truth는 신뢰 할만한 Truth인가? 이러한 의문이 생긴다.
따라서 Pseudo-Ground-Truth의 Confidence Score를 계산해 가중치를 결정한다.
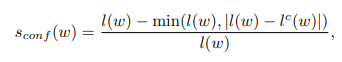

위의 이미지의 'ROBOTIC'이라는 단어가 실제길이 ℓ(w)=7 이지만 Interim model의 예측 결과인 =5 이고, 이므로 'ROBOTIC'이라는 word-box를 예측한 Pseudo-Ground-Truth의 Confidence Score는 이다.
이렇게 계산된 점수 Confidence Score값이 0.5보다 작아지는 경우에는 학습에 악영향을 끼칠 위험이 있으니 학습할 때 무시되어야 한다.
그래서 0.5보다 낮은 word-box에 대해서는 Interim model로 예측한 Character-box를 그대로 사용하는 것이 아니라 word-box를 ℓ(w)로 등분한다.
'ROBOTIC'박스를 예로 들면 해당 박스의 Confidence-Score가 0.5보다 낮을 경우 이 박스를 ℓ(w) 즉, 7로 등분하고 기존 Word-Level Box를 등분한 box로 대체하고 해당 박스의 Confidence-Score를 0.5로 설정한다.
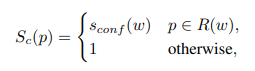
픽셀 p가 원본이미지 R(w)에 포함된다면 해당하는 Confidence-Map 좌표의 값을 Confidence-Score 즉, 로 설정하고 나머지 영역은 1로 설정한다.
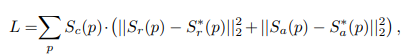
이렇게 만들어진 Confidence-Map은 학습시 Loss-Function 내에서 사용되며 각 word-box의 Confidence-Score에 비례하여 가중치가 결정된다.
3 Craft의 학습 과정 요약
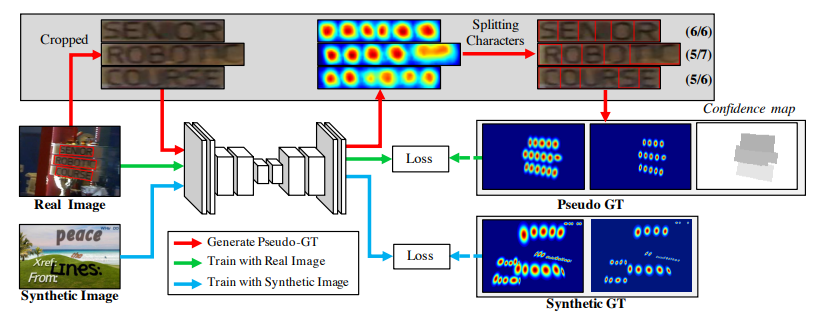
위의 내용들을 종합하여 Craft의 학습방법을 요약하면 다음과 같다.
1. Character-Level의 Groud-Truth를 통해 Interim model을 만들어 낸다.
2. Interim model을 개선하기 위해 Word-Level로 라벨링 되어있는 데이터를 통해 Pseudo-Ground Truth를 구한다.
3. Pseudo-Ground Truth의 신뢰성 문제가 있기 때문에 Confidence-Score를 계산하여 학습 시 가중치를 조절한다.
4. 최종적으로 Character-Level의 Ground-Truth와 Pseudo-Ground Truth로 학습을 진행한다.
- 마치며
위의 이미지에서 Synthetic Image란 Character-Lebel의 Ground-Truth가 포함된 데이터를 뜻하고 Real Image는 Word-Level의 Pseudo-Ground Truth가 포함된 데이터를 의미한다.
Pseudo-Ground Truth는 정확한 GT가 아니기 때문에 이러한 학습 방법을 weakly supervised learning라고 칭한다.
- 아쉬웠던 점
OCR 모델 구현할 때 손글씨와 인쇄체 모두 인식 가능하도록 하고싶었지만 Craft의 학습 방식으로는 손글씨에 대한 학습은 어려웠다.
낱자간의 특징이 명확하지 않고 각 낱자마다 분리가 안되고 이어져있는 경우가 많아 이러한 방식으로는 한계가 있었다.
그래서 손글씨 인식을 위해 다른 프레임워크와 알고리즘들을 찾아가며 진행 해 보았다.
이 내용은 추후 포스팅 하도록 하겠다.
출처
논문 : 네이버, Character Region Awareness for Text Detection
인용문 :
강준영, CRAFT 논문 리뷰 — Character Region Awareness for Text Detection
CV DOODLE, [논문 리뷰] Character Region Awareness for Text Detection / CRAFT / 텍스트 검출
