📕서론
deep-text-recognition-benchmark를 통해 OCR을 진행하기 전에 알면 좋은 기법들에 대해 알아보겠다.
1. CNN(Convolution Neural Network)
CNN은 Convolution Layer와 Pooling Layer를 통과하는 알고리즘으로 보통 classification(분류)모델을 만드는데 자주 사용된다.
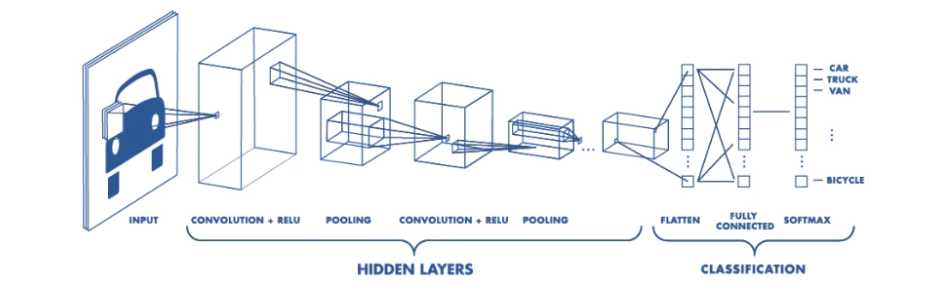
위 사진은 자동차라는 Input이 들어 왔을 때 이를 학습시키는 CNN의 과정이다.
- Convolution Layer
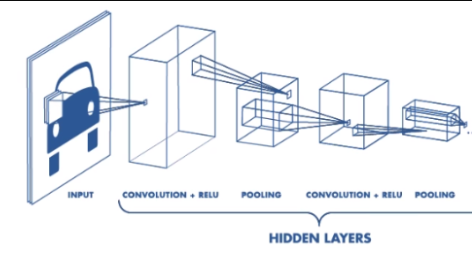
우선 Input이미지의 왼쪽 상단부터 오른쪽 하단 순서로 지정된 행렬의 크기만큼 추출한 뒤 여기에 합성곱을 계산한다. 예를들어 행렬 크기가 3x3이라고 가정하면 아래와 같다.
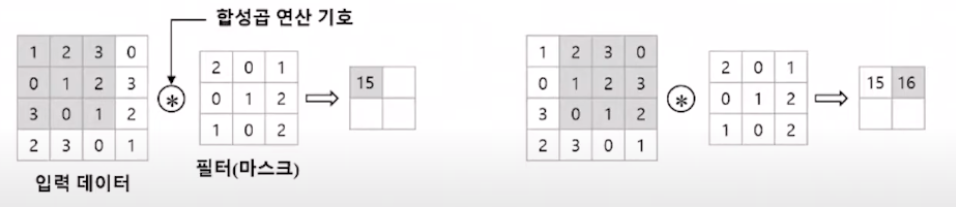
3x3 input 행렬에 3x3필터를 곱하여 계산한다. Input 이미지의 회색부분이 움직이는 간격을 Stride라고 하며, 위 예시는 Stride가 1인 경우이다.
그 후 RELU 활성화 함수를 곱해준다.
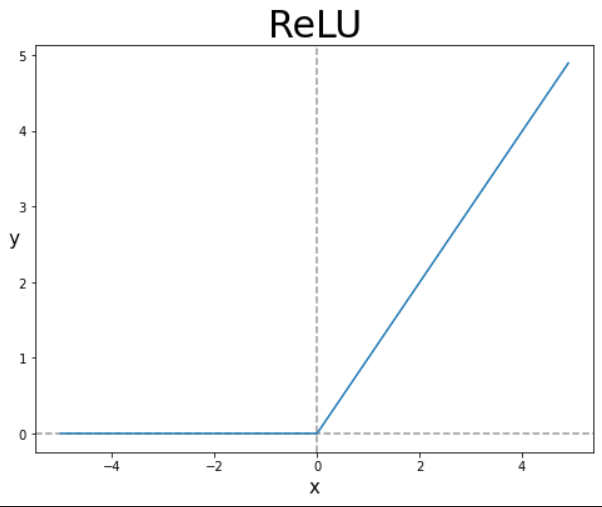
RELU활성화 함수는 특정 임계값 이하의 값은 0으로 하는 함수이다. 이 함수를 통과하여 음수와 0은 0으로 설정해준다.
- Pooling Layer
Pooling은 직역하면 자원이나 정보를 모은다, 집약한다 라는 의미이다. pooling은 MaxPooling과 AvgPooling이 있다.

위의 사진은 MaxPooling 방식으로 해당 영역에서 최대값을 불러와 집약하는 방식이다. AvgPooling 방식은 방식은 동일하지만 Max값이 아니라 평균값을 가져오는 방식이다.
추가로 설명하자면 보통 Convolution 단계에서 행렬이 지나치게 축소되는 것을 방지하기위해 행렬의 가장자리에 0으로된 zero padding을 추가한다.
- Fully Connected Layer
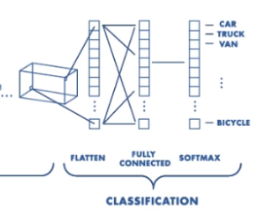
Convolution과 Pooling을 반복하여 나온 최종 행렬 (a, b)를 하나의 1차원 배열로 만드는 Flaten이 진행되는데 이 과정이 Fully Connected이다.
- SoftMax
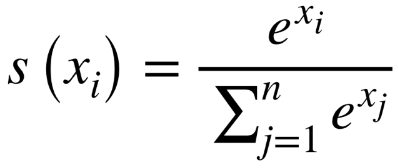
- = 입력값
- = 입력값의 합
Fully Connected Layer에서 만들어진 배열은 SoftMax 함수를 통해 확률 분포로 나타내게 된다. 결론적으로 자동차라는 Input이 있을 때 자동차일 확률, 고양이일 확률, 강아지일 확률....등 N개의 클래스에 대한 확률값이 나오고 각 클래스의 합은 1이다. 즉, 에 대한 확률이 나오고 이 값이 가장 높은 OutPut이 결정된다.
